本文主要是介绍【推文阅读】4.20-21,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
20210420
【轻量化人工智能】
原文链接
人工智能使能框架是由芯片(硬件)、AI操作系统(深度学习框架平台)和算法三个部分组成的。而Tiny AI是以一系列轻量化技术为驱动芯片、平台和算法的效率。对外看来,Tiny AI的表现是在做减法,降低能耗、对平台指标的要求等,但其内核是在做加法,通过加速运算效率、提高计算密度来实现极致的效率。
要想实现Tiny AI就需要从软件和硬件两方面来着手,也就是说极致的轻量化必须是软件和硬件的协同轻量化:基于复杂的AI应用场景,将芯片、平台和算法充分结合以联合加速。
【第三代人工智能】
原文链接

第三代人工智能的发展路径是融合第一代知识驱动和第二代数据驱动的人工智能,综合知识、数据、算法与算力四个要素,来构建比前代更强大的人工智能。
珠算平台是基于贝叶斯推断并支持多种生成模型的软件库,既可以训练神经网络,也可以做概率建模和概率推断,能够用于无监督学习、小样本学习等。
第三代人工智能的一个重要发展方向是研制第三代人工智能编程框架及基础算法库。
提升人工智能的安全性也是第三代人工智能的重点研究方向。
【变换器跟踪】CVPR2021 TransT:
推文链接
相关概念
相关运算在于反应已有事物的内在关联,并不是事物之间的相互影响。通过简单的相似性比较,来完成模板特征和搜索区域特征的交互,输出相似度图。
相关运算的缺陷:相关运算本身是一个局部的线性匹配,导致了语义信息的丢失和全局信息的缺乏。
论文链接 论文中提出的了基于Transformer的特征融合模型,通过建立非线性语义融合和挖掘远距离特征关联有效聚合目标和搜索区域的全局信息,显著提升了算法的精准度。

上图为Transformer Tracking框架图,这个框架图包括三个基本组成:特征提取骨干、特征融合网络、预测头。提出的基于注意力的特征融合网络自然地应用于基于Siamese的特征提取主干。
代码链接
TransT由三个组件组成,骨干网络分别提取模板和搜索区域的特征,然后利用该特征融合网络对特征进行增强和融合。最后预测头对增强特征进行二值分类和包围盒回归,生成跟踪结果1。

总结:在论文中,提出了一种新颖、简单、高性能的基于Transformer类特征融合网络的跟踪框架。该网络仅利用注意机制进行特征融合,包括基于自我注意的自我情境增强模块和基于交叉注意的交叉特征增强模块。注意机制建立了长距离特征关联,使跟踪器自适应关注有用信息,提取丰富的语义信息。该融合网络可以替代相关性,合成模板和搜索区域特征,从而促进目标定位和边界盒回归。在许多基准上的大量实验结果表明,所提出的跟踪器在以实时速度运行时,性能明显优于目前最先进的算法。
【机器学习导论-234页pdf】
电子链接
【使用transformer进行物体检测】实操
推文链接
该文介绍了Facebook研究团队利用Transformer架构开发的DEtection TRansformer(DETR),这是一个目标检测模型。
DETR模型由一个预训练的CNN骨干(如ResNet)组成,它产生一组低维特征集。这些特征被格式化为一个特征集合并添加位置编码,输入一个由Transformer组成的编码器和解码器中,和原始的Transformer论文中描述的Encoder-Decoder的使用方式非常的类似。解码器的输出然后被送入固定数量的预测头,这些预测头由预定义数量的前馈网络组成。每个预测头的输出都包含一个类预测和一个预测框。损失是通过计算二分匹配损失来计算的。该模型做出了预定义数量的预测,并且每个预测都是并行计算的
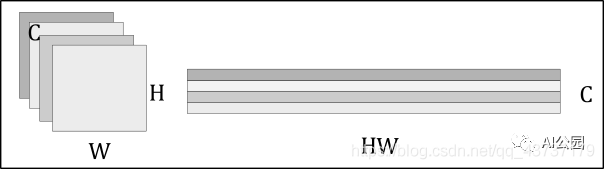
CNN主干:假设我们的输入图像,有三个输入通道。CNN backbone由一个(预训练过的)CNN(通常是ResNet)组成,我们用它来生成_C_个具有宽度W和高度H的低维特征(在实践中,我们设置_C_=2048, W=W₀/32和H=H₀/32)。这留给我们的是C个二维特征,由于我们将把这些特征传递给一个transformer,每个特征必须允许编码器将每个特征处理为一个序列的方式重新格式化。这是通过将特征矩阵扁平化为H⋅W向量,然后将每个向量连接起来来实现的。扁平化的卷积特征再加上空间位置编码,位置编码既可以学习,也可以预定义。

Transformer几乎与原始的编码器-解码器架构完全相同。不同之处在于,每个解码器层并行解码N个(预定义的数目)目标。 该模型还学习了一组N个目标的查询,这些查询是(类似于编码器)学习出来的位置编码。
具体实现不再赘述。

【端到端Transformer视频实例分割】
视频实例分割(VIS)是一项需要同时对视频中感兴趣的对象实例进行分类、分割和跟踪的任务。
文章中提出了一个新的基于Transformers的视频实例分割框架VisTR,它将VIS任务看作一个直接的端到端并行序列解码/预测问题。
给定一个由多个图像帧组成的视频片段 作为输入,VisTR直接输出视频中每个实例的掩码序列。 其核心是一种新的、有效的实例序列匹配与分割策略,它在序列级对实例进行整体监控和分割。 VisTR从相似性学习的角度对实例进行分割和跟踪,大大简化了整个流程,与现有方法有很大的不同。
Code

上图为VisTR 整体框架.该模型以一系列图像作为输入,输出一系列实例预测。在这里,相同的形状表示一个图像中的预测,相同的颜色表示同一对象实例的预测。 请注意,总体预测遵循输入帧顺序,不同图像的对象预测顺序保持相同
VisTR从相似性学习的新角度解决了VIS问题。实例分割就是学习像素级的相似度,实例跟踪就是学习实例之间的相似度。 因此,在相同的实例分割框架下,可以无缝、自然地实现实例跟踪
算法流程这里不再赘述
【2021综述论文《小样本/GNN/深度学习/机器学习/知识图谱/NLP/CV》大集合】
链接
这篇关于【推文阅读】4.20-21的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









