本文主要是介绍郭健:deadline调度器之(一):原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、概述
实时系统是这样的一种计算系统:当事件发生后,它必须在确定的时间范围内做出响应。在实时系统中,产生正确的结果不仅依赖于系统正确的逻辑动作,而且依赖于逻辑动作的时序。换句话说,当系统收到某个请求,会做出相应的动作以响应该请求,想要保证正确地响应该请求,一方面逻辑结果要正确,更重要的是需要在最后期限(deadline)内作出响应。如果系统未能在最后期限内进行响应,那么该系统就会产生错误或者缺陷。在多任务操作系统中(如Linux),实时调度器(realtime scheduler)负责协调实时任务对CPU的访问,以确保系统中的所有的实时任务在其deadline内完成。
如果对实时任务进行抽象,那么它需要三个元素:周期(period),运行时间(runtime)和最后期限(deadline)。Deadline调度器正是利用了这一点(指对实时任务完美的抽象),允许用户来指定该任务的具体需求,从而使系统能够做出最好的调度决策,即使在负载很高的系统中也能保证实时任务的调度。
二、Linux系统中的实时调度器
实时任务和非实时任务(或者普通任务)的区别是什么?实时任务有deadline,超过deadline,将不能产生正确的逻辑结果,非实时任务则没有这个限制。为了满足实时任务的调度需求,Linux提供了两种实时调度器:POSIX realtime scheduler(后文简称RT调度器)和deadline scheduler(后文简称DL调度器)。
RT调度器有两种调度策略:FIFO(first-in-first-out)和RR(round-robin)。无论FIFO还是RR,RT调度器都是根据任务的实时优先级(Linux进程描述符中的rt_priority成员)进行调度。最高优先级的任务将最先获得CPU资源。在实时理论中,这种调度器被归类为固定优先级调度器(fixed-priority scheduler,即每一个rt任务都固定分配一个优先级)。当实时优先级不同的时候,FIFO和RR没有什么不同,只有在两个任务具有相同优先级的时候,我们才可以看出FIFO和RR之间的区别。对于FIFO调度器,最先进入runnable状态的任务将首先获取CPU资源,并且一直占用该资源,直到该进程进入睡眠状态。而对于RR调度器,具有相同优先级的任务将以轮流执行的方式共享处理器资源。当某个RR任务开始运行后,如果该任务不会阻塞,那么它将一直运行,直到分配给该任务的时间片到期。当时间片用完,调度器将把该任务放在任务链表的末端(注意,只有相同优先级的任务才会放到一个链表中,不同优先级在不同的链表中),并从任务链表中选择下一个任务去执行。
和RT调度器不同,DL调度器是按照任务的deadline进行调度的(从名字也看的出来,哈哈)。当产生一个调度点的时候,DL调度器总是选择其Deadline距离当前时间点最近的那个任务并调度它执行。调度器总是根据任务的配置参数进行调度,对于RT调度器而言,用户需要配置任务的调度策略(FIFO或者RR)和那个固定的实时优先级。例如:
chrt -f 10 video_processing_tool
通过上面的命令,video_processing_tool任务会归于RT调度器管理,其实时优先级是10,调度策略是FIFO(-f参数)
对于DL调度器,用户需要设定三个参数:周期(period)、运行时间(runtime)和最后期限(deadline)。周期和该实时任务的工作模式相关。例如:对于一个视频处理任务,它的主要的工作是每秒钟处理60帧的视频数据,即每16毫秒需要处理每一帧视频,因此,该任务的周期就是16ms。
对于实时任务,一个周期内总是有固定的“工作”要做,例如在视频任务中,所谓的工作就是对一帧视频数据进行处理,Runtime是完成这些“工作”需要的CPU执行时间,即在一个周期中,需要CPU参与运算的时间值。在设定运行时间参数的时候我们不能太乐观,runtime在设定的时候必须考虑最坏情况下的执行时间(worst-case execution time ,WCET)。例如,在视频处理中,各个帧的情况可能不太一样(一方面帧间的相关性不同,另外,即便是针对一帧数据,其图像像素之间的相关性也不同),有些会耗时长一些,有些会短一些。如果处理时间最长的那帧视频需要5毫秒来处理,那么它的runtime设定就是五毫秒。
最后我们来说说Deadline参数。在一个实时任务的工作周期内,deadline定义了处理完成的结果必须被交付的最后期限。我们还是以上面的视频处理任务为例,在一个视频帧的处理周期中(16ms),如果该任务需要在该周期的前10毫秒内把处理过的视频帧传送给下一个模块,那么deadline参数就是10毫秒。为了达到这个要求,显然在该周期的前10ms就必须完成一帧数据的处理,即5ms的runtime必须位于该周期的前10ms时间范围内。
通过chrt命令我们可以设定deadline调度参数,例如:上面的视频任务可以这样设定:
chrt -d --sched-runtime 5000000 --sched-deadline 10000000 \
--sched-period 16666666 0 video_processing_tool
其中“-d”参数说明设定的调度策略是deadline,“--sched-runtime 5000000”是将运行时间参数设定为5ms,“--sched-deadline 10000000”是将deadline设定为10ms,“--sched-period 16666666”则是设定周期参数。命令行中的“0”是优先级占位符,DL调度器并不使用优先级参数。
通过上面的设定,我们可以确保每16ms的周期内,DL调度器会分配给该任务5ms的CPU运行时间,而且这个5ms的CPU时间会保证在10ms内的deadline之前配备给该任务,以便该任务完成处理并交付给下一个任务或者软件模块。
Deadline的参数看似复杂,其实简单,因为只要知道了task的行为,就可以推断出其调度参数并进行设定。也就是说deadline任务的调度参数只和自己相关,和系统无关。RT task则不然,它需要综合整个系统来看,把适合的rt priority配置给系统中的各个rt task,以确保整个系统能正常的运作(即在deadline之前,完成各个rt task的调度执行)。
由于deadline任务明确的告知了调度器自己对CPU资源的需求,因此,当一个新的deadline task被创建,进入系统的时候,DL调度器可以知道CPU是否可以承担这个新创建的DL task。如果系统比较空闲(DL任务不多),那么可以该task进入调度,如果系统DL任务已经很多,新加入的DL任务已经导致CPU利用率超过100%,那么DL调度器会将其拒之门外。一旦DL任务被接纳,那么DL调度器则可以确保该DL task可以按照其调度参数的要求正确的执行。
为了进一步讨论DL调度器的好处,我们有必要后退一步,看看实时调度的蓝图。因此,下一节我们将描述一些实时调度的理论知识。
三、实时调度概述
在调度理论中,怎么来评估实时调度器的性能呢?具体的方法就是创建一组实时任务(后文称之实时任务集)让调度器来调度执行,看看是否能够完美的调度任务集中的所有任务,即所有实时任务的时间要求(deadline)都可以得到满足。为了能够在确定的时间内响应请求,实时任务必须在确定的时间点内完成某些动作。为此,我们需要对实时任务进行抽象,总结出其任务模型来描述这些动作确定性的时序。
每个实时任务都有N个不断重复的“工作”(job)组成,如果一个rt task所进行的工作总是在固定的时间间隔内到来,那么我们成该任务是周期性的(Periodic)。例如一个音频处理程序每隔20ms就会对一帧音频数据进行压缩。任务也可以是零散到来的(sporadic),sporadic task类似periodic task,只不过对周期要求没有那么严格。对于sporadic task而言,它只定义了一个最小的时间间隔。假如这个最小时间间隔是20ms,那么job可能在距离上一次20ms后到来,也可能30ms到来,但是不会小于20ms。最后一种是非周期任务,没有任何固定的模式。
上一段总结了实时任务的工作模式,下面我们看看deadline的分类。一个实时任务的Deadline有三种:第一种是隐含性的deadline(implicit deadline),即并不明确的定义deadline,其值等于period参数。这一种实时任务对时间要求相对比较低,只要在该周期内分配了runtime的CPU资源即可。第二种是受限型deadline(constrained deadline),即deadline小于(或者等于)period参数,这种实时任务对时间的要求高一些,需要在周期结束之前的某个时间范围内分配CPU资源。最后一种是arbitrary deadline:即deadline和周期没有关系。
根据抽象出来的任务模式,实时研究人员已经开发出一种评估调度算法优劣的方法:首先给定一组任务(包括了各种各样前面描述的实时任务类型),让被测试的调度器去调度这一组任务,以此来评估该调度器的调度能力。结果表明,在单处理器系统中,采用Early Deadline First(EDF)算法的调度器被认为是最佳的。之所以说它是最好的,言外之意就是当该调度器无法完成某个任务集调度的时候,其他调度器也无能为力。当在单处理器系统上调度periodic 和sporadic任务,并且deadline总是小于或等于周期参数(也就是constrained deadline)的时候,基于deadline参数进行调度的调度器性能优异,表现最佳。实际上,对于那些deadline等于period参数(即implicit deadline)的periodic或者sporadic tasks,只要被调度的那组任务不使用超过100%的CPU时间,那么EDF调度器都可以正常的完成调度,满足每一个rt task的deadline要求。Linux DL调度器实现了EDF算法。
我们举一个实际的例子,假设系统中有三个周期性任务,参数如下(deadline等于period):
| Task | Runtime(WCET) | Period |
| T1 | 1 | 4 |
| T2 | 2 | 6 |
| T3 | 3 | 8 |
这三个任务对 CPU时间的利用率还没有达到100%:CPU利用率 = 1/4 + 2/6 + 3/8 = 23/24
对于这样的一组实时任务,EDF调度器的调度行为如下图所示:
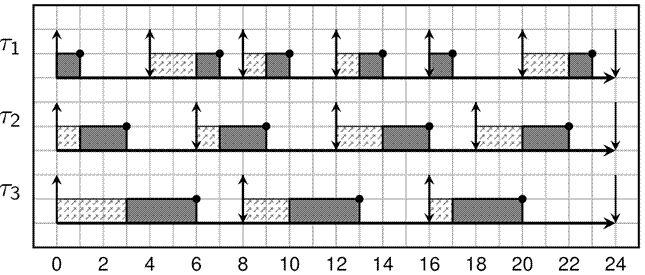
通过上图可知3个rt任务都很好的被调度,满足了各自的deadline需求。如果使用固定优先级的调度器(例如Linux内核中的FIFO)会怎样呢?其实不管如何调整各个rt task的优先级,都不能很好的满足每个任务的deadline要求,总会有一个任务的Job会在deadline之后完成,具体参考下面的图片:

基于deadline的调度算法最大的好处是:一旦知道了一个实时任务集中每个任务的调度参数,其实根本不需要分析其他任务,你也能知道该实时任务集是否能在deadline之前完成。在单处理器系统,基于deadline进行调度所产生的上下文切换次数往往会比较少。此外,在保证每个任务都满足其deadline需求的条件下,基于deadline的调度算法可以调度的任务数目比固定优先级的调度算法要多。当然,基于deadline参数进行调度的调度器(后面简称deadline调度器)也有一些缺点。
deadline调度器虽然可以保证每个RT任务在deadline之前完成,但是并不能保证每一个任务的最小响应时间。对于那些基于固定优先级的进行调度的调度器(后文简称priority调度器),高优先级的任务总是有最小的响应延迟时间。EDF调度算法的priority调度算法要复杂一些。priority调度算法的复杂度可以是O(1)(例如Linux中的RT调度器),相比之下,deadline调度器的复杂度是O(log(n))(例如Linux中的DL调度器)。不过priority调度器需要为每一个task选择一个最适合的优先级,这个最优优先级的计算过程可能是离线的,这个算法的复杂度是O(N!)。
如果系统出于某种原因发生过载,例如由于新任务添加或错误的估计了WCET,这时候,deadline调度有可能会有一个多米诺效应:当一个任务出现问题,影响的并非仅仅是该任务,这个问题会扩散到系统中的其他任务上去。我们考虑这样的场景,由于运行时间超过了其runtime参数指定的时间,调度器在deadline之后才完成job,并交付给其他任务,这个issue很影响系统中所有其他的任务,从而导致其他任务也可能会错过deadline,如下面的区域所示:
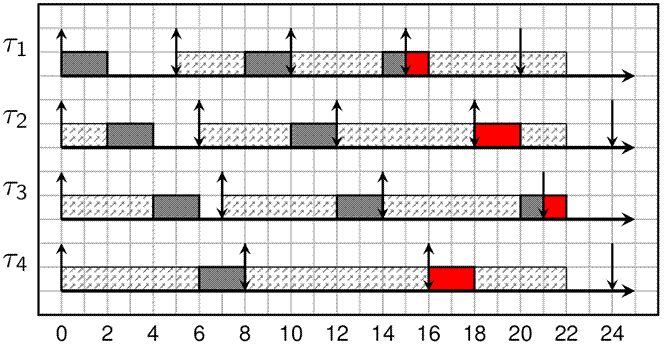
而对于那些基于固定优先级的调度算法则相反,当一个任务出问题的时候,受影响的只是那个优先级最低的task。(顺便说一句:在linux中,DL调度器中实现了CBS,从而解决了多米诺效应,下一篇文档会详述。)
在单核系统中,调度器只需要考虑任务执行先后顺序的问题,在多核系统中,除了任务先后问题,调度器还需要考虑CPU分配问题。也就是说,在多核系统中,调度器还需要决定任务在那个CPU上运行。一般来说,调度器可以被划分为以下几类:
(1)全局类(Global):即一个调度器就可以管理系统中的所有CPU,任务可以在CPU之间自由迁移。
(2)集群类(Clustered):系统中的CPU被分成互不相交的几个cluster,调度器负责调度任务到cluster内的CPU上去。
(3)分区类(Partitioned ):每个调度器只管自己的那个CPU,系统有多少个CPU就有多少个调度器实体。
(4)任意类(Arbitrary ):每一个任务都可以运行在任何一个CPU集合上。

对于partitioned deadline调度器而言,多核系统中的调度其实就被严格分解成一个个的单核deadline调度过程。也就是说,partitioned deadline调度器的性能是最优的。不过,多核系统中的global、clustered和arbitrary deadline调度器并非最优。例如,在一个有M个处理器的系统中,如果有M个runtime等于period参数的实时任务需要调度,调度器很容易处理,每个CPU处理一个任务即可。我们可以进一步具体化,假设有四个“大活”,runtime和period都是1000ms,一个拥有四个处理器的系统可以分别执行这四个“大活”,在这样的场景下,CPU利用率是400%:
4 * 1000/1000 = 4
调度的结果如下图所示:

在这么重的负载下,调度器都能工作起来,每个“大活”的deadline都得到满足。当系统的负载比较轻的情况下,我们直觉就认为调度器也应该能hold住场面。下面我们构造一个轻负载:调度器要面对的是4个“小活”和一个“大活”,“小活”的runtime是1ms,周期是999ms,“大活”同上。在这种场景下,系统的CPU利用率是100.4%:
4 * (1/999) + 1000/1000 = 1.004
1.004是远远小于4的,因此,我们直观上感觉调度器是可以很好的调度这个“4小一大”的调度场景的。然而实时并非如此,单核上表现最优的EDF调度器,在多核系统中会出现问题(指Global EDF调度器)。具体原因是这样的:如果所有任务同时释放,4个小活(deadline比较早)将会被调度在4个CPU上,这时候,“大活”只能在“小活”运行完毕之后才开始执行,因此“大活”的deadline不能得到满足。如下图所示。这就是众所周知的Dhall效应(Dhall's effect)。

把若干个任务分配给若干个处理器执行其实是一个NP-hard问题(本质上是一个装箱问题),由于各种异常场景,很难说一个调度算法会优于任何其他的算法。有了这样的背景知识,我们就可以进一步解析Linux内核中的DL调度器的细节,看看它是如何避免潜在的问题,发挥其强大的调度能力的。欲知详情,且听下回分解。
原创翻译整理文章,转发请注明出处。蜗窝科技
扫描二维码关注"Linux阅码场"

这篇关于郭健:deadline调度器之(一):原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





