本文主要是介绍RandLA-Net: 大规模点云的高效语义分割(CVPR 2020) 牛津大学,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
RandLA-Net: 大规模点云的高效语义分割(CVPR 2020) 牛津大学
论文:RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds
代码:Github
相关网站
深蓝学院 基于三维点云场景的语义及实例分割 https://www.bilibili.com/video/BV1aE411T7Gf
-Introduction to point cloud segmentation
-RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds (CVPR 2020)
-Learning Object Bounding Boxes for 3D Instance Segmentation on Point Clouds (NeurIPS 2019)
作者主页 https://yang7879.github.io/
https://qingyonghu.github.io/
摘要
作者研究了大规模三维点云的有效语义分割问题。由于对计算资源消耗巨大的采样技术或计算繁重的前/后处理步骤,大多数现有方法只能在小规模点云上进行训练和操作。
在本文中,我们介绍了RandLA网络,一种高效轻量级的神经结构,用于直接推断大规模点云的逐点语义。我们的方法的关键是使用随机点采样,而不是更复杂的点选择方法。尽管计算和内存效率非常高,但随机抽样可以偶然丢弃关键特征。为了克服这一问题,我们引入了一种新的局部特征聚合模块,以逐步增加每个3D点的感受野,从而有效地保留几何细节。大量实验表明,我们的RandLA网络可以在一次过程中处理100万个点,比现有方法快200倍。此外,我们的RandLA网络在两个大规模基准Semantic3D和SemanticKITTI上明显超过了最先进的语义分割方法。
文章的主要工作
•分析和比较现有的采样方法,确定随机采样是大规模点云有效学习的最合适组件。
•提出了一个有效的局部特征聚合模块,通过逐步增加每个点的感受野来保持复杂的局部结构。
•baseline上展示了显著的内存和计算增益,并在多个大规模baseline上超过了最先进的语义分割方法。
RandLa—Net
大规模点云存在的问题
如图2所示,给定一个具有数百万个点、跨度达数百米的大规模点云,要使用深度神经网络对其进行处理,不可避免地需要在每个神经层中对这些点进行逐步有效的降采样,而不会丢失有用的点特征。在我们的RandLA网络中,我们使用简单快速的随机抽样方法来大大降低点密度,同时应用精心设计的局部特征聚合器来保留显著特征。这使得整个网络能够在效率和有效性之间实现出色的权衡
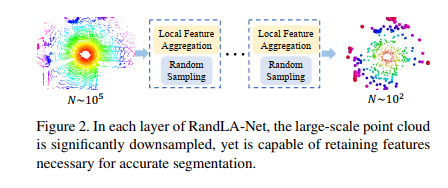
采样算法的选取
作者先对现有的点云降采样技术做了总结,大范围可以分为两类:Heuristic Sampling(启发式的)、Learning-based Sampling(可学习的)。
对于启发式的降采样:
Farthest Point Sampling(FPS):这是一种在点云领域被广泛使用的降采样方法,如PointNet系列。每次采样都去离采上一个点最远的点,迭代进行,这样可以把一些边边角角的点都能找到,但是算法计算复杂度O(N^2);
Inverse Density Importance Sampling (IDIS):先对每个点的密度进行排序,然后密集的部分多采样,稀疏的部分尽可能都保留。然而这种算法会容易受到噪声的影响,计算复杂度O(N);
Random Sampling (RS):随机采样,计算复杂度为O(1),与输入点数无关,当然可能会丢掉一些重要的点
对于可学习的降采样:
Generator-based Sampling (GS):算法通过学习来生成一个点云子集来实现降采样。这是很新颖的方法,然而这种方法可能比FPS方法的复杂度更高;
Continuous Relaxation based Sampling (CRS):通过学习一个矩阵,类似与实现一个全连接网络,然后和输入点云相乘得到输出的低维点云空间。然而当输入点数非常大的时候,矩阵需要的显存也将非常大;
Policy Gradient based Sampling (PGS):使用一个马尔科夫决策来对每一个点进行决策,决定其是否被保留。当输入点数很多的时候,其决策过程非常缓慢,搜索空间非常大,而且很容易不收敛。
通过以上的对比,最后作者认为也许随机采样才是最适合大场景的点云分割任务的。 作者:深蓝学院 https://www.bilibili.com/read/cv6886577/ 出处:bilibili
Local Feature Aggregation
然而,随机采样很容易去丢掉那些重要的点,我们该如何解决这个问题呢?作者提出了Local Feature Aggregation。这个Local Feature Aggregation主要包括三个子模块,分别是LocSE、Attentive Pooling、Dilated Residual Block。
整体的网络结构
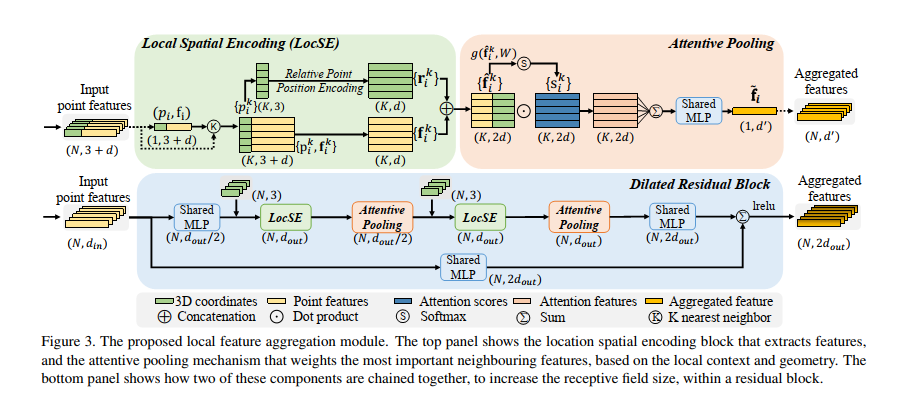
仔细看这个这个图,分为三个模块
LocSE 采用 k-nearst 方法求取局部的feature ,大多数的方法是把x,y,z坐标直接作为通道输入网络。
但受到论文 RSCNN Relation-Shape CNN for Point Cloud Analysis的启发,需要知道点云的位置相对关系,计算了相对位置与欧氏距离作为通道加入encoder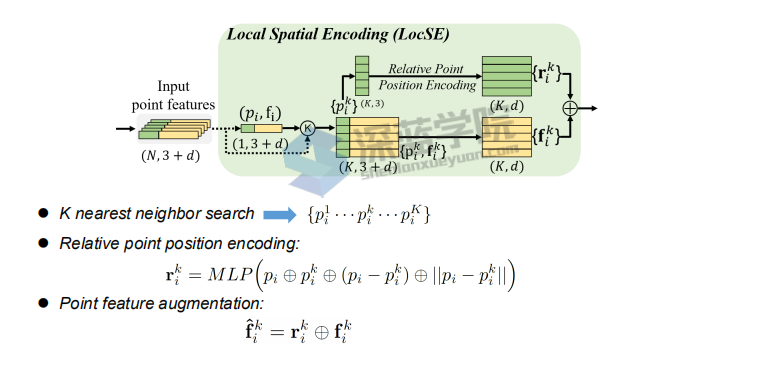
特征融合 attentive pooling 引入注意力机制Attention
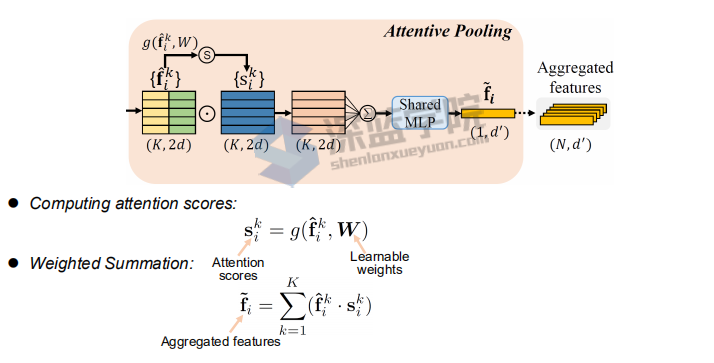
为了避免采样影响效果,引入感受野机制,更好的融合局部信息。
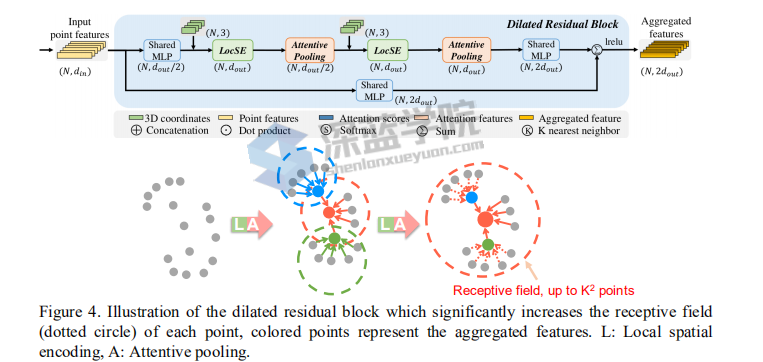
LocSE,即Local Spatial Encoding
该模块希望从输入点云里得到一个局部空间特征。步骤是先对于每一个点进行K近邻,找到它的邻域点集;然后将中心点的坐标、邻域点的坐标、邻域点和中心点的相对坐标和邻域点和中心点的欧式距离连在一起;再过一个MLP,和邻域点的特征在连在一起,得到最终输出。
Attentive pooling
将上面提取到的特征聚合在一起,PointNet系列一般都是直接一个Max Pooling,实现特征聚合。作者认为Max Pooling有些粗暴,容易丢掉一些重要的信息。作者使用Attention机制,在SeNet工作中提到过,学习一个MASK,来作为每个特征的权值,然后加权,再过一个MLP,实现聚合。
Dilated Residual Block
随机降采样不可避免会丢掉一些重要的点,如何解决这个问题,作者认为如果每个点的感受野足够大,其能够更好地聚合局部的特征,而且当这种感受野足够大时,即便有些点的特征被随机的丢掉了,但整个点云的大部分信息还是能够被有效地保留下来。因此我们将多个LocSE和Attentive Pooling模块连在一起,组成一个大的Dilated Residual Block。这样的话,输入点云通过不断的聚合,便增大了保留下点的视野。
基于上面的方法,作者设计了一个沙漏网络的结构,即点数先降低,再增加。每一层局部特征聚合和随机采样交替进行,点数下来了,每个点的视野也上去了。
作者:深蓝学院 https://www.bilibili.com/read/cv6886577/ 出处:bilibili
作者自己的讲解

首先 介绍一下3D点云的一些方法,
1) projected images:这是一种具有3D效果的2D图像,可以联想生活中一些3D绘画作品,虽然人可以感受到3D的效果,但是本质还是2D,计算机并不能识别其3D信息;
2) voxel grids:这是一种体素化的表达方式,体素是3D中的东西,对应到2D就是像素。在空间中用一个个小方块(体素)来对物体进行填充,便达到了3D的效果;
3) implicit surfaces:隐式曲面,计算机图形学中的概念,用数学函数形式来表达物体的表面形状;
4) mesh:用一系列的点和面将物体表面围起来,来表达3D信息;
5) point clouds:点云,一堆点的集合{(x1,y1,z1), (x2,y2,z2)……},当然每个点除了3个坐标也可能有其它属性,如RGD之类。
点云的很大的应用优势就是,可以实时被传感器测量出来、可以很紧凑的表示一个大规模场景的3D信息、可以非常好的表示物体的3D形状信息,对光照等外界因素并不敏感(因为是主动式的发射反射光信息,2D只是接受其它光源的反射光)。
当然,点云也有其不好处理的一面。点云是不规则的、不均匀的、无序的。虽然有这些缺点,但是其巨大的优点,让研究者们不断去想尽办法,寻找足够好的算法,去更好的处理点云。
点云处理的一些方法,同前面的Survey
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iUO71odW-1640937208689)(C:/Users/ASUS/AppData/Roaming/Typora/typora-user-images/image-20211119163150886.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-97zihi2P-1640937208691)(C:/Users/ASUS/AppData/Roaming/Typora/typora-user-images/image-20211119163229613.png)]
首先介绍下 voxel-based方法
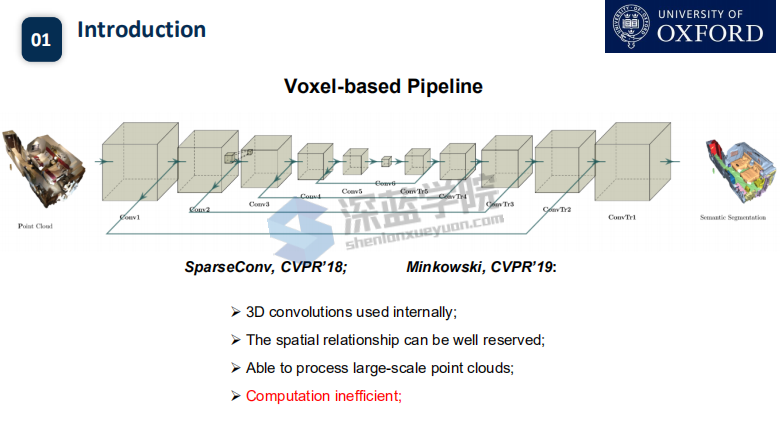
利用voxel方法,可以使得点的信息较为完整的保存下来,可以利用cnn等方法进行较好的识别
缺点是占用大量的计算资源
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gYtfOvcM-1640937208692)(C:/Users/ASUS/AppData/Roaming/Typora/typora-user-images/image-20211119195045083.png)]
point-based 也是以pointnet为例讲解,pointnet的想法是对每一个点进行fcn网络,然后利用一层一层的提取特征,最后利用max-pooling提取最大特征。pointnet的关键–globalfeature
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J1y8Kr1x-1640937208692)(C:/Users/ASUS/AppData/Roaming/Typora/typora-user-images/image-20211119195410247.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-E7Wfs6EY-1640937208693)(C:/Users/ASUS/AppData/Roaming/Typora/typora-user-images/image-20211119211352646.png)]
这里指出了voxel-based方法和Point-based的优缺点
显然,voxel-based方法牺牲了效率,增加了准确率 Point-based则相反
RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds (CVPR 2020) 大场景点云的分割
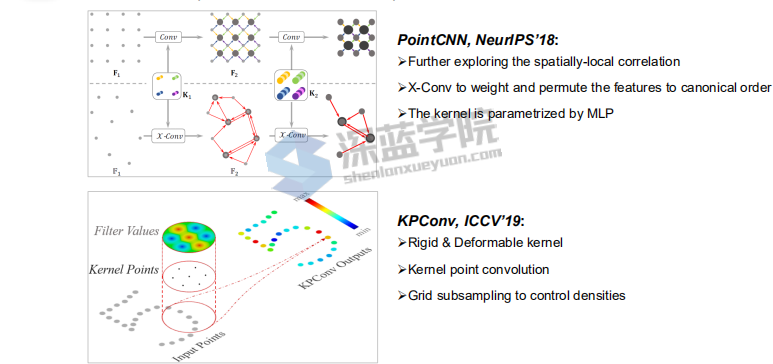
相关工作
Point Convolutions Methods方法
Pointcnn可以对点云进行convulsion同时可以对点云的顺序进行排序diordered–到ordered
Kpconv方法,针对pointnet 的kernel半径改变可能会使网络本身不稳定,KPconv通过mapping方法将点云映射到一个空间,可以实现较为稳定的核来进行学习

其他大场景点云的工作
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Rghlte4E-1640937208694)(C:/Users/ASUS/AppData/Roaming/Typora/typora-user-images/image-20211119200352010.png)]
Motivation目前的方法都是针对小点云块,没有针对大场景的分割效果
研究发现,pointnet在尺度越大效果越差,原因是pointnet只是对所有的点进行FCN,仅仅通过max-pooling损失了很多的特征。pointnet++学习了点的和周围的关系,在分割的效果逐步提升,但是时间复杂度却非常高,一直增大
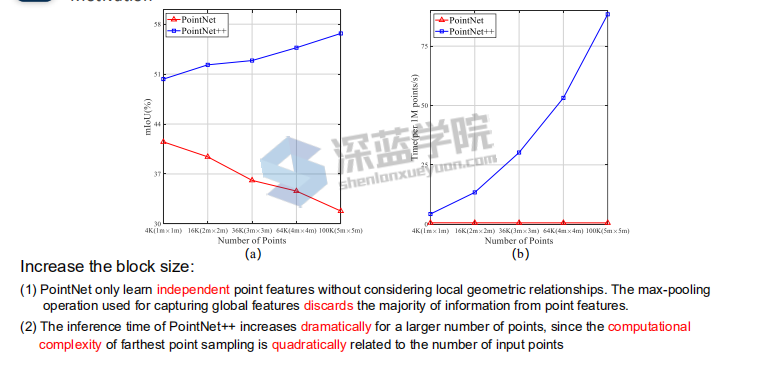
作者先简单介绍了两篇前人的工作,PointCNN和KPConv,这两篇论文并不是做大场景的,但是它们提出的想法是基础性的,就是自定义卷积,通过自定义的卷积在点云上进行操作,可以提取更好的特征。在大场景领域,作者也简单提了两篇工作,SPG和FCPN。SPG为整个场景的点云构建了一个超点图,边信息表征了点云内在的关联,然后在graph上进行操作。FCPN是结合了point-based和voxel-based,将无规则的点云,转换为内部有序的数据结构,然后再使用3D卷积进行处理。作者提到之前做大场景的工作,处理起来都非常耗时,因此RandLA-Net工作motivation便有了。那现有的方法,比如pointnet和pointnet++能直接迁移到大场景领域吗?作者做了相关实验,首先pointnet是直接用max pooling来取得全局特征,局部特征的提取是缺失的。随着切块的块越来越大,直接max pooling,必然会损失很多信息,因此pointnet的性能会越来越低。那结合了局部特征的pointnet++呢?通过实验,我们发现随着块的变大,性能也在变好。然而耗时也越来越严重,因为pointnet++中使用的点集的降采样算法,是和点数的二次方成正比的,块越大,点数越多,速度越慢。
作者:深蓝学院 https://www.bilibili.com/read/cv6886577/ 出处:bilibili
那么大场景点云语义分割领域的难点在哪?作者提了三点,首先是整体的点云相比于一个小块的点云的结构要复杂很多;其次是点数的增多势必会带来GPU显存的上升;最后是传感器采集到的点云数是非固定的,之前都是切块后再采固定数量的点。
作者希望能找到一个符合以下三点的大场景处理方法:1)不用切块,直接全局输入;2)计算复杂度和显存占用要低;3)还要保证精度和能够自适应输入点数。作者希望能找到一个符合以下三点的大场景处理方法:1)不用切块,直接全局输入;2)计算复杂度和显存占用要低;3)还要保证精度和能够自适应输入点数。
对于大场景的点云,如何直接处理呢?一个核心的步骤就是降采样。作者认为我们需要一个更有效的降采样算法,来保留点云的key points。同时还希望能够有一种更好的局部特征提取和聚合的算法来学到局部特征。
作者先对现有的点云降采样技术做了总结,大范围可以分为两类:Heuristic Sampling(启发式的)、Learning-based Sampling(可学习的)。对于启发式的降采样:Farthest Point Sampling(FPS):这是一种在点云领域被广泛使用的降采样方法,如PointNet系列。每次采样都去离采上一个点最远的点,迭代进行,这样可以把一些边边角角的点都能找到,但是算法计算复杂度O(N^2);Inverse Density Importance Sampling (IDIS):先对每个点的密度进行排序,然后密集的部分多采样,稀疏的部分尽可能都保留。然而这种算法会容易受到噪声的影响,计算复杂度O(N);Random Sampling (RS):随机采样,计算复杂度为O(1),与输入点数无关,当然可能会丢掉一些重要的点对于可学习的降采样:Generator-based Sampling (GS):算法通过学习来生成一个点云子集来实现降采样。这是很新颖的方法,然而这种方法可能比FPS方法的复杂度更高;Continuous Relaxation based Sampling (CRS):通过学习一个矩阵,类似与实现一个全连接网络,然后和输入点云相乘得到输出的低维点云空间。然而当输入点数非常大的时候,矩阵需要的显存也将非常大;Policy Gradient based Sampling (PGS):使用一个马尔科夫决策来对每一个点进行决策,决定其是否被保留。当输入点数很多的时候,其决策过程非常缓慢,搜索空间非常大,而且很容易不收敛。通过以上的对比,最后作者认为也许随机采样才是最适合大场景的点云分割任务的。然而,随机采样很容易去丢掉那些重要的点,我们该如何解决这个问题呢?作者提出了Local Feature Aggregation。这个Local Feature Aggregation主要包括三个子模块,分别是LocSE、Attentive Pooling、Dilated Residual Block。 作者:深蓝学院 https://www.bilibili.com/read/cv6886577/ 出处:bilibili
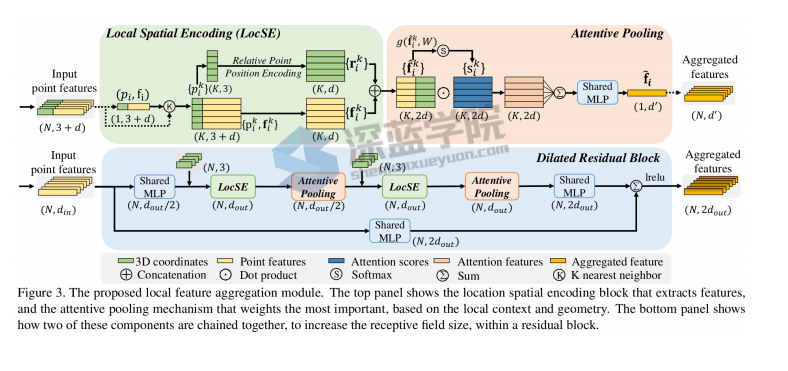
仔细看这个这个图,分为三个模块
LocSE 采用 k-nearst 方法求取局部的feature ,大多数的方法是把x,y,z坐标直接作为通道输入网络。
但受到论文 RSCNN Relation-Shape CNN for Point Cloud Analysis的启发,需要知道点云的位置相对关系,计算了相对位置与欧氏距离作为通道加入encoder
特征融合 attentive pooling 引入注意力机制Attention
为了避免采样影响效果,引入感受野机制,更好的融合局部信息。
LocSE,即Local Spatial Encoding该模块希望从输入点云里得到一个局部空间特征。步骤是先对于每一个点进行K近邻,找到它的邻域点集;然后将中心点的坐标、邻域点的坐标、邻域点和中心点的相对坐标和邻域点和中心点的欧式距离连在一起;再过一个MLP,和邻域点的特征在连在一起,得到最终输出。Attentive pooling将上面提取到的特征聚合在一起,PointNet系列一般都是直接一个Max Pooling,实现特征聚合。作者认为Max Pooling有些粗暴,容易丢掉一些重要的信息。作者使用Attention机制,在SeNet工作中提到过,学习一个MASK,来作为每个特征的权值,然后加权,再过一个MLP,实现聚合。Dilated Residual Block随机降采样不可避免会丢掉一些重要的点,如何解决这个问题,作者认为如果每个点的感受野足够大,其能够更好地聚合局部的特征,而且当这种感受野足够大时,即便有些点的特征被随机的丢掉了,但整个点云的大部分信息还是能够被有效地保留下来。因此我们将多个LocSE和Attentive Pooling模块连在一起,组成一个大的Dilated Residual Block。这样的话,输入点云通过不断的聚合,便增大了保留下点的视野。基于上面的方法,作者设计了一个沙漏网络的结构,即点数先降低,再增加。每一层局部特征聚合和随机采样交替进行,点数下来了,每个点的视野也上去了。通过实验,作者发现随机采样方法,无论是从速度还是显存,都是对比最优的,整体方法的效率,在大场景领域对比也是速度最快。再看精度,在Semantic3D、SemanticKITTI和S3DIS上,作者的方法也取得的非常好的效果。 作者:深蓝学院 https://www.bilibili.com/read/cv6886577/ 出处:bilibili
这篇关于RandLA-Net: 大规模点云的高效语义分割(CVPR 2020) 牛津大学的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



