本文主要是介绍.Net Core中利用TPL(任务并行库)构建Pipeline处理Dataflow,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在学习的过程中,看一些一线的技术文档很吃力,而且考虑到国内那些技术牛人英语都不差的,要向他们看齐,所以每天下班都在疯狂地背单词,博客有些日子没有更新了,见谅见谅
什么是TPL?
Task Parallel Library (TPL), 在.NET Framework 4微软推出TPL,并把TPL作为编写多线程和并行代码的首选方式,但是,在国内,到目前为止好像用的人并不多。(TPL)是System.Threading和System.Threading.Tasks命名空间中的一组公共类型和API 。TPL的目的是通过简化向应用程序添加并行性和并发性的过程来提高开发人员的工作效率,TPL动态地扩展并发度,以最有效地使用所有可用的处理器。通过使用TPL,您可以最大限度地提高代码的性能,让我们专注于程序本身而不用去关注负责的多线程管理。
出自: https://docs.microsoft.com/en-us/dotnet/standard/parallel-programming/task-parallel-library-tpl
为什么使用TPL?
在上面介绍了什么是TPL,可能大家还是云里雾里,不知道TPL的好处到底是什么。
我在youtube上找到了一个优秀的视频,讲述的是TPL和Thread的区别,我觉得对比一下,TPL的优势很快就能体现出来,如果大家能打开的话建议大家一定要看看。
地址是:https://www.youtube.com/watch?v=No7QqSc5cl8
现如今,我们的电脑的CPU怎么也是2核以上,下面假设我的电脑是四核的,我们来做一个实验。
使用Thread
代码中,如果使用Thread来处理任务,如果不做特出的处理,只是thread.Start(),监测电脑的核心的使用情况是下面这样的。

每一条线代表CPU某个核心的使用情况,明显,随着代码Run起来,其实只有某一个核心的使用率迅速提升,其他核心并无明显波动,为什么会这样呢?

原来,默认情况下,操作系统并不会调用所有的核心来处理任务,即使我们使用多线程,其实也是在一个核心里面运行这些Thread,而且Thread之间涉及到线程同步等问题,其实,效率也不会明显提高。
使用TPL
在代码中,引入了TPL来处理相同的任务,再次监视各个核心的使用情况,效果就变得截然不同,如下。

可以看到各个核心的使用情况都同时有了明显的提高。

说明使用TPL后,不再是使用CPU的某个核心来处理任务了,而是TPL自动把任务分摊给每个核心来处理,处理效率可想而知,理论上会有明显提升的(为什么说理论上?和使用多线程一样,各个核心之间的同步管理也是要占用一定的效率的,所以对于并不复杂的任务,使用TPL可能适得其反)。
实验结果出自https://www.youtube.com/watch?v=No7QqSc5cl8
看了这个实验讲解,是不是理解了上面所说的这句。
TPL的目的是通过简化向应用程序添加并行性和并发性的过程来提高开发人员的工作效率,TPL动态地扩展并发度,以最有效地使用所有可用的处理器。
所以说,使用TPL 来处理多线程任务可以让你不必吧把精力放在如何提高多线程处理效率上,因为这一切,TPL 能自动地帮你完成。
TPL Dataflow?
TPL处理Dataflow是TPL强大功能中的一种,它提供一套完整的数据流组件,这些数据流组件统称为TPL Dataflow Library,那么,在什么场景下适合使用TPL Dataflow Library呢?
官方举的一个 栗子 再恰当不过:
例如,通过TPL Dataflow提供的功能来转换图像,执行光线校正或防红眼,可以创建管道数据流组件,管道中的每个功能可以并行执行,并且TPL能自动控制图像流在不同线程之间的同步,不再需要Thread 中的Lock。
TPL数据流库由Block组成,Block是缓冲和处理数据的单元,TPL定义了三种最基础的Block。
source blocks(System.Threading.Tasks.Dataflow.ISourceBlock <TOutput>),源块充当数据源并且可以从中读取。
target blocks(System.Threading.Tasks.Dataflow.ITargetBlock <TInput>),目标块充当数据接收器并可以写入。
propagator blocks(System.Threading.Tasks.Dataflow.IPropagatorBlock <TInput,TOutput>),传播器块充当源块和目标块,并且可以被读取和写入。它继承自ISourceBlock <TOutput>和ITargetBlock <TInput>。
还有其他一些个性化的Block,但其实他们都是对这三种Block进行一些扩充,可以结合下面的代码来理解这三种Block.
Code Show
1.source block 和 target block 合并成propagator block.

可以看到,我定义了BufferBlock和ActionBlock,它们分别继承于ISourceBlock 和 ITargetBlock ,所以说,他们其实就是源块和目标块,在new actionBlock()中传入了一个Action<String>,该Action就是该Block所执行的任务。 最后,DataflowBlock.Encapsulate(actionBlock, bufferBlock)把源块和目标块合并成了一个传递块。
2.TransformBlock
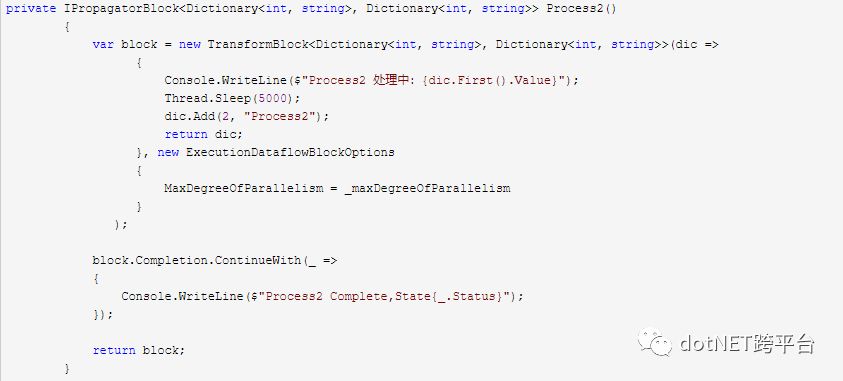
TransfromBlock继承了IPropagatorBlock,所以它本身就是一个传递块,所以它除了要处理出入数据,还要返回数据,所以给new TransformBlock()中传入的是Func<TInput, TOutput>而不是Action<TInput>.
3.TargetBlock来收尾

TargetBlock只能写入并处理数据,不能读取,所以TargetBlock适合作为Pipeline的最后一个Block。
4.控制每个Block的并行度
在在构造TargetBlock(包括其子类)的时候,可以传入ExecutionDataflowBlockOptions参数,ExecutionDataflowBlockOptions对象里面有一个MaxDegreeOfParallelism属性,通过改制,可以控制该Block的同时处理任务的数量(可以理解成线程数)。

5.构建Pipeline,连接Block

通过
ISourceBlock<TOutput>.LinkTo(ITargetBlock<TOutput> target, DataflowLinkOptions linkOption)
方法,可以把Block连接起来,即构建Pipeline,当DataflowLinkOptions对象的PropagateCompletion属性为true时,SorceBlock任务处理完成是,会把TargetBlock也标记为完成。
Block被标记为Complete 后,无法传入新的数据了,即不能再处理新的任务了。
6.Pipeline的运行

Pipeline构建好后,我们只需要给第一个Block传入数据,该数据就会在管道内流动起来了,所有数据传入完成后,调用Block的Complete方法,把该Block标记为完成,就不可以再往里面Post数据了。

测试运行如图:

我来解释一下,为什么是这么运行的,因为把管道的并行度设置为2,所以每个Block可以同时处理两个任务,所以,如果给管道传入四个字符 ,每个字符作为一个任务,假设传入 “码农阿宇”四个任务,会时这样的一个过程…..
码 农 两个首先进入Process1,
处理完成后,码 农 两个任务流出,
Process1位置空出来, 阿 宇 两个任务流入 Process1,
码 农 两个任务流向 Process2,
阿 宇 从 Process1 处理完成后流出,此时Process1任务完成
码 农 流出 Process2 ,同时 阿 宇 流入 Process2 ……
依此类推….
该项目Github地址: https://github.com/liuzhenyulive/Tpl-Dataflow-Demo
参考文献:https://docs.microsoft.com/en-us/dotnet/standard/parallel-programming/dataflow-task-parallel-library
原文地址: https://www.cnblogs.com/CoderAyu/p/9757389.html
.NET社区新闻,深度好文,欢迎访问公众号文章汇总 http://www.csharpkit.com

这篇关于.Net Core中利用TPL(任务并行库)构建Pipeline处理Dataflow的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






