本文主要是介绍SENet详解-最后一届ImageNet冠军模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
声明:文章仅作知识整理、分享,如有侵权请联系作者删除博文,谢谢!
经典分类网络(传送门):目录索引、LeNet、AlexNet、VGG、ResNet、Inception、DenseNet、SeNet。
SENet最后一届 ImageNet 2017 竞赛 Image Classification 任务的冠军,也是目前细粒度分类任务的必选基础网络。CNN是通过用局部感受野,基于逐通道基础上,去融合空间信息来提取信息化的特征,对于图像这种数据来说很成功。
为了增强CNN模型的表征能力,许多现有的工作主要用在增强空间编码上,比如ResNet,DenseNet。SENet则主要关注通道上可做点,通过显示的对卷积层特征之间的通道相关性进行建模来提升模型的表征能力;并以此提出了特征重校准机制:通过使用全局信息去选择性的增强可信息化的特征并同时压缩那些无用的特征。
SE 模块可以嵌入到现在几乎所有的网络结构中。通过在原始网络结构的 building block 单元中嵌入 SE 模块,我们可以获得不同种类的 SENet。如 SE-BN-Inception、SE-ResNet、SE-ReNeXt、SE-Inception-ResNet-v2 等等。
1、关于卷积的进一步讨论

近些年来,卷积神经网络在很多领域上都取得了巨大的突破。而卷积核作为卷积神经网络的核心,通常被看做是在局部感受野上,将空间上(spatial)的信息和特征维度上(channel-wise)的信息进行聚合的信息聚合体。卷积神经网络由一系列卷积层、非线性层和下采样层构成,这样它们能够从全局感受野上去捕获图像的特征来进行图像的描述。
然而去学到一个性能非常强劲的网络是相当困难的,其难点来自于很多方面。最近很多工作被提出来从空间维度层面来提升网络的性能,如 Inception 结构中嵌入了多尺度信息,聚合多种不同感受野上的特征来获得性能增益;在 Inside-Outside 网络中考虑了空间中的上下文信息;还有将 Attention 机制引入到空间维度上,等等。这些工作都获得了相当不错的成果。
2、Se模块构建
SE网络就是通过不断的堆叠这个SE模块而成的网络。

假设张量X∈RW′×H′×C′,卷积操作为Ftr,从而得到新的张量U∈RW×H×C。到这里都是传统的卷积过程而已,然后基于U,接下来开始挤压和激励:
挤压(squeeze):将U固定通道维度不变,对每个feature map进行处理,从而得到一个基于通道的描述符1×1×C,即用一个标量来描述一个map;
作者提出的所谓挤压就是针对每个通道的feature map,进行一次GAP(全局平均池化):
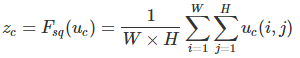
即将这个feature map表示的矩阵所有值相加,求其平均值。
激励(Excitation):将挤压得到的通道描述符1×1×C作为每个通道的权重,基于U重新生成一个X˜。
先对挤压后得到的1×1×C的向量基础上先进行一次FC层转换,然后用ReLU激活函数层,然后在FC层转换,接着采用sigmoid激活函数层,该层就是为了模仿LSTM中门的概念,通过这个来控制信息的流通量:
![]()
其中,δ是ReLU函数,W1∈RCr×C,W2∈RC×Cr,为了限制模型的复杂程度并且增加泛化性,就通过两层FC层围绕一个非线性映射来形成一个"瓶颈",其中r作者选了16,最后在得到了所谓的门之后,只要简单的将每个通道的门去乘以原来对应的每个feature map,就能控制每个feature map的信息流通量了:
![]()
从上述描述就可以看出,这其实算是一个构建网络块的方法,可以应用到inception和resnet等网络上,从而具有普适性:

整理下来,一个SE模块分为三个部分:
给定一个输入 x,其特征通道数为 c_1,通过一系列卷积希望变换后得到一个特征通道数为 c_2 的特征。即输入通道是c1,输出通道是c2。通过三个操作来重标定前面得到的特征:
1)Squeeze 操作,我们顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用的。
2) Excitation 操作,它是一个类似于循环神经网络中门的机制。通过参数 w 来为每个特征通道生成权重,其中参数 w 被学习用来显式地建模特征通道间的相关性。
3)一个 Reweight 的操作,我们将 Excitation 的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。

3、keras实现
输入为待处理feature maps,特征通道为c1,输出特征通道为c2,se相当于实现一个Dense(filter)功能。属于Dense的加强版。ratio为通道缩放的比例。squeeze_excite_block函数实现了左边c2到右边c2的映射。
def squeeze_excite_block(input, ratio=16):# 1、构造se_shapechannel_axis = 1 if K.image_data_format() == "channels_first" else -1filters = input._keras_shape[channel_axis] # 取输入的通道数c1se_shape = (1, 1, filters) # 2、Squeeze 操作,全局池化,reshape,变为一个序列se = GlobalAveragePooling2D()(input)se = Reshape(se_shape)(se)、# 3、Excitation 操作,先压缩通道数,再返回原维度se = Dense(int(filters / float(ratio)), activation='relu', kernel_initializer='he_normal', use_bias=False)(se)se = Dense(filters, activation='sigmoid', kernel_initializer='he_normal', use_bias=False)(se) # sigmoid激活# 4、Reweight 的操作,将权重乘到输入上if K.image_data_format() == 'channels_first':se = Permute((3, 1, 2))(se)x = multiply([input, se])return x
具体调用方式:

上一篇:DenseNet,传送门:分类网络目录索引。
这篇关于SENet详解-最后一届ImageNet冠军模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






