本文主要是介绍大数据之LibrA数据库系统告警处理(ALM-12016 CPU使用率超过阈值),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
告警解释
系统每30秒周期性检测CPU使用率,并把实际CPU使用率和阈值相比较。CPU使用率默认提供一个阈值范围。当检测到CPU使用率连续多次(可配置,默认值为10)超出阈值范围时产生该告警。
平滑次数为1,CPU使用率小于或等于阈值时,告警恢复;平滑次数大于1,CPU使用率小于或等于阈值的90%时,告警恢复。
告警属性
| 告警ID | 告警级别 | 可自动清除 |
|---|---|---|
| 12016 | 严重 | 是 |
告警参数
| 参数名称 | 参数含义 |
|---|---|
| ServiceName | 产生告警的服务名称。 |
| RoleName | 产生告警的角色名称。 |
| HostName | 产生告警的主机名。 |
| Trigger Condition | 系统当前指标取值满足自定义的告警设置条件。 |
对系统的影响
业务进程响应缓慢或不可用。
可能原因
- 告警阈值配置或者平滑次数配置不合理。
- CPU配置无法满足业务需求,CPU使用率达到上限。
处理步骤
检查告警阈值配置或者平滑次数配置是否合理。
- 登录FusionInsight Manager,基于实际CPU使用情况,修改告警阈值和平滑次数配置项。
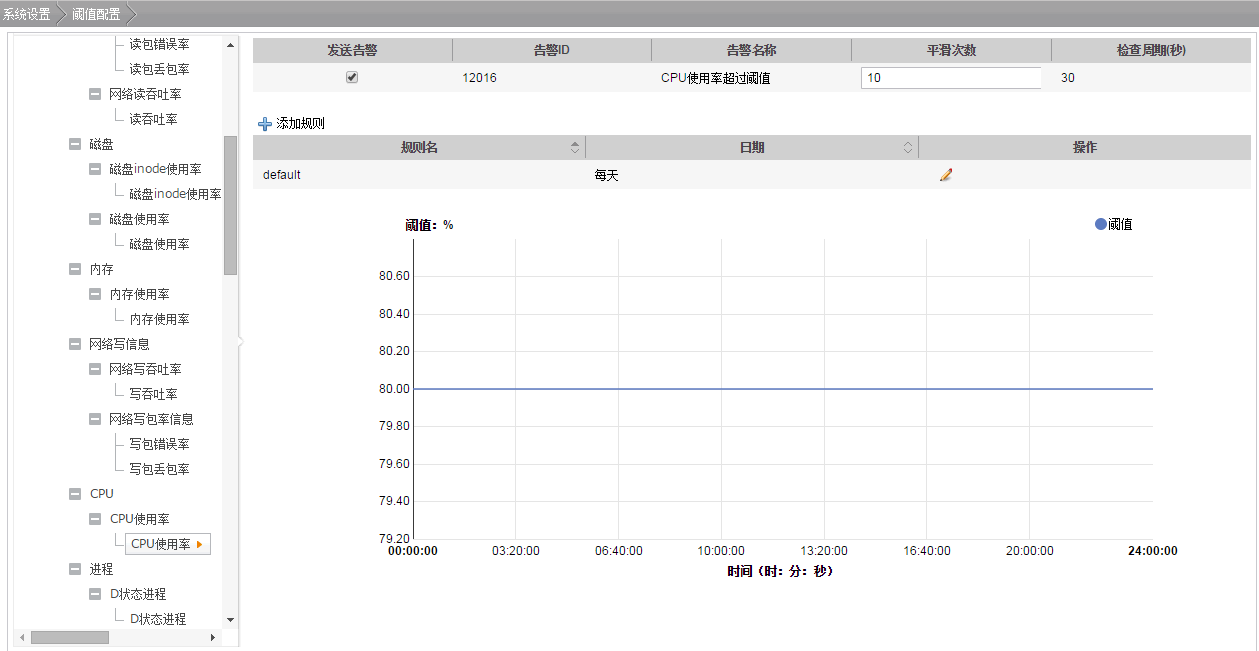
根据实际服务的使用情况在“系统设置 > 阈值配置 > 设备 > 主机 > CPU > CPU使用率 > CPU使用率”中更改告警的平滑次数,如图1所示。
说明:该选项的含义为告警检查阶段,“平滑次数”为连续检查多少次超过阈值,则发送告警。
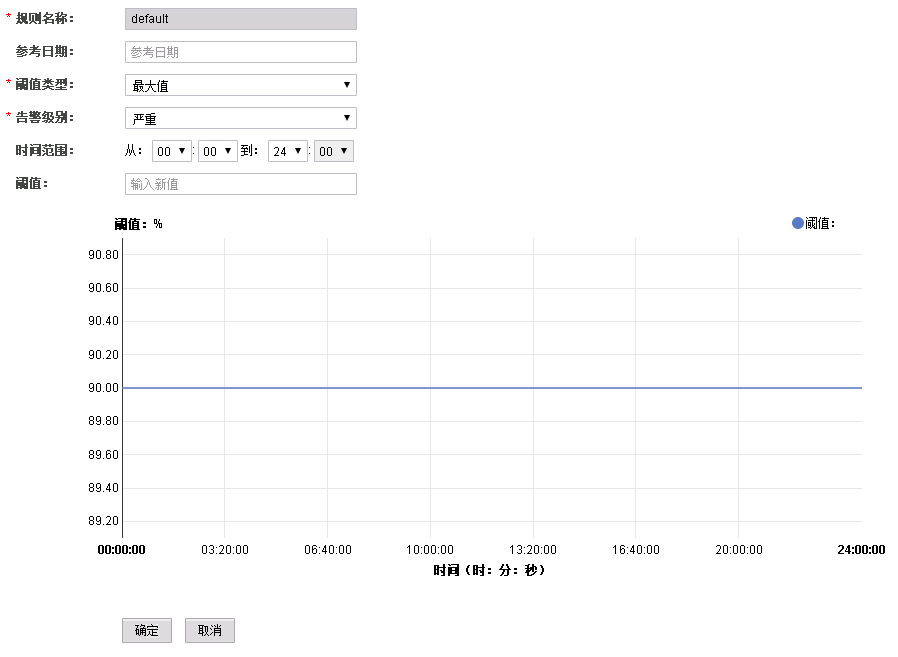
根据实际服务的使用情况在“系统设置 > 阈值配置 > 设备 > 主机 > CPU > CPU使用率 > CPU使用率”中更改告警阈值,如图2所示。
- 等待2分钟,查看告警是否自动恢复。
- 是,处理完毕。
- 否,执行步骤 3。
检查CPU使用率是否达到上限。
- 打开FusionInsight Manager页面,在告警列表中,单击此告警所在行,在告警详情中,查看该告警的节点地址。
- 进入“主机管理”界面,单击告警的所在节点。
- 在界面观察CPU使用率实时数据5分钟左右,若CPU使用率多次超过设置的阈值,请联系系统管理员提升CPU。
- 检查该告警是否恢复。
- 是,处理完毕。
- 否,执行步骤 7。
收集故障信息。
- 在FusionInsight Manager界面,单击“系统设置 > 日志下载”。
- 在“服务”下拉框中勾选“OmmServer”,单击“确定”。
- 设置日志收集的“开始时间”和“结束时间”分别为告警产生时间的前后10分钟,单击“下载”。
这篇关于大数据之LibrA数据库系统告警处理(ALM-12016 CPU使用率超过阈值)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




