本文主要是介绍Spark Streaming实时监听HDFS目录,但出现:Input path does not exist: hdfs://node1:9000/sst-024/20180101.log._COP,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Spark Streaming实时监听HDFS目录,出现找不文件异常。
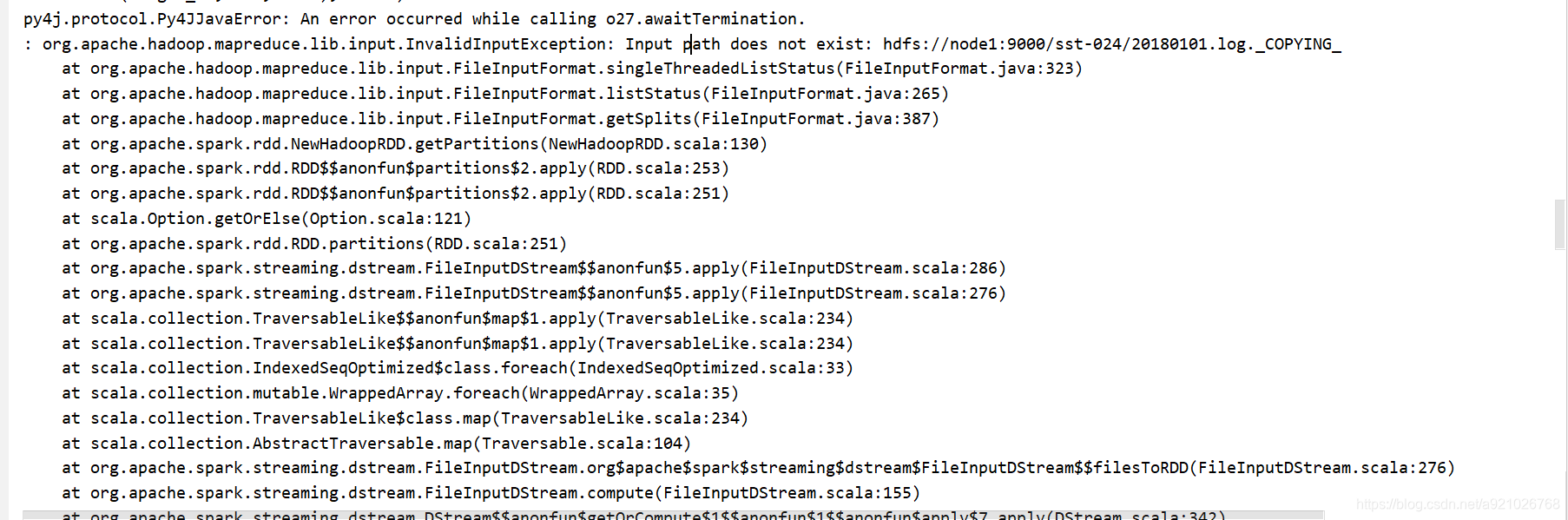
异常主要提示信息:org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist: hdfs://node1:9000/sst-024/20180101.log._COPYING_
详情如下图
出现问题原因
直接上传文件会在 HDFS 上生成一个临时文件,后缀是.COPYING,Spark Streaming 程序监听到该临时文件时,文件可能会因为复制完成被删除,导致文件找不到而出错。
解决方案
1. 先把文件上传到 Spark Streaming 非监听目录,例如 HDFS 根目录。再使用hdfs dfs -mv命令,把该文件移动到监听目录。
个人使用hdfs dfs -mv命令尝试了一下,程序可以正常运行,但是textFileStream读取不了数据。


2. 把StreamingContext的获取数据的间隔时间增大,使文件已经完全上传到HDFS上后,程序再进行文件读取,程序运行正常,并可以正常读取数据。
我个人把获取数据的间隔时间修改为5s,程序即可正常运行
ssc=StreamingContext(sc, 5)
3. 需要在文件dstream上添加过滤器,以仅获取完全复制的文件。
具体操作还没实现,有待后续更新。
这篇关于Spark Streaming实时监听HDFS目录,但出现:Input path does not exist: hdfs://node1:9000/sst-024/20180101.log._COP的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







