本文主要是介绍用深度Q网络玩电子游戏,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

本文为 AI 研习社编译的技术博客,原标题 :
Beating Video Games with Deep-Q-Networks
作者 | Liam Hinzman
翻译 | ceroo
校对 | 斯蒂芬•二狗子 审核 | 酱番梨 整理 | 立鱼王
原文链接:
https://towardsdatascience.com/beating-video-games-with-deep-q-networks-7f73320b9592
我爱死玩电子游戏了。
我每天都玩,然而,乒乓球我连10岁妹妹都打不赢。
蛮挫败的,所以我决定建立一个深度Q网络,用这个网络学习如何在任一电子游戏中打败我的妹妹。
经过几天的不间断编程(夜不能寐),这就是我用Deep-Q-Networks所能达成的实践:

偷偷看下我的DQN模型的结果(绿色球拍)
绿色球拍由DQN模型控制,完全靠它自我对弈 ,以此学习如何玩乒乓球。
随后,我会详细说说我的结果,但首先...
什么是DQN(Deep-Q-Networks),它是如何工作的?
简单说:DQN结合了深度学习和强化学习来学习如何玩电子游戏,并超过人类水平。
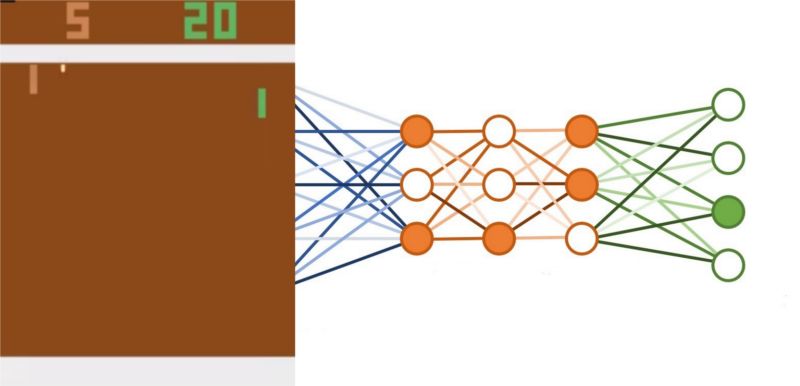
DQNs结合强化学习和深度学习来玩视频游戏
你所需要知道的是,深度学习(理解DQN)是一种使用神经网络来模仿人类大脑工作的计算架构。其中,神经网络的输入和输出都是数字。神经网络可以学习像房价预测或识别肿瘤图像等任务。
现在,我们继续回到DQN这条主线...
快速学会强化学习
那么什么是强化学习呢?
强化学习是一种机器学习技术,它通过采取行动来学习如何最大化奖励。
一条狗可能会尝试学习,如何最大限度地通过它的吠叫来诱导主人抚摸它的肚皮,或一只猫可能会尝试学习,如何最大限度地通过它的跳跃“作”得一手好死。这两种动物都是根据它们当前的状态采取行动的智能体,试图最大化某种奖励。
让我们更深入地了解这些术语对于一个“吃豆人”游戏的含义。

PacMan(吃豆人)(黄色圆圈)是智能体,这是玩家在游戏中控制的。状态一般指是游戏中的某个一个时刻,在这里状态是游戏中的某一帧。智能体可以选择进入哪个方向(操作),并使用这些操作来避免死于鬼魂(负奖励)和吃更多的点(正奖励)。PacMan的目标是最大化你的得分(奖励)。
重要的强化学习术语
Agent 智能体:计算机控制的内容(pac man)
State 状态:游戏中的当前时刻(PacMan中的单帧图像)
Action 行动:由代理人作出的决定(PAC人员向左或向右移动)
Reward 奖励: 智能体试图最大化的价值(在pac man中得分)
你还需要了解一件关于强化学习理解深层Q网络的事情:Q值
Q值,即深度Q网络中的Q值,是一个动作在给定状态下的“质量”。如果一个行动具有高的预期长期价值,那么它就是高质量的。
睡前给妈妈一个拥抱(动作)可能不会马上给我“奖励”,但从长远来看,它会给我很多爱(奖励),所以这个状态动作对的Q值很高(我在心里计算每晚拥抱妈妈的Q值)。
你需要知道这些强化学习的概念,并以此了解DQN!
深入深度Q网络
那么,我是如何让一台电脑学习如何比别人更好地玩电子游戏的(并在乒乓球中击败我的妹妹)?
我使用DQN网络!
DQNs使用Q-learning学习给定状态下要采取的最佳行动(q值),并使用卷积网络作为Q-learning的近似值函数。
以下是要记住的关键点:
深度学习+强化学习=深度Q网络(DQN)
而不是为屏幕上的每个像素组合记忆不同的Q值(有十亿!)我们使用卷积网络在相似状态下推理出类似的Q值。
卷积网络可以告诉玩电子游戏的'Agent':“是的,这个位置基本上和另一个相同,向上移动”。这使得'Agent'的工作变得容易多了。它不需要数十亿个不同游戏状态的Q值才能学会,只需要几百万个Q值来学习。
下面是我的DQN的卷积网络在代码中的样子:
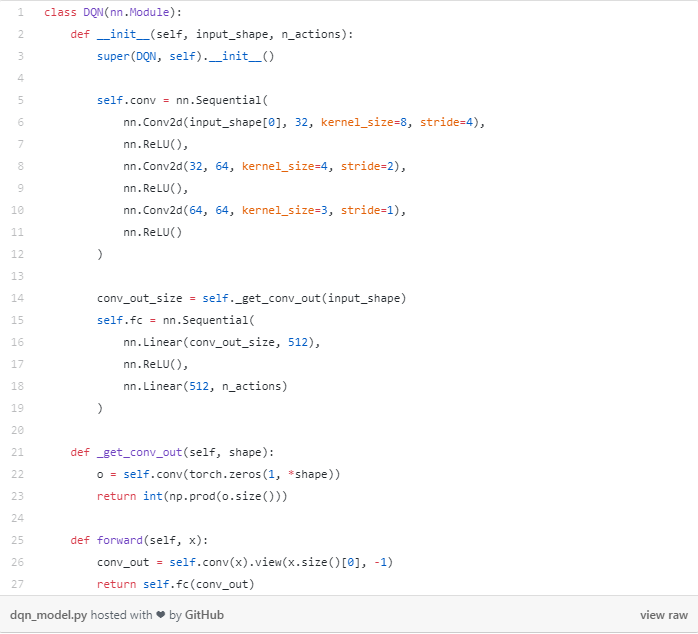
下面是此代码块的作用:
将当前屏幕(状态)作为输入
通过3个卷积层传递输入(用于在图像中查找位置图案)
注意:不使用池化操作(空间位置在游戏中很重要,我们想知道球在哪里!)
卷积层的输出被送入2个全连接层。
线性层的输出则给出了DQN在当前状态下采取某种行动的概率。
预处理
我也做了一些游戏图像的预处理。Atari游戏通常是210x160像素大小,有128种不同的颜色。为了使我的DQN的工作更容易,我将图像的采样率降低到84x84,并使其灰度化。
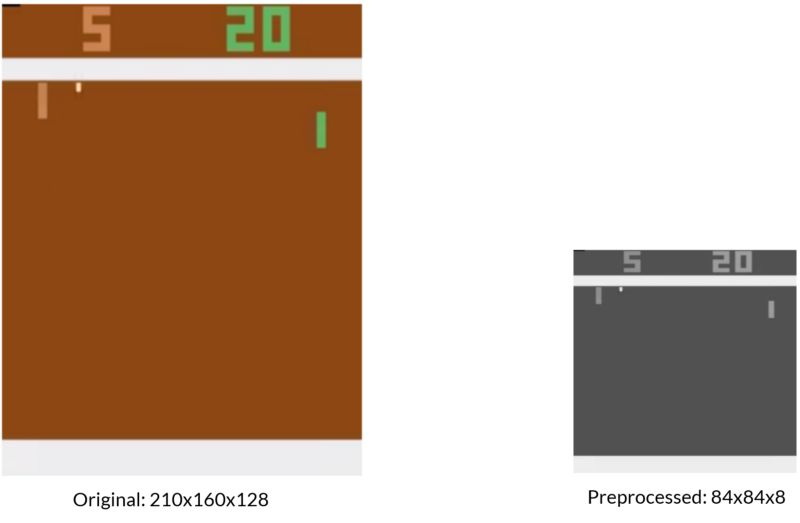
预处理过图像不再明亮和多彩,但更容易被我的DQN识别。
损失函数
现在我们需要一些方法来评估DQN。情况如何?它在学习什么吗?我们如何调整它使它更好,得到更高的分数?
要知道所有这些,我们需要一个损失函数。
唯一的问题是我们不知道最好的答案是什么,agent应该做什么。DQN如何学习才能比人类玩的更好,因此即使我们想模型达到这样,我们也无法制作出完美的标记数据集。
相反,我们使用这个损失方程来评估DQN自身:
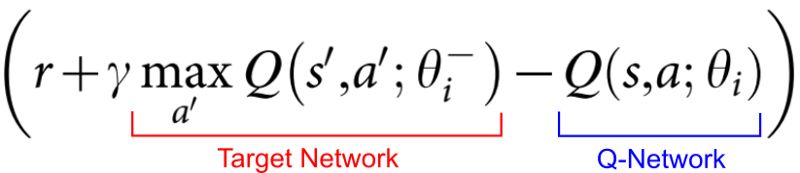
DQN的损失函数
这个Q网络Q-Network是给出要采取什么行动的网络。目标网络Target Network是给出我们使用的“ground truth”的近似值。
如果Q-Network预测在某一状态下的正确动作是以60%的确定性(概率)向上移动,而目标网络告诉我们“你应该向上移动”,我们将使用反向传播调整Q-Network的参数,使其更可能预测在该状态下的“向上移动”。
我们通过DQN反向传播这种损失,并稍微调整Q网络的权重以减少损失。
该损失函数试图使DQN输出的移动概率更接近于目标网络给出的“正确选择”,即接近100%确定性。
经验回放
现在DQNs好像就是Q学习和卷积网络的结合,基本上可以这样看。这个想法很简单,为什么它只在2015年被DeepMind研究人员引入?
神经网络不能很好地进行强化学习。
为什么神经网络和强化学习不能融洽相处?
两个原因
高度相关数据
非平稳分布
在有监督学习中,数据是不相关和固定的。当图像分类器正在学习什么使一只猫成为一只猫时,显示给它的每个图像都将显著不同,数据是不相关的。此外,网络的预测(通常)不会影响下一步将看到的图像,数据集是固定的,并且是从中随机抽样的。静止的不相关数据与神经网络很好地配合。
在强化学习中,数据是高度相关和非平稳的。当pac man移到右边时,板看起来基本相同,数据高度相关。此外,网络的决定影响下一个状态,这使得数据分布非平稳。如果马里奥右移,他会看到新的硬币。这些硬币会让马里奥认为向右移动总是个好主意,也许他永远不会发现他左边的秘密通道。
经验回放Experience Replay让神经网络能很好地进行强化学习。
‘Agent’获得的每个经验(包括当前状态、动作、奖励和下一个状态)都存储在所谓的经验回放内存中。
这种训练方式与DQN网络在当前学习中所获得样本来训练不同,是从重放存储器中随机抽取“回放”来训练网络。

经验回放让深度学习和强化学习成为兄弟。
与标准Q学习相比,经验回放有三个优势:
更高数据利用
使数据不相关
平均数据分布
首先,每个经验都可能被用于对DQN的神经网络进行多次训练,从而提高数据效率。
第二,随机抽取经验样本对DQN神经网络进行训练,打破了经验之间的相关性,减少了训练更新时的方差。
第三,当从经验中学习时,一旦获得经验(称为策略学习),当前参数就决定了参数所训练的下一个数据样本。例如,如果最好的行动是将Pac Man向左移动,那么训练样本将由来自经验池中向左运动相关样本为主。
这种行为可能会导致DQN陷入糟糕的局部最小值,甚至使其发生灾难性的偏离(比我更糟糕)。

如果你不使用经验回放,模型会经常看到这个画面。
通过使用经验回放,用来训练DQN的经验来自许多不同的时间点。这样可以消除学习障碍,避免灾难性的失败。
这种简单的经验概念解决了神经网络在强化学习中的问题。现在他们可以融洽相处地一起玩了!
击败电子游戏
我在pytorch创建了一个DQN,并训练它玩乒乓球。
起初,我的DQN只能随意地玩乒乓球,但经过3个小时的训练,它学会了如何比人类玩得更好!
绿色桨是由我的超级棒DQN控制的
最疯狂的事情是我不需要更改一行代码就可以训练DQN来玩另一个游戏,并且,就可以在该游戏中到达超过人类的游戏水平。
这意味着,同样的算法,教计算机控制这个绿色的乒乓球拍,也可以教计算机如何在毁灭战士中射击恶魔。

DQN最酷的一点是他们可以学习我甚至不知道的游戏策略。在款游戏beakout中,DQN学会怎么样绕过边路快速到达顶部,并获得大量的积分。
我创造了这个DQN,它学到了我甚至不知道的东西!

DQN可以发现其创建者从未知道的策略!
这意味着计算机现在可以帮助我们学习最喜爱的电子游戏的新策略。也许DQNS会想办法在《超级马里奥兄弟》中快速到达World 9关卡。
关键的收获
使用DQNs电脑可以学习如何比人类更好地玩电子游戏。
在DQNs中,经验回放让神经网络和强化学习协同工作。
DQN可以学习他们的创建者不知道的策略。
有了DQNs,我可以在和ai玩电子游戏时打败我10岁的妹妹,那么下一步该怎么办呢?
也许我会训练一个人工智能来说服她把电视遥控器给我(这是一项更艰巨的任务)。
最后
在 Google Colab 查看我的DQN的所有代码
访问我的个人网站
注册我的每月通讯
感谢 Aadil A..
想要继续查看该篇文章相关链接和参考文献?
点击【用深度Q网络玩电子游戏】或长按下方地址:
https://ai.yanxishe.com/page/TextTranslation/1512
AI研习社今日推荐:雷锋网(公众号:雷锋网)雷锋网雷锋网
伯克利大学 CS 294-112 《深度强化学习课程》为官方开源最新版本,由伯克利大学该门课程授课讲师 Sergey Levine 授权 AI 研习社翻译。
加入小组免费观看视频:https://ai.yanxishe.com/page/groupDetail/30

这篇关于用深度Q网络玩电子游戏的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






