本文主要是介绍神策新一代分析引擎架构演进,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!


近日,神策数据已经推出全新的神策分析 2.5 版本,该版本支持分析模型与外部数据的融合性接入,构建全域数据融合模型,实现从用户到经营的全链路、全场景分析。新版本的神策分析能够为企业提供更全面、更有效的市场信息和经营策略,帮助企业深入了解用户需求、把握市场动态,从而提高竞争力。这一重要升级为企业提供了更强大的数据分析工具,为其业务发展和决策提供有力支持。
神策客户旅程分析引擎(简称“神策分析引擎”)作为新版本的技术内核,也进行了一次重要的架构演进,接下来,本文将详细讲述神策分析 2.5 版本中分析引擎的架构演进方向和重要能力优化。
一、全面的弹性架构能力支持
神策分析引擎支持全面的弹性架构,实现了存储、查询、导入三部分的架构分离,且各自都支持多种能力等级配置和弹性扩缩容。企业可以结合自己的业务需要,灵活组合最佳方案,极致优化硬件成本。
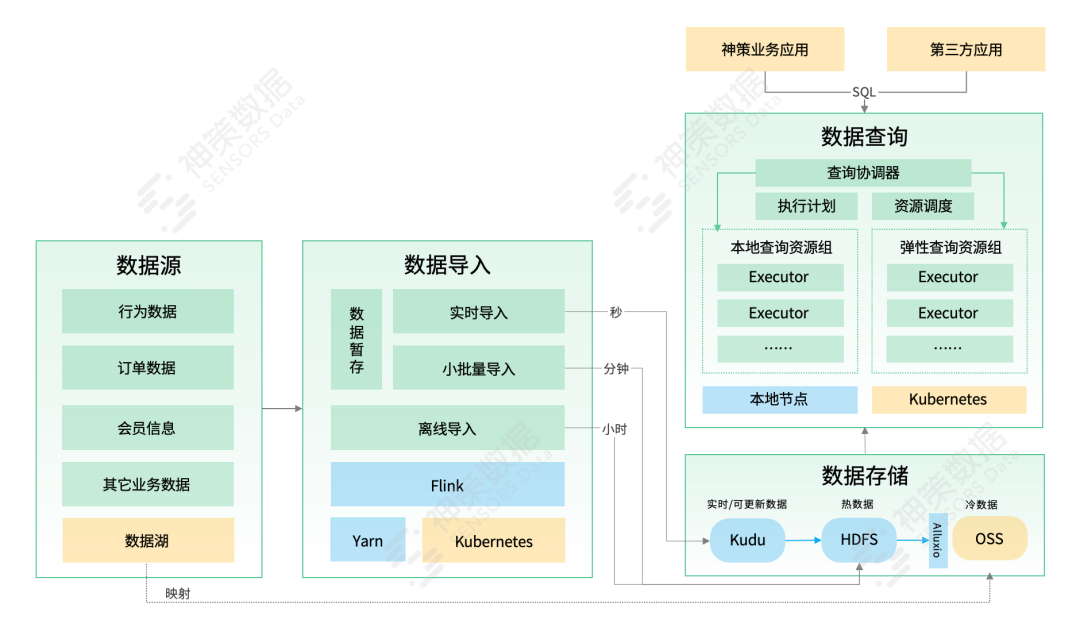
图 神策分析引擎整体架构
1、弹性存储,双向打通主流数据湖生态
神策分析引擎是原生的存算分离架构,无论是不可变数据存储(HDFS、对象存储),还是可变数据存储(Kudu),都可以灵活的进行扩展。
根据数据的冷热程度和可更新性,引擎采用不同的存储系统。这样做的目标是最大程度减少对高性能 SSD 磁盘的使用需求,尽量采用低成本的 HDD 磁盘存储大容量数据。通过 Alluxio 的方案,引擎可以直接无缝连接各大公有云的对象存储,实现低成本的弹性扩容。当然,考虑到本地存储具有更好的性能优势,以及在一次性预付费折扣下成本也相对可控,因此弹性也并不总是最佳选择。企业可以根据业务类型和需求,灵活调整存储类型的比例,以在性能和成本之间找到最佳平衡点。
存算分离架构也会带来一些性能方面的副作用,因此在小规模集群中,神策数据默认依然采用计算和存储同机部署模式,以减少网络开销并提高扫描性能。而在大规模集群和弹性模式下,引擎则会智能利用 Local Cache 技术,减少因存算分离带来的额外网络开销。
此外,神策分析引擎完全兼容 Iceberg 标准,使得与客户现有的数据仓库和数据湖体系进行双向打通变得轻松,无需冗余存储数据,且保证了不同应用之间数据的一致性。Iceberg 数据湖标准目前受到了主流数据仓库和数据湖解决方案的广泛支持,拥有完善的开源生态工具链。
2、弹性查询,灵活应对企业经营需求
查询资源通常是分析引擎的整体资源使用中波动最大的部分,因为它不仅和企业的业务高峰有关系(例如促销活动带来的流量高峰),也受到企业的自己的经营活动(例如周报月报、版本发布)的直接影响。为此,神策分析引擎提供了非常灵活的查询资源配置方案。
首先,对于较稳定的业务固定查询需求,需要配备一定比例的本地查询资源,由于这部分资源是存储计算一体化,通常查询性能更好、延迟更低。后期也可以根据业务的增长需要,再进行扩容操作。
其次,对于夜间的离线计算或者临时性大规模查询,例如大型促销活动或者新游戏上线等场景,可以使用基于 Kubernetes 集群的弹性的查询资源。这里的最佳实践方案是使用各大公有云厂商的按需计价节点,或者竞价实例(如 AWS Spot 实例)来进行部署。按照神策数据过往服务客户的实践经验,该方案相比完全使用本地查询资源大约可以节省 20%~30% 的成本。
最后,分析引擎不仅支持物理隔离的查询资源组,还支持在资源组中划分优先级队列,例如可以按照产品线、查询大小来进行资源分配,从而更好的保障高优先级的业务需求。
3、弹性导入,最大化硬件资源利用率
在导入能力上,神策分析引擎提供了秒级实时、分钟级微批和小时级离线导入等多种方式,以在时效性和吞吐量之间取得平衡,最大限度地提高资源利用率。并且允许在不同模式之间进行动态切换,如在导入高峰期间切换到微批模式,过后再切回实时模式。
相比查询来说,导入的资源消耗通常是比较稳定的,一般默认情况下使用固定的本地资源运行即可。但是,对于大批量、一次性历史数据导入需求,更好的选择是在弹性 Kubernetes 集群上运行,以避免短时间内频繁扩容和缩容带来的操作和硬件成本。
二、六大核心能力优化
1、全面强化的用户旅程分析
神策分析引擎专注于用户旅程分析这一专属场景,与通用的 OLAP 分析引擎相比,我们构建了高效的用户序列分析框架,所有的漏斗、路径、归因、LTV 等分析模型均基于此框架开发。这不仅保证了执行效率的卓越,同时也能快速根据业务需求进行功能扩展。
在应对大数据量场景时,我们提供了基于完整用户数据的快速抽样能力,确保用户行为在抽样过程中不会被割裂,从而在低成本的基础上实现快速计算,并保持指标的准确性。另外,我们还实现了高效的点查能力,支持单用户行为序列场景,有效避免了数据的冗余存储和不一致问题。此外,为应对 ID-Mapping 和数据合规场景,我们专门支持了单用户数据删除和修复功能。
2、精准的查询资源预估
对每个查询的资源进行准确预估是神策分析引擎稳定运行的重要前提。神策分析引擎除了传统的基于统计信息的预估方式之外,还引入了基于查询历史的预估,在真实业务场景中,由于企业的产品使用通常存在较强的规律性,因此往往系统运行一段时间之后,基于历史的查询预估会起到关键作用,大大提升整体的准确性。
基于精准的查询资源预估结果,一方面可以获取更佳的执行计划,另外也可以更准确地进行查询资源的调度——例如让小查询进入高优先级队列快速执行。除此之外,还可以给用户更加准确的交互反馈。
3、批流一体的实时数据聚合
神策分析引擎在支持离线分析和 Ad-Hoc 查询的同时,还能从任意历史数据时间点开始进行流式聚合查询。这意味着我们可以使用同一套查询引擎和 UDF/UDAF 实现三种不同的应用场景,实现语法的一致性、性能的高效和可复用性。通过这部分能力,我们能够实现秒级时效性的高频查询,更好地满足实时监控类需求。
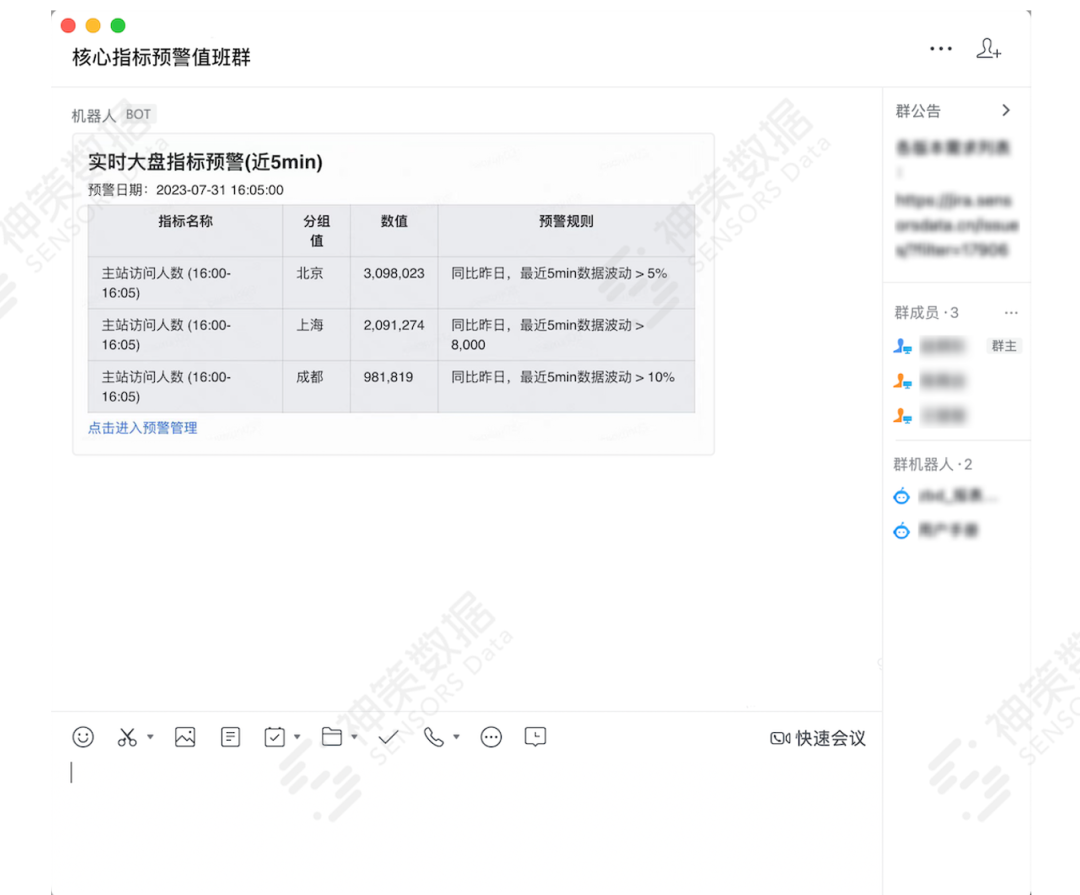
图 实时聚合的应用示例
4、一致性物化视图
物化视图是常见的 OLAP 查询引擎优化能力,通常有两种实现方式:和基表数据一致,或者需要定期更新。神策分析引擎采用一致性物化视图,这意味着我们可以在保持数据一致性的基础上,实现常用查询性能的 10 倍提升。
5、完备的数据安全体系
为确保企业数据的最大安全性,神策分析引擎采取了多重安全措施。首先,引擎提供完整的表级别和行列级别的访问控制,以确保只有授权用户能够获取相应的数据,从而保护数据的隐私和机密性。其次,在更高安全要求的场景下,引擎还支持对所有底层存储服务启用基于 KMS(Key Management Service)的加密机制,以增强数据的加密保护,确保数据在存储过程中也始终处于加密状态,防范潜在的安全威胁。
6、通用性能优化
作为一个全流程支持 CodeGen 的 C++ 查询引擎,神策分析引擎在处理复杂查询时有着显著优势。此外,通过服务 2000+ 客户的实践,我们积累了大量优化经验,引入了诸如表达式预计算、无效 JOIN 裁剪、正则缓存、Bucket Join 等细节优化,进一步提升了在复杂业务场景下的性能表现。
特别值得一提的是,在完成了诸多指令集级别的适配工作之后,神策分析引擎能够完美支持在国产 x86 和 ARM 芯片上运行,并有良好的性能表现。
三、神策分析引擎高效赋能企业经营
基于神策分析引擎,企业得以更高效地实现看数查数、分析洞察等关键业务场景。包含旧版本在内,神策分析引擎已成功为包括泛金融、泛品牌零售、泛互联网以及泛企业各细分领域在内的 2000+ 客户的数字化经营提供了稳健的能力支撑。
以某互联网工具类客户为例,其每日新增数据量高达百亿条,日均查询数千次。在此背景下,神策分析引擎展现出了优异的性能表现:看数型查询的 P95 指标在 3 秒左右,分析型查询则在 30 秒,而原始的 SQL 查询也能达到 36 秒。类似地,某电商类客户每日新增数据百亿条,日均查询次数近万次,也在不同使用场景下达到了数秒至数十秒不等的 P95 指标。
众多诸如此的成功案例充分表现出了神策分析引擎在大规模数据处理与高频查询场景下的杰出能力,为数字化时代中企业的快速发展提供了强有力的数据支持,助力企业实时了解业务情况、准确做出决策,实现高效企业经营。
✎✎✎
【更多内容】
神策数据双引擎赋能数字化客户经营
神策分析 Android SDK 入选“星熠”案例
关于数据分析模型的十问十答
这篇关于神策新一代分析引擎架构演进的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





