本文主要是介绍缓解缓存击穿的大杀器之---singleflight深入浅出,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
singleflight简单介绍
singlefight直译“单飞”,那顾名思义就是有一堆鸟,但是咱只让一只鸟单飞。。。😄
singleflight
提供了重复函数调用抑制机制,使用它可以避免同时进行相同的函数调用。第一个调用未完成时后续的重复调用会等待,当第一个调用完成时则会与它们分享结果,这样以来虽然只执行了一次函数调用但是所有调用都拿到了最终的调用结果。
singleflight使用场景
singleflight设计模式能够有效减轻对数据库的压力。
singleflight:在有多个goroutine试图去数据库加载同一个 key对应数据的时候,只允许一个goroutine过去查询,其它都在原地等待结果。
对数据库的压力本来是跟QPS相当,变为跟同一时刻不同key的数量和实例数量相当。例如同一个时刻需要加载十个不同key 的数据,应用部署了三个实例,那么对数据库的压力就是10* 3。
热点越集中的应用,效果越好。
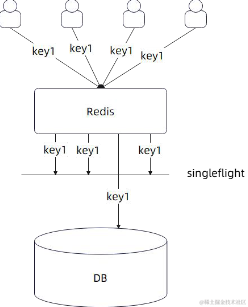
而对于缓存击穿的情况
↓:
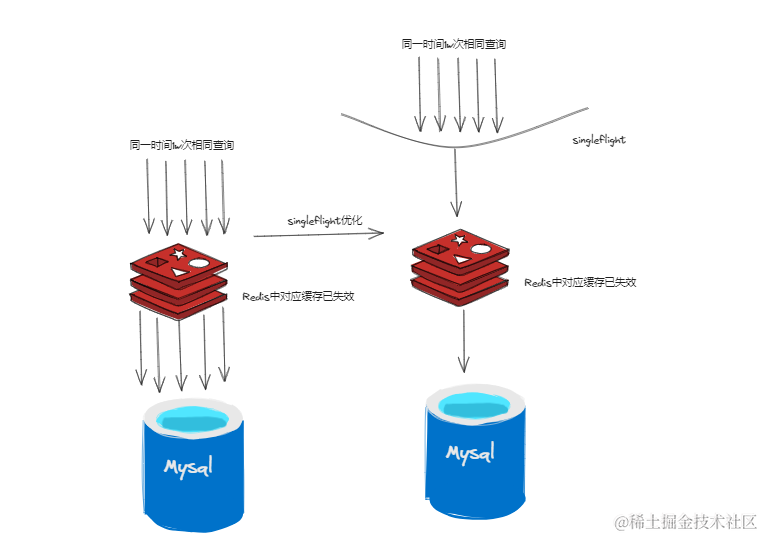
使用singleflight也能让同一时间大量相同的请求进行阻塞等待而只让第一个去实际执行~
singleflight的作用是非常广泛的,其他的场景咱们需要进行这样的限流都可以考虑一下这种设计的使用。了解过分布式锁的各位都知道,分布式锁主要是用来对分布式系统一致性问题的一个“并发更新”的解决。而分布式锁加上来由于锁的竞争往往会使得整个系统变得很慢,那我们完全可以考虑singleflight配合上分布式锁一起使用来减少锁竞争的压力

在单机中我们就通过singleflight来竞争出一个优胜者然后再与别的集群去竞争锁,这样我们就可以将大量的锁竞争减少为节点之间的锁竞争~
而singleflight的具体使用大家可以自行去看文档,用起来还是相对容易~~
singleflight底层实现
为什么要讲这个问题?是因为我项目中使用到了这个设计,而在之前有一次面试也被问到过这个问题,索性就顺便把底层实现也一并讲解。
其实当时在面试之前我没看过这一实现的底层,但是回答的时候也几乎猜中了八九不离十。讲讲我当时猜题的思路
抓住该设计的三个特性:
1.多个并发请求—>线性执行 :那么肯定需要一把互斥锁,这是肯定的
2.其中一个去执行了,后面的就阻塞等待----->:这个想一想也不难猜出,
如何让后面的请求知道相同的请求已经去执行了?
很容易可以想出我们可以使用一个map去进行存储。
当第一个请求到了去map查询未查到值那说明它就是第一个,
把它放入map中后续请求再来查map那显然就知道已经有请求去执行了。
3.之后的请求知道了已经有请求执行了,
如何让它们阻塞等待,
并在执行结束后拿到结果并阻塞取消?-------> 如何让它们阻塞?
很容易可以想到使用等待组 sync.waitGroup,而拿到结果那不用想就是channel了。
说完了我当时的分析,那咱们可以一起看看设计者的源码是怎么样的?
// Group represents a class of work and forms a namespace in
// which units of work can be executed with duplicate suppression.
type Group struct {mu sync.Mutex // protects mm map[string]*call // lazily initialized
}
这就是核心数据结构,可以看到跟我分析也大差不差,一把互斥锁,一个map用于存储请求~
// call is an in-flight or completed singleflight.Do call
type call struct {wg sync.WaitGroup// These fields are written once before the WaitGroup is done// and are only read after the WaitGroup is done.val interface{}err error// These fields are read and written with the singleflight// mutex held before the WaitGroup is done, and are read but// not written after the WaitGroup is done.dups intchans []chan<- Result
}// Result holds the results of Do, so they can be passed
// on a channel.
type Result struct {Val interface{}Err errorShared bool
}这是map中call的数据结构,可以看到其中核心的wg就是用来阻塞、取消阻塞的,而chans显然就是用来发送结果的,result即使结果的数据结构
看完核心数据结构再看看主要api的逻辑
这个设计中主要api有
//do执行并返回给定函数的结果
//确保只有一次执行正在进行中,
//时间。如果传入重复项,则重复的调用方等待。
//原始完成,并收到相同的结果。
//返回值Shared表示v是否分配给了多个调用方
func (g *Group) Do(key string, fn func() (interface{}, error)) (v interface{}, err error, shared bool)
//DoChan类似于Do,但返回一个将接收。
//准备好了才会有结果。
//
//返回的频道不会关闭
func (g *Group) DoChan(key string, fn func() (interface{}, error)) <-chan Result
do与dochan的区别就是do是同步调用会阻塞,而dochan返回channel是异步调用的.
当然设计者也考虑到了如果第一个请求进去出不来的怎么办?全都堵死了,这显然是不合理的,因此设计了一个forget的方法去删除这个记录
// Forget tells the singleflight to forget about a key. Future calls
// to Do for this key will call the function rather than waiting for
// an earlier call to complete.
func (g *Group) Forget(key string) {g.mu.Lock()delete(g.m, key)g.mu.Unlock()
}
这篇关于缓解缓存击穿的大杀器之---singleflight深入浅出的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








