本文主要是介绍如何在 Unbuntu 下安装配置 Apache Zookeeper,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
Zookeeper 是 apache 基金组织下的项目,项目用于简单的监控和管理一组服务,通过简单的接口就可以集中协调一组服务,如配置管理,信息同步,命名,分布式协调。
准备工作
- Ubuntu 23.04 或者 20.04
- 访问Ubuntu系统的命令行工具
- 具有 sudo 或者 root 权限的账号
安装 Apache Zookeeper 到 Ubuntu 系统上
第一步: 安装Java
Zookeeper 是使用Java 语言编写的,我们需要提前安装Java. 通过一下命令检查Java 是否安装
java --version假如这一步能够正确显示Java的版本, 你可以直接到下一步。 如果显示的信息是 no such file or directory。 那么你就需要安装 Java.
Java 现在已经有不同的版本了,按照你的需求安装合适的版本
第二步: 为 Zookeeper 服务创建用户
1. 使用下列命令创建一个单独的用户
sudo useradd zookeeper -m-m 参数是用于在创建用户的同时创建 Home 目录。 上面的脚本会创建目录 /home/zookeeper. 如想使用不同的名称,只要替换 zookeeper 就可以。
2. 指定用户的默认shell为 bash
sudo usermod --shell /bin/bash zookeeper3. 设置密码
sudo passwd zookeeper4. 把用户添加到sudo组里面
sudo usermod -aG sudo zookeeper5. 检查一下用户是不是已经在sudo组里面
sudo getent group sudo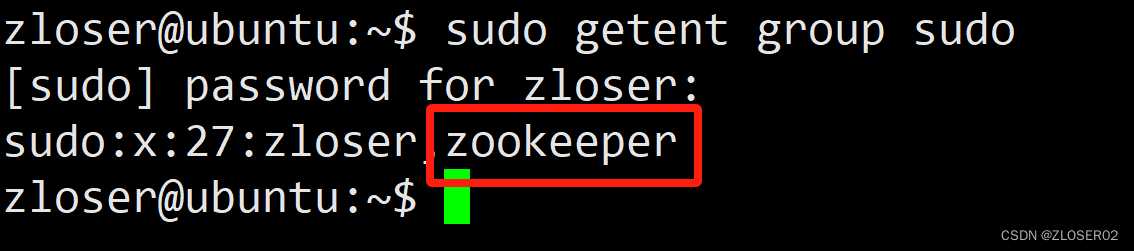
第三步:创建Zookeeper的数据目录
在真正安装 zookeeper 之前我们需要创建一个可以用于存储 zookeeper 数据和配置的文件夹。 执行下列脚本创建zookeeper 的数据目录
sudo mkdir -p /data/zookeeper设置zookeeper 用户为此目录的所有者
sudo chown -R zookeeper:zookeeper /data/zookeeper第四步: 下载并安装 Zookeeper
1. 访问 Apache Zookeeper Releases 找到最新版本.

2. 右键复制推荐的HTTP下载地址
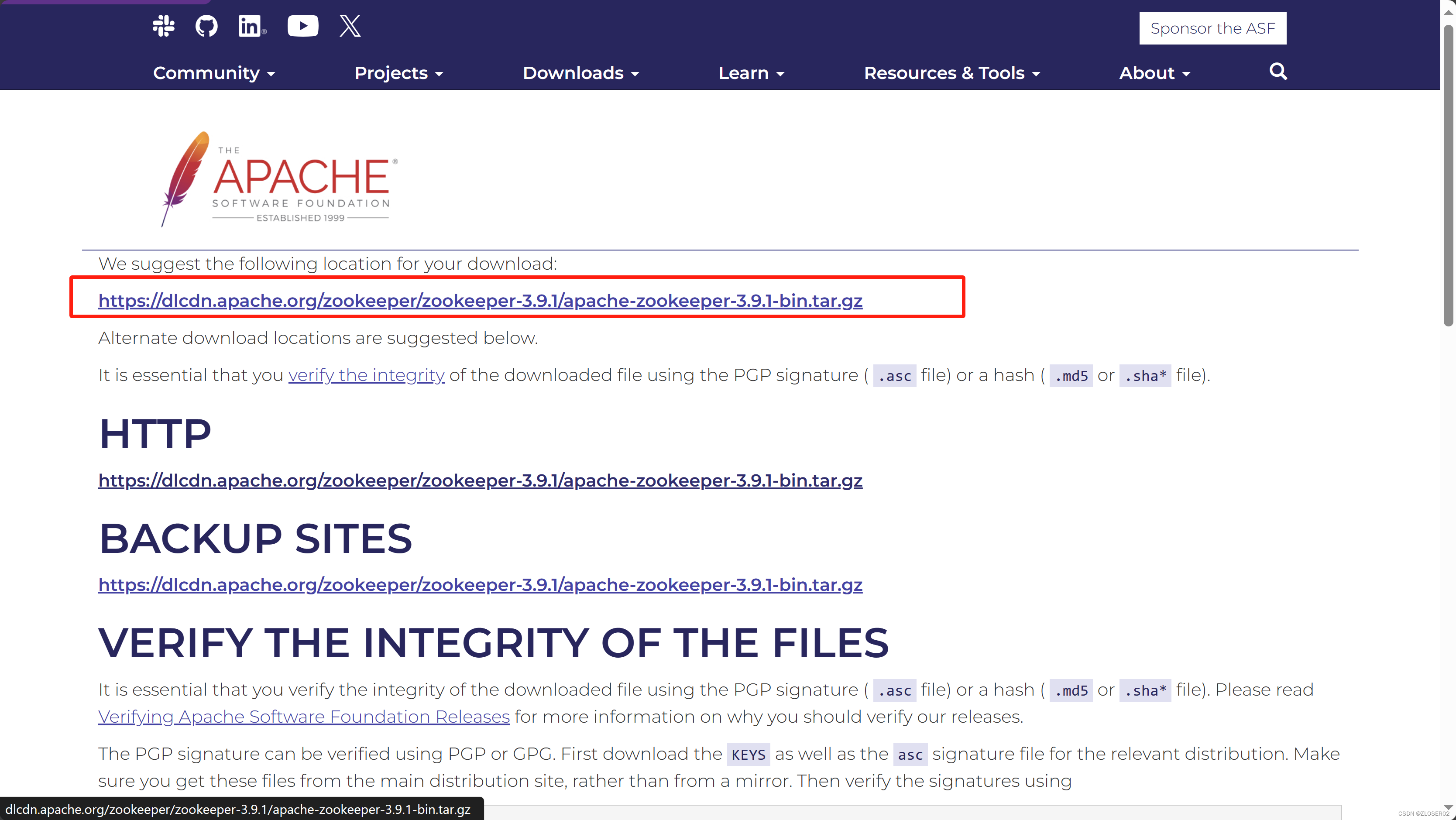
3. 返回到命令行界面,进入目录 /opt
cd /opt4. 使用 wget 命令下载 .tar 文件。粘贴刚刚复制的链接如下
sudo wget https://dlcdn.apache.org/zookeeper/zookeeper-3.9.1/apache-zookeeper-3.9.1-bin.tar.gz5. 解压文件
sudo tar -xvf apache-zookeeper-3.9.1-bin.tar.gz需要注意的是,以上两个步骤的链接地址还有文件名称,只是一个例子,具体还是需要根据你下载的文件做调整
6. 重命名文件夹的名称为 zookeeper
sudo mv apache-zookeeper-3.9.1-bin zookeeper7. 指定zookeeper 为此目录的拥有着
sudo chown -R zookeeper:zookeeper /opt/zookeeper第五步:配置单机模式下的Zookeeper
为 zookeeper 创建一个配置文件, 这个配置仅仅用于单机模式(测试环境或者开发环境)。 如果是生产环境,看第六步.
cd /opt/zookeeper/conf/sudo cp zoo_sample.cfg zoo.cfgsudo nano zoo.cfg修改数据目录地址配置项为: /data/zookeeper. 其他项目保持不变,保存并退出。
第六步:启动 zookeeper 服务
首先切换当前的用户到 zookeeper 用户
su zookeeper启动服务
/opt/zookeeper/bin/zkServer.sh start如果如下显示出 “STARTED",那么说明服务启动成功了。

第七步: 链接 zookeeper 服务
使用脚本链接本地的zookeeper 服务
/opt/zookeeper/bin/zkCli.sh -server 127.0.0.1:2181如果显示 “CONNECTED” 则说明链接成功

执行 help 查询命令说明
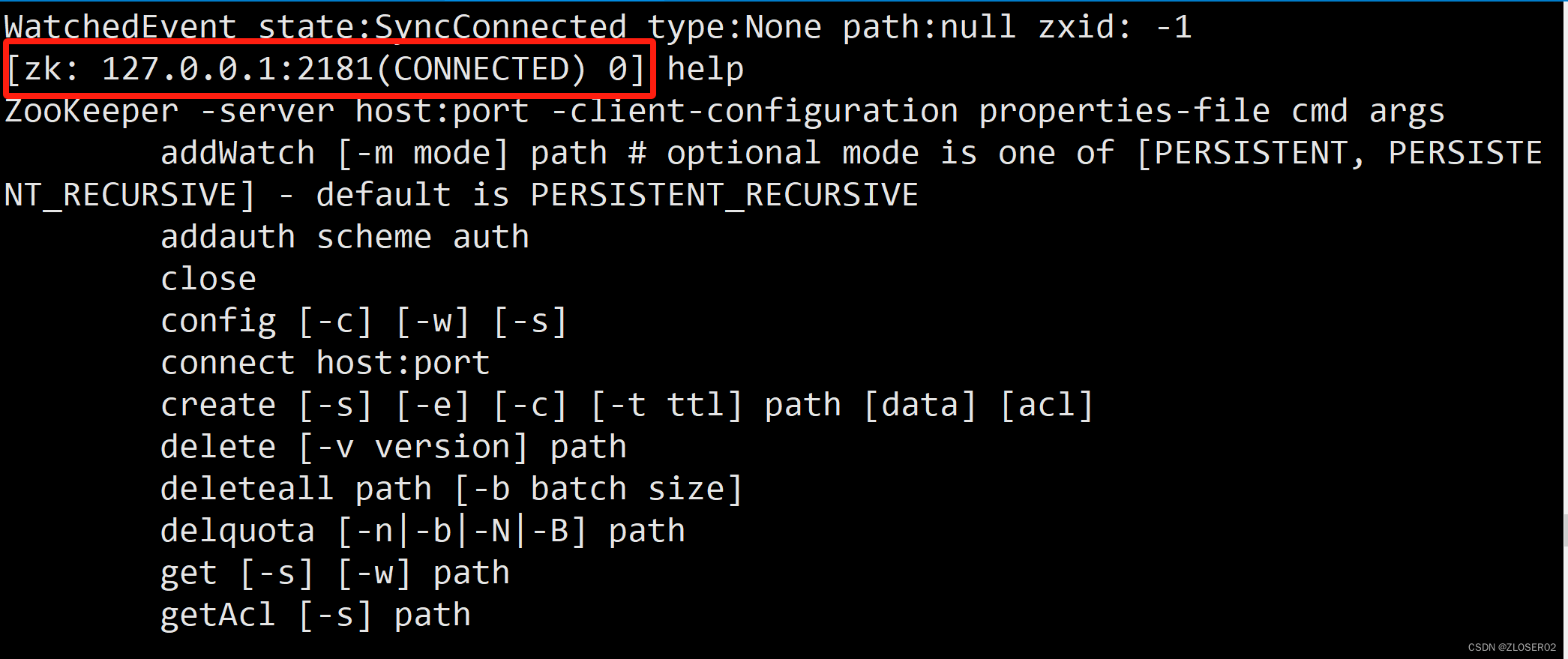
输入命令:
quit停止zookeeper 服务
/opt/zookeeper/bin/zkServer.sh stop第八步: 创建自动启动脚本
1. 创建自动启动配置文件
sudo nano /etc/systemd/system/zookeeper.service2. 复制下列内容到文件中
[Unit]
Description=Zookeeper Daemon
Documentation=http://zookeeper.apache.org
Requires=network.target
After=network.target[Service]
Type=forking
WorkingDirectory=/opt/zookeeper
User=zookeeper
Group=zookeeper
ExecStart=/opt/zookeeper/bin/zkServer.sh start /opt/zookeeper/conf/zoo.cfg
ExecStop=/opt/zookeeper/bin/zkServer.sh stop /opt/zookeeper/conf/zoo.cfg
ExecReload=/opt/zookeeper/bin/zkServer.sh restart /opt/zookeeper/conf/zoo.cfg
TimeoutSec=30
Restart=on-failure[Install]
WantedBy=default.target3. 保存并退出
4. 重启价值 system server
sudo systemctl daemon-reload5.启动zookeeper 服务并且设置为开机启动
systemctl start zookeeper
systemctl enable zookeeper6. 验证服务的状态
systemctl status zookeeper如果你看到高亮的 active (running) 则说明服务成功启动
配置集群模式的 zookeeper
第一步: 创建多个zookeeper实例
集群模式下,首先你需要准备多个 Ubuntu 机器实例。并且按照第二章节的逐个安装配置。
第二步:为每一个zookeeper 实例指定一个唯一的id
nano /data/zookeeper myid文件内容就是此服务的id
1循环上一个步骤,以此给每个服务器创建一个唯一的id.
第三步:在zookeeper 的配置文件中逐个添加服务器列表
nano /opt/zookeeper/conf/zoo.cfg内容如下:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/data/zookeeper
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=trueserver.1=[server_ip]:2888:3888
server.2=[server_ip]:2888:3888
server.3=[server_ip]:2888:3888第三步:逐个重启zookeeper
systemctl restart zookeeper.service参考链接:
How To Install Apache ZooKeeper On Ubuntu
这篇关于如何在 Unbuntu 下安装配置 Apache Zookeeper的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






