本文主要是介绍LLM - SFT workflow 微调工作流程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

目录
一.引言
二.Workflow 分流程拆解
1. Workflow 代码
2.Workflow 拆解
◆ 超参数初始化
◆ 数据集初始化
◆ 加载与量化
◆ 数据集预处理
◆ DataCollator
◆ 模型微调 sft
三.总结
一.引言
前面我们对 LLM 相关流程的单步都做了分析与代码示例,下面结合代码将上述部分整理到一个 workflow 中,并给出框架中完整的 workflow 工作流,以供大家熟悉 LLM 训练过程的流程。
Tips:
本文数据集与代码主要参考 Github LLaMA-Efficient-Tuning。
二.Workflow 分流程拆解
1. Workflow 代码
这里只给出了 SFT 微调的 Workflow,更多完整代码可以参考引言中的 git 项目,或者代码顶部给出的 HF Transformer 的代码。
# Inspired by: https://github.com/huggingface/transformers/blob/v4.29.2/examples/pytorch/summarization/run_summarization.pyfrom typing import TYPE_CHECKING, Optional, List
from transformers import DataCollatorForSeq2Seq, Seq2SeqTrainingArgumentsfrom llmtuner.dsets import get_dataset, preprocess_dataset, split_dataset
from llmtuner.extras.constants import IGNORE_INDEX
from llmtuner.extras.misc import get_logits_processor
from llmtuner.extras.ploting import plot_loss
from llmtuner.tuner.core import load_model_and_tokenizer
from llmtuner.tuner.sft.metric import ComputeMetrics
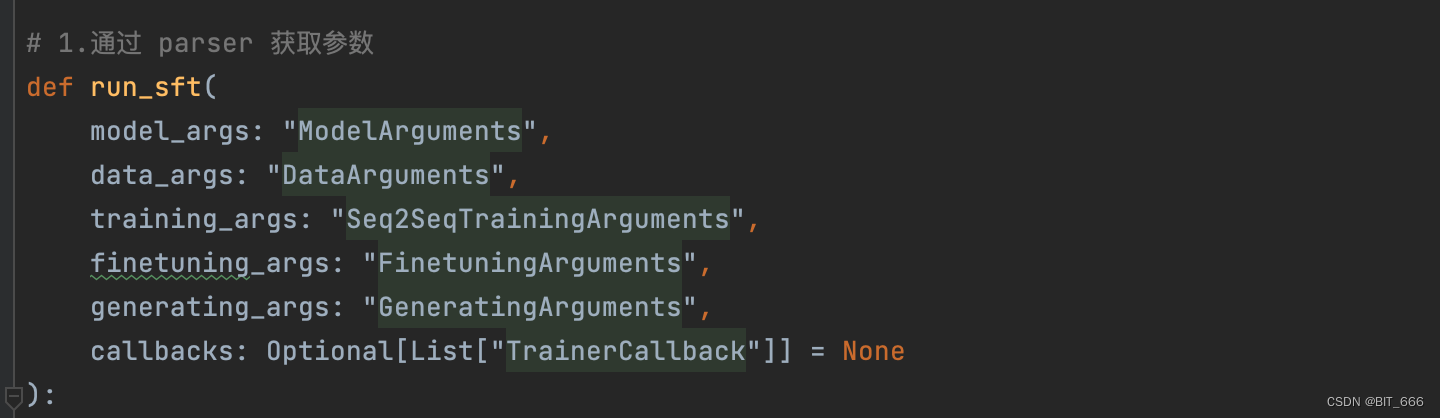
from llmtuner.tuner.sft.trainer import Seq2SeqPeftTrainerif TYPE_CHECKING:from transformers import TrainerCallbackfrom llmtuner.hparams import ModelArguments, DataArguments, FinetuningArguments, GeneratingArguments# 1.通过 parser 获取参数
def run_sft(model_args: "ModelArguments",data_args: "DataArguments",training_args: "Seq2SeqTrainingArguments",finetuning_args: "FinetuningArguments",generating_args: "GeneratingArguments",callbacks: Optional[List["TrainerCallback"]] = None
):# 2.Get Batch DataSetdataset = get_dataset(model_args, data_args)# 3.Load Lora Model And Bit or Notmodel, tokenizer = load_model_and_tokenizer(model_args, finetuning_args, training_args.do_train, stage="sft")# 4.Process Datasetdataset = preprocess_dataset(dataset, tokenizer, data_args, training_args, stage="sft")# 5.Data Collatordata_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer,label_pad_token_id=IGNORE_INDEX if data_args.ignore_pad_token_for_loss else tokenizer.pad_token_id)# 6.Training Args 转化# Override the decoding parameters of Seq2SeqTrainertraining_args_dict = training_args.to_dict()training_args_dict.update(dict(generation_max_length=training_args.generation_max_length or data_args.max_target_length,generation_num_beams=data_args.eval_num_beams or training_args.generation_num_beams))training_args = Seq2SeqTrainingArguments(**training_args_dict)# Initialize our Trainertrainer = Seq2SeqPeftTrainer(finetuning_args=finetuning_args,model=model,args=training_args,tokenizer=tokenizer,data_collator=data_collator,callbacks=callbacks,compute_metrics=ComputeMetrics(tokenizer) if training_args.predict_with_generate else None,**split_dataset(dataset, data_args, training_args))# Keyword arguments for `model.generate`gen_kwargs = generating_args.to_dict()gen_kwargs["eos_token_id"] = [tokenizer.eos_token_id] + tokenizer.additional_special_tokens_idsgen_kwargs["pad_token_id"] = tokenizer.pad_token_idgen_kwargs["logits_processor"] = get_logits_processor()# Trainingif training_args.do_train:train_result = trainer.train(resume_from_checkpoint=training_args.resume_from_checkpoint)trainer.log_metrics("train", train_result.metrics)trainer.save_metrics("train", train_result.metrics)trainer.save_state()trainer.save_model()if trainer.is_world_process_zero() and model_args.plot_loss:plot_loss(training_args.output_dir, keys=["loss", "eval_loss"])# Evaluationif training_args.do_eval:metrics = trainer.evaluate(metric_key_prefix="eval", **gen_kwargs)if training_args.predict_with_generate: # eval_loss will be wrong if predict_with_generate is enabledmetrics.pop("eval_loss", None)trainer.log_metrics("eval", metrics)trainer.save_metrics("eval", metrics)# Predictif training_args.do_predict:predict_results = trainer.predict(dataset, metric_key_prefix="predict", **gen_kwargs)if training_args.predict_with_generate: # predict_loss will be wrong if predict_with_generate is enabledpredict_results.metrics.pop("predict_loss", None)trainer.log_metrics("predict", predict_results.metrics)trainer.save_metrics("predict", predict_results.metrics)trainer.save_predictions(predict_results)
2.Workflow 拆解
◆ 超参数初始化
Model、Data、Training、Generate Agruments 超参解析![]() https://blog.csdn.net/BIT_666/article/details/132755841?spm=1001.2014.3001.5501
https://blog.csdn.net/BIT_666/article/details/132755841?spm=1001.2014.3001.5501
这里除了传递模型对应的地址或路径外,主要传递相关的训练参数、微调参数、生成参数等。
◆ 数据集初始化
批量加载 dataset 并合并![]() https://blog.csdn.net/BIT_666/article/details/132825731?spm=1001.2014.3001.5501
https://blog.csdn.net/BIT_666/article/details/132825731?spm=1001.2014.3001.5501

data_args 包含相关的 dataset 参数,我们这里加载 alpaca_data_zh_51k.json 数据集:

我们取前5行输出查看下 dataset:
def show(dataset):show_info = dataset.select(range(5))print(show_info)for row in show_info:print(row)
features 给出的列比较多,我们主要关注 prompt 提示词,query 问题与 response 回复即可。
◆ 加载与量化
Model Load_in_8bit or 4bit![]() https://blog.csdn.net/BIT_666/article/details/132490630?spm=1001.2014.3001.5501
https://blog.csdn.net/BIT_666/article/details/132490630?spm=1001.2014.3001.5501
![]()
这里函数具体逻辑可以参考前面给出的链接。主要负责从 model_args 获取模型参数,从 finetuning_args 获取微调相关参数,例如 lora_target、lora_rank 等。模型加载通过 HF 的 Auto 组件,Lora 模型通过 Peft 库实现。
Base Model For Baichuan:
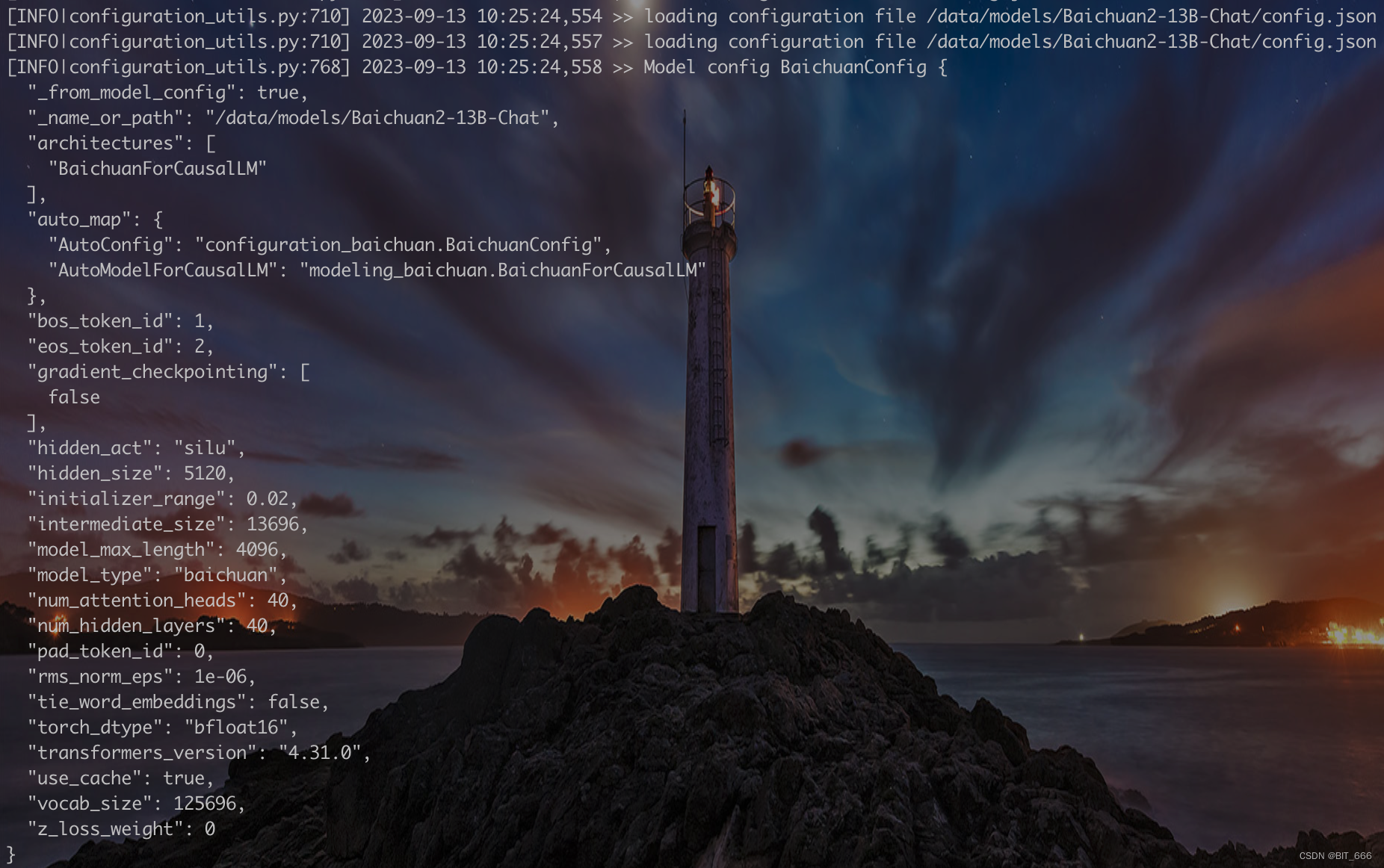
模型加载后打印的相关模型配置,可以看到模型类型,一些 Special Token Id 以及之前提到的 silu 激活函数等等。 这里我们没有用到量化的模型,不过新的 Baichuan2 提供了 8bit 和 4bit 的在线量化和离线量化方案供大家选择。
LoRA Info For Baichuan:

由于是 SFT 微调,所以通过 peft 增加了 LoRA 模块,这里 lora_target 为 'W_pack',也是打印出了我们微调参数量占总参数量的比例。
◆ 数据集预处理
Process Dataset For LLM With PT、SFT、RM![]() https://blog.csdn.net/BIT_666/article/details/132830908?spm=1001.2014.3001.5501
https://blog.csdn.net/BIT_666/article/details/132830908?spm=1001.2014.3001.5501
![]()
因为数据预处理需要对应模型的 tokenizer,所以需要先进行模型和 tokenizer 的加载, 这里我们最近的文章介绍了 SFT、PT、RM 三种模式数据集的处理方式,同样运行代码看看前5行数据经过 prepross 变成什么样:

处理后 dataset 只包含了 SFT 所需的相关内容,input_ids 为 input 对应的 token ids,这里 input 为 prompt + "\t" + query + response,labels 把除 response 外的部分都掩码掉。

以第一条记录为例,input_ids 为 prompt + query + response,label_ids 将对应的 token 用 -100 的 IGNORE_INDEX 替换,其对应的 token 为 <unk>,最后结尾处的 <s> 对应 token id 为 2,所以句子都以 2 结尾。
◆ DataCollator
DataCollator 样本生成![]() https://blog.csdn.net/BIT_666/article/details/131701620?spm=1001.2014.3001.5501
https://blog.csdn.net/BIT_666/article/details/131701620?spm=1001.2014.3001.5501

模型的 trainer 还需要 data_collator 生成对应的训练数据,这里指定了 Tokenizer 和对应的 pad_token_ids。
◆ 模型微调 sft
Baichuan7B Lora 训练详解![]() https://blog.csdn.net/BIT_666/article/details/131675165?spm=1001.2014.3001.5501
https://blog.csdn.net/BIT_666/article/details/131675165?spm=1001.2014.3001.5501

训练主要继承自 from transformers import Seq2SeqTrainer:
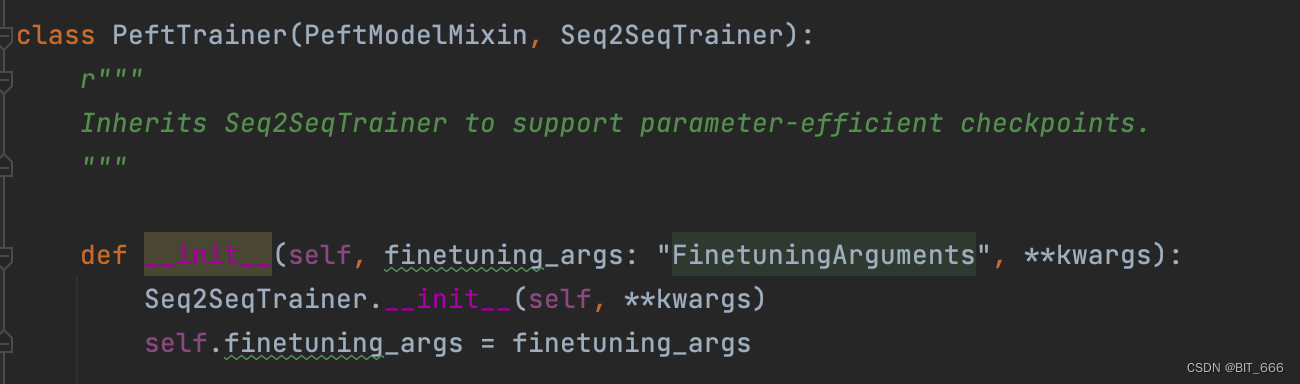
split_dataset 负责将数据集划分,分成 train 和 eval 部分:
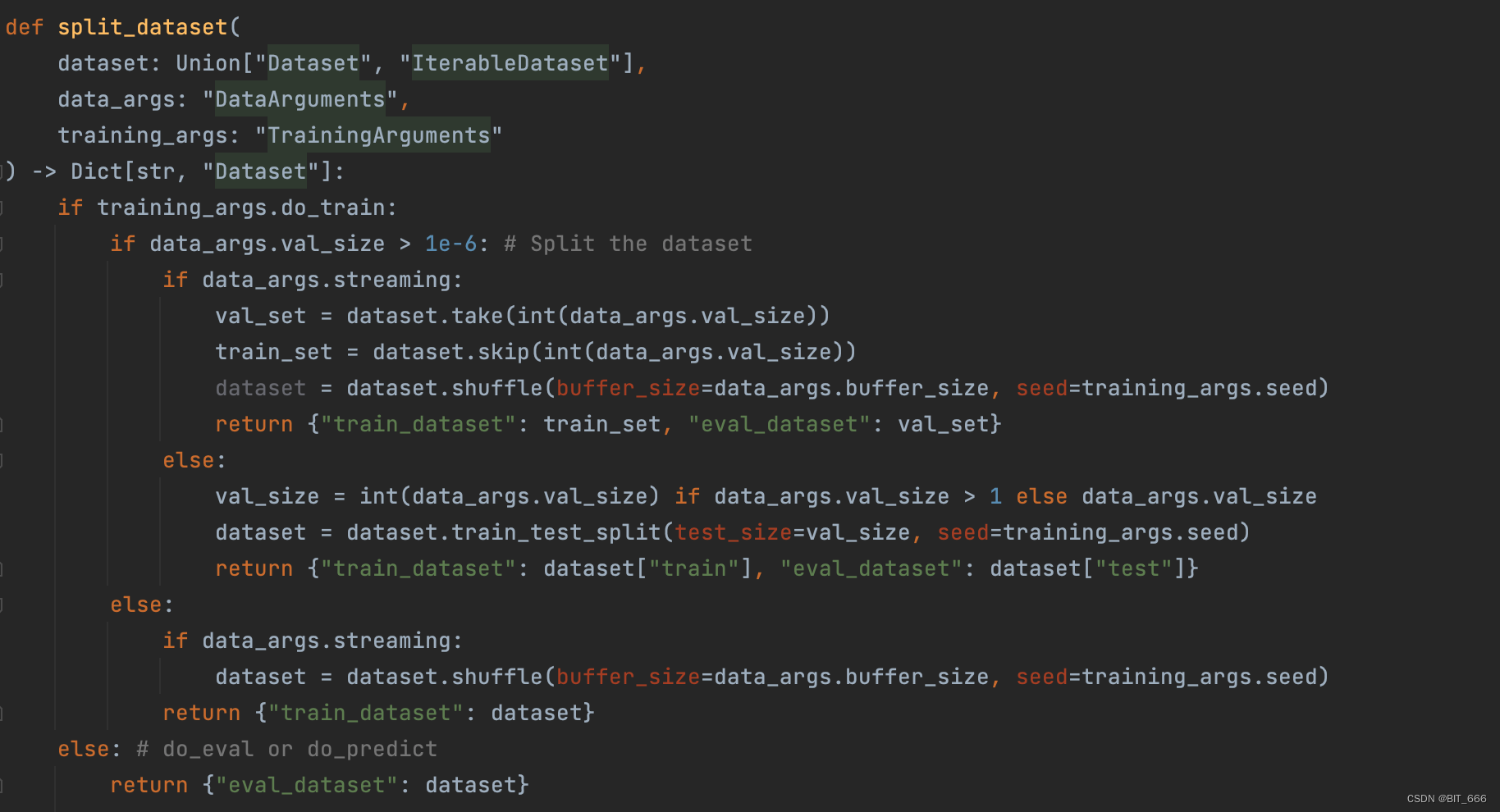
模型训练日志:
三.总结
做大模型就像过山车。觉得它很厉害,但看结构就是 Transformer 的堆叠;觉得它简单训练微调就行,但需要雄厚的实力和财力才能玩得起;workflow 的代码看起来逻辑很清晰,但其实里面又包含了很多的小细节值得学习。纠结的学习过程,且看且学。
这篇关于LLM - SFT workflow 微调工作流程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




