本文主要是介绍【论文阅读】Cyro-EM数据处理软件Dynamo,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文:《Dynamo: A flexible, user-friendly development tool for subtomogram averaging of cryo-EM data in high-performance computing environments》
软件:
目录
- Abstract
- Keywords
- 1 Introduction
- 1.1 Cryo Electron Tomography and subtomogram averaging
- 1.2 Software for subtomogram averaging
- 1.3 Dynamo overview
- 2 Software concept
- 2.1 Procedure through the GUI
- 2.1.1 Project setup
- 2.1.2 Experiment design
- 2.1.3 Execution
- 2.2 Command line procedure
- 2.3 Complementary utilities
- 2.3.1 Project I/O
- 2.3.2 Error checking
- 2.3.3 Time planning
- 2.3.4 Help topics
- 2.3.5 Classification tools
- 2.3.6 Preprocessing tools. 预处理工具
- 2.3.7 Visualization tools
- 2.3.8 Data management
- 3 Basic algorithm
- 3.1 迭代优化
- 3.1.1 Refinement loop 细化循环
- 3.1.2 Selection
- 3.1.3 Averaging
- 3.2 Dynamo implementation
- 4 High-performance computation
- 4.1 Motivation
- 4.2 Categories of high-performance computing systems
- 4.2.1 Multicore machines 多核机器
- 4.2.2 CPU clusters CPU集群
- 4.2.3 GPU and multiGPU accelerators
- 4.2.4 GPU clusters GPU集群
- 4.3 Dynamo implementation
- 4.4 Coarse-grained parallelization: independent processing of particles 粗粒度并行化:粒子的独立处理
- 4.5 Fine-grained parallelization: FFT acceleration 细粒度并行化:FFT加速
- 4.6 Classification
- 5 Algorithm customization 算法定制
- 5.1 Motivation
- 5.2 Plugins
- 5.2.1 相似
- 5.2.2 后处理
- 5.2.3 迭代
- 5.3 Performance of user plugins
- 6 Case study: Borrelia flagellar motors 疏螺旋体鞭毛马达
- 6.1 Data collection
- 6.2 Alignment and classification
- 6.3 Numerical performance
- 7 Distribution and portability 分发和可移植性
- 8 Summary and outlook
Abstract
Dynamo是一个新的软件包,用于低温电子断层扫描(cryo Electron Tomography, cryo-ET)数据的子层析图平均,主要有三个目标:
- 首先,Dynamo允许用户透明地适应各种高性能计算平台,如gpu或CPU集群。
- 其次,Dynamo通过GUI界面和脚本资源实现了用户友好性。
- 第三,Dynamo通过插件API提供用户灵活性。除了校准和平均程序,Dynamo还包括用于可视化和分析结果和数据的本地工具,以及对第三方可视化软件的支持,如Chimera UCSF或EMAN2。作为这些功能的一个演示,我们研究了细菌鞭毛马达,并显示自动检测的类缺乏和存在的c环。
Subtomogram 平均是当前cryo-ET pipelines中常见的任务,需要大量的计算资源,并遵循完善的工作流程。然而,由于数据的多样性,许多现有的包提供了相同算法的细微变化,以改善结果。**Dynamo的主要目的之一是提供明确的工具,允许用户插入定制设计的过程(或插件),在subtomogram averaging 处理 pipeline 的不同步骤中替换或补充本地算法,而无需处理并行化的负担。**实现用户设计的新方法的自定义脚本被集成到Dynamo数据管理系统中,因此它们可以由GUI或脚本功能控制。
Dynamo可执行文件不需要第三方商业软件的许可。源代码、可执行文件和文档在http://www.dynamo-em.org上免费发布。
Keywords
Subtomogram averaging; Single Particle Tomography; High-performance computing; GPU computing; Classification
1 Introduction
1.1 Cryo Electron Tomography and subtomogram averaging
低温电子断层扫描(Cryo Electron Tomography, cryo-ET) 成像细胞的三维(3d)结构。在透射电子显微镜(Transmission Electron Microscope, EM)成像过程中,样品尽可能接近自然条件,并通过整合同一样品的不同视图构建描述细胞三维结构的最终计算模型。
虽然在典型的工作条件下,电子显微镜允许纳米尺度的特征分辨率,但构建的3d模型的图像质量受到不同的伪影的严重降低,例如缺失的楔形,以及由于有限的剂量而导致的低信噪比,以避免辐射损伤。因此,虽然细胞的粗糙特征——如膜和纤维——可以用肉眼识别,但如果不进一步处理,就无法可靠地恢复单个大分子结构的定量描述。
The subtomogram averaging technique (Forster and Hegerl, 2007, Winkler, 2007)旨在通过识别和平均相同大分子化合物的不同噪声副本中可以找到的共同信号来克服这些限制。这种与单粒子技术概念上的相似性也表现在使用相互关联作为主要工具来将数据粒子与质量不断提高的引用对齐。因此,当该技术应用于孤立粒子时,Subtomogram averaging 也通常被称为“单粒子层析成像(Single Particle Tomography)”。
1.2 Software for subtomogram averaging
(ps:都是2011年之前的软件,是否需要重点研究?)
Subtomogram averaging 正在成为 cryo-ET(低温电子断层扫描) 研究中越来越常用的工具。全面的软件包涵盖了层析数据分析的广泛方面,如采集、重建、可视化和颗粒拾取,通常包括对子层析图平均的支持,使用户可以在相同的环境中执行完整的处理流程。从这个意义上说, the TOM package 为AV3工具提供了一个框架,而 PEET 的 subtomogram averaging 工具可以从 IMOD 的一部分Etomo 获得。
jsubtomo 是在 Bsoft 的基础上开发的,它包含了自己的 subtomogram averaging实用程序(bfind), Protomo也是如此。SPIDER的RAMOS技术也是可用的。
其他包是特定于子层析图平均和解决新的算法方法。Bartesaghi 等人(2008)使用球面谐波公式来加速数值要求高的计算,Amat等人(2010)使用噪声统计模型来提高获得的分辨率。
最后,源自单粒子领域的成熟软件包现在包括子层析图平均任务的扩展。XMIPP包括ml_tomo工具(Scheres等人,2009年),该工具实现了同时对子层析图进行对齐和分类的最大似然方法(Stolken等人,2011年也采用了这种方法),而EMAN2 (Tang等人,2007年)现在基于Schmid和Booth(2008)中描述的算法,与特定的单粒子层析成像模块一起分发。
1.3 Dynamo overview
上面提到的许多包都实现了相同或非常相似的流水线来执行 subtomogram averaging。然而,它们并不总是易于使用,或者它们还没有准备好从可用的高性能计算体系结构中获益。最后,最佳的处理方法可能因样本而异,因此能够一次尝试不同的算法是有帮助的。
考虑到这一点,我们创建了Dynamo作为一个新工具。Dynamo执行 subtomogram averaging 计算,并支持新算法的开发。Dynamo将图形界面与命令行功能相结合,以实现三个主要目标:
1.3.1 User friendliness
1.3.2 High performance
1.3.3 Flexibility
2 Software concept
图1描述了在开始亚层析成像平均实验之前所需的数据处理步骤:倾斜序列的对齐、层析成像重建和层析成像中感兴趣粒子的近似位置的识别。为了获得高分辨率,可能需要额外使用CTF校正程序(Fernandez et al., 2006; Kudryashev et al., 2012; Xiong et al., 2009)。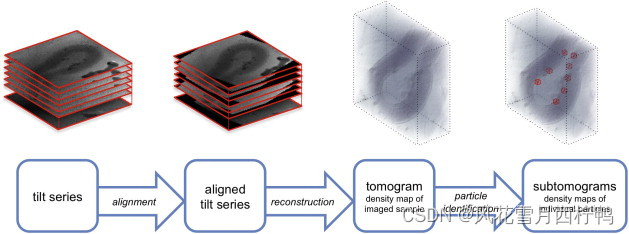
图1:所示 Preprocessing for subtomogram averaging。在开始进行subtomogram averaging之前对TEM数据进行处理。用透射电子显微镜从不同的方向对同一物体进行成像,可以得到一个倾斜序列。这是一堆投影图像,需要对齐,然后重建成断层图,以恢复三维信息。然后对层析图进行分析(目测或计算),以确定大分子化合物拟平均拷贝的大致位置。右面板中的红框表示以估计位置为中心的原始断层图的子体积,这些子体积将从断层图中裁剪出来以供进一步分析。一个典型的子层析图平均项目可能需要从大量的层析图中识别这样的数据粒子。所有提取的子卷的集合是Dynamo项目的输入数据。还可以传递额外先验信息的可用性,例如对粒子方向的粗略估计,以提高算法的性能。
Dynamo假定用户之前已经执行了这些步骤,并准备了一个包含所有粒子数据的文件夹,即从tomograms中裁剪出的子卷。
2.1 Procedure through the GUI
The main GUI 展示了项目所有方面的统一视图。如图2所示,附有从一组粒子中计算平均值的基本程序的草图。Dynamo将用户干预分为三个操作步骤(项目设置、实验设计和执行),我们将在下面简要讨论。手册中详细介绍了具体的指导方针和数据格式,以及一个示例合成数据集的演练,旨在让用户开始使用Dynamo操作。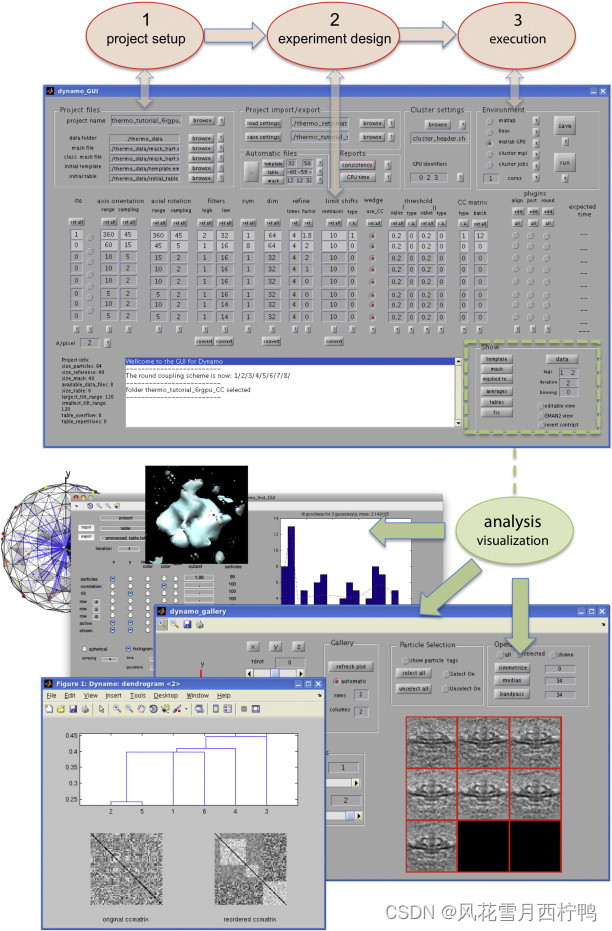
图2所示:Dynamo工作流。Dynamo GUI。双头箭头表示GUI中的不同参数输入区域与三个基本操作步骤的关系:(区域1)定义项目,详细说明所涉及的密度图在文件系统中的位置;(区域2)设计实验,用一组参数确定数据的数值处理,包括用户定义的插件;(区域3)在预期的计算平台上格式化和执行项目。绿色虚线矩形内的区域将GUI与不同的查看和分析选项连接起来。其他可从GUI访问的功能包括时间分析、项目一致性检查、存储项目管理和访问屏幕帮助。
2.1.1 Project setup
用户需要的最小输入是包含粒子数据的文件夹在文件系统中的位置。可选地,用户可以指示包含其他基本数据(例如初始引用、掩码或对齐参数的初始猜测)的文件。如果没有定义这样的文件,则将自动从默认值中获取相应的信息。
2.1.2 Experiment design
用户指示所需迭代的次数,并指定精确确定在每组迭代中将执行哪些操作的参数。这些参数可能控制所有粒子(角度范围和采样扫描,频率滤波,对称或粒子大小调整)的细化回路,或者可能修改构造更新参考所需的后验操作(粒子选择,分类,平均)。
此外,在Dynamo流中插入的用户定义函数的参数也可以通过main GUI传递。
2.1.3 Execution
用户选择用于执行计算的计算环境,详细说明将有多少 cpu 或 gpu 专用于该项目。有了这些信息,Dynamo自动将用户设计的项目解析为命令脚本,然后将其提交给计算环境执行,或者将其存储为稍后启动的更复杂项目的一部分。
2.2 Command line procedure
The main GUI 是新用户与软件的第一个接触点,提供了一种简单的方法来设计和监督实验。随着用户的经验越来越丰富,他们可能会设计出越来越复杂的实验,而这些实验可能不适合通过 main GUI进行独占性处理。这是系统任务的情况,例如设计和运行类似的项目,这些项目只是在某些参数的值上有所不同。
因此,Dynamo 的主要功能也作为独立的命令(MATLAB 函数或 Linux 可执行文件)提供,用户可以根据手册中指定的命令语法在自己的脚本中调用这些命令。
2.3 Complementary utilities
一些额外的实用程序可以从main GUI和命令行访问。
2.3.1 Project I/O
使用GUI,可以保存、浏览、重新加载和/或编辑项目。一旦在GUI中设计好,存储的项目就会变成一个独立的实体,被系统视为一个独立的命令。为以后编辑和插入到更复杂的脚本结构中提供了特定的工具。
2.3.2 Error checking
用户在向项目提供输入参数时所犯的错误可能会在运行时使软件崩溃,这将需要分析和调试。更糟糕的是,程序可能在没有崩溃的情况下完成计算,这将导致错误或非物理的结果。为了避免不必要的用户努力和计算资源的浪费,项目会自动检查不同类型的不正确或不连贯的格式或内容。更深入、更耗时的检查级别可以由用户手动请求。用户手册中描述了不同级别的错误检查。
2.3.3 Time planning
用户可以要求估计总的预期计算时间。这允许根据可用的计算资源调整项目参数,从而实现有效的时间管理。
2.3.4 Help topics
通过其内置的消息控制台,可以对GUI中的所有项目提供命令函数和参数含义的简短描述。在命令行中,系统继承了MATLAB工具箱的帮助功能,以目录和链接帮助主题的形式实现。
2.3.5 Classification tools
由于对傅里叶空间中缺失的楔形/金字塔的补偿被报道来确定分类方法的性能(Bartesaghi等人,2008年,Forster等人,2008年,Heumann等人,2011年,Winkler等人,2009年),Dynamo将一组MATLAB本地工具用于分层聚类(Ward, 1963年)和主成分分析(PCA) (Lebart等人,1984年),以适应层析成像项目的特定傅里叶采样几何特征。这些经过调整的工具被插入到Dynamo项目的管道中。
2.3.6 Preprocessing tools. 预处理工具
该软件包包括用于手动校准数据集的交互式工具,允许用户在可能的情况下创建对粒子的初始位置和方向的粗略估计。
2.3.7 Visualization tools
中间结果的图形分析对于调整迭代算法的进度以及对最终结果的正确解释至关重要。在单粒子分析领域,目视检查的重要性早已被认识到,它构成了典型工作程序的一个完善的部分,特别是在迭代的早期阶段。用户定期检查类平均和重投影或已识别粒子的角度覆盖的相似性,以评估最后计算步骤的质量,并收集信息以决定下一步的行动。
Dynamo包括不同的可视化工具,专门适应亚层析图平均的需要。图库视图是同时可视化密度图组的基本工具。在这里,用户可以在选定的粒子集或平均体积上交互式地执行不同的操作:对称化,根据给定迭代的结果对数据粒子进行对齐,过滤和同时可视化沿用户定义方向的选定正交切片的投影。从概念上讲,该工具结合了单粒子分析中通常需要的功能,即以图库形式对二维图像集进行视觉探索(由EMAN中的v2或v4查看器或xmipp_show命令实现),以及分析单个层析图所需的更广泛的3d操作(例如在Etomo和TOM软件包中的不同查看器中实现)。
另一个与粒子库查看器相连的图形工具,便于对迭代过程中生成的大量数值进行视觉探索和统计分析。该工具可以根据原始层析图中的位置,在不同的描述选项(如散点图、线性或球形直方图或空间分布)中显示计算出的相互关联系数、分类结果、粒子方向和其他用户自定义数量之间的相互关系。
最后,Dynamo还包含了EM社区中常用的自由软件所涵盖的功能包装器。特别是,UCSF Chimera (Pettersen et al., 2004)和EMAN2为体积的等面表示提供了快速而强大的工具。Dynamo生成宏,自动使用这些工具来完成在子断层图平均项目中经常出现的可视化任务,例如在连续迭代中产生的平均值的图库描述,或者断层图中粒子的位置。
2.3.8 Data management
通过子层析图平均技术对单个数据集进行分析可能会产生大量文件,这些文件描述平均值、几何结构、中间结果和其他信息,如FSC值、初始数据和参数、过程日志或可能的分类结果数据集。通常情况下,用户会用不同的参数进行几个实验,然后从中提取不同的信息,这些信息需要关联和分析以设计进一步的操作。概述对数据集执行的所有操作和获得的结果可能很麻烦。
Dynamo通过数据库组织其文件结构,并包含允许用户通过对该数据库进行显式操作来访问文件的工具。在交互式会话中,这意味着所有文件都可以通过图形浏览器或命令行工具轻松访问。数据库工具在脚本上下文中更有用,因为当用户将自己的脚本插入Dynamo的本地工作流时,它们为用户提供了处理数据I/O的健壮接口。
3 Basic algorithm
3.1 迭代优化
基于互相关优化的迭代细化是子层析图平均包中最常见的过程,也是 Dynamo的基础。我们引入一些符号来讨论这种方法的一般思想:所寻找的分子结构 p 的无噪声体积密度图被认为是实验数据集中粒子{di}i的共同底层信号。在最一般的情况下,每个di被认为是施加在p上的结果:(i)未知的刚体变换(移位和旋转),(ii)某种形式的噪声,以及(iii)在重建粒子时没有实验可用的傅立叶分量的损失(例如,由于所谓的“缺失楔效应”)。
迭代子层析图平均方法创建一系列估计q(0), q(1),…,以越来越高的精度逼近底层信号 p 。这种方法的一般单次迭代通常分为(最多)三个部分:
3.1.1 Refinement loop 细化循环
该算法独立访问所有粒子,并与迭代的起始参考进行比较。对于每个粒子,确定并存储优化其与参考相似度的几何变换参数。这部分迫使每个粒子的方向显示出信号的组成部分,这些信号在整个集合中是潜在的相干的。
3.1.2 Selection
当质量较差的数据粒子要被丢弃时,或者当实验人员对数据集的性质没有完全确定并且需要处理可能的构象异质性或不同粒子的存在时,这一步是必要的。这部分的目标是识别那些对共同信号有相干贡献的粒子。
3.1.3 Averaging
在这里,目标是通过将在前面步骤中执行和确定的相干贡献相加来增强信号。
3.2 Dynamo implementation
Dynamo的主要算法如上所述。除了这些在子层析图平均领域中众所周知的基本操作原则之外,还有一些其他不太广泛使用的元素已被纳入该软件的工作流程。它们的基本原理来自于动手实验和定性原理,这些原理来自于补充材料中的数学公式。在这里,我们只是列出并简要讨论最相关的要点。
-
使用局部归一化相关(locally normalized correlation)
默认情况下,Dynamo在比较模板和数据粒子时使用Roseman的快速方案(Roseman, 2003)将计算域限制在感兴趣的选定区域。 -
在细化步骤中搜索全局最优
在每个细化循环中,Dynamo试图通过搜索提供模板和粒子之间最优相似性的对齐参数来将粒子与模板对齐。在整个迭代过程的背景下,与跳过最优性约束的方法相比,该策略呈现出不同的数值性质,而不是在每次迭代中改进前一次迭代的结果。 -
通过双阈值或分类进行粒子选择
识别和表征数据集中的结构可变性和识别不一致的元素(“坏粒子”)是确保良好对齐的经常要求。相反,分类算法将在对齐良好的数据中表现更好,这是一个鸡生蛋还是蛋生鸡的问题,在电子显微镜数据的结构研究中众所周知,无论是在单粒子还是断层扫描应用中。
Dynamo通过在每次对齐迭代结束时将对齐粒子的协方差矩阵的计算纳入其工作流程来反映这种对齐和分类的交错。然后,使用该矩阵作为分类的基础(在PCA组件上使用k-means)也可以在单个迭代的管道中使用。然后,用户可以应用Dynamo的算法定制工具来设计一个策略,该策略使用该管道的结果来为下一次迭代选择、拒绝或重新组合粒子。
- 使用不同的空间蒙版进行对齐和分类
校准和分类虽然紧密相连,但却是不同的任务,它们以不同的方式利用信号,需要以不同的方式驱动。Dynamo将这种区别纳入其工作流程,区分与对齐相关的兴趣区域(通常由体积掩模定义)和与分类相关的兴趣区域。
这些点在它们的操作上下文中显示在图3中,图3描述了算法的一次迭代流程图。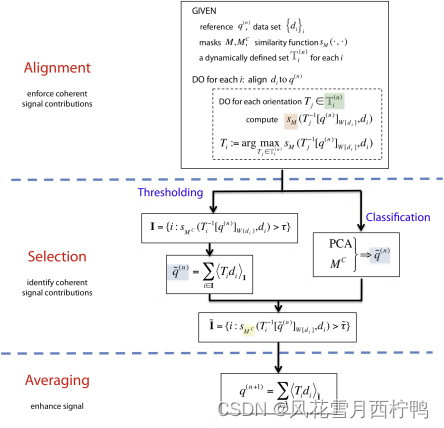
图3所示算法:单个迭代的流程图。更新引用的过程包括三个主要阶段。第一步是计算密集的细化循环,其中每个粒子分别与参考对齐。这种单独的对齐是由一组欧拉角上的内部循环执行的,面对粒子到不同的刚体转换的参考。在精化循环完成后,选择步骤解释计算的对齐结果,以识别更高质量的粒子来执行最后一步,即通过平均所选粒子来更新参考。在图中,带有彩色底层的元素展示了文本中广泛讨论的Dynamo流的特定方面,以及使用的符号。
4 High-performance computation
4.1 Motivation
电子显微镜(Electron Microscopy, EM)的三维图像处理往往需要大量的计算资源(Fernandez, 2008),亚层析图平均无疑是一个很好的例子。这种技术本质上依赖于计算密集型任务,因为需要分析大量(通常至少数百个)三维密度图,并且对每个三维密度图的分析包括体积数据的一系列旋转和傅里叶变换。此外,用分类技术补充精化过程的频繁需求甚至会产生更多的计算密集型算法。幸运的是,许多任务可以并行化以减少执行时间。
对高性能计算(high-performance computation, HPC)的需求也源于在子层析图平均过程中交互式评估的必要性。由于完全客观的方法尚不可用,该技术仍然不太可能以完全无监督的方式产生结果,并且对结果的正确解释通常需要比较在数据集上使用不同参数和算法变化的几次运行的软件的输出。尤其是在分析嵌入膜、拥挤的细胞质或源自厚细胞的蛋白质时,这一点是正确的,在这些情况下,成像条件下降和物体重叠会导致需要仔细控制结果的伪影。对于在玻璃化冰中含有相同大分子的分离拷贝的样品制备,情况更接近于单粒子技术的情况,在这种情况下,对用户干预的需求减少了,但肯定不是没有。
4.2 Categories of high-performance computing systems
近年来,高性能计算系统的普及程度不断提高。单个处理器的计算能力(摩尔定律)和通常集成在大规模计算装置中的计算单元数量的不断增加,伴随着高性能计算的新可能性的引入,例如GPU或Cell (Xu和Thulasiraman, 2011)处理器。此外,获得这些设备或设施的机会越来越普遍,其中一些设备或设施几乎是普遍的:
4.2.1 Multicore machines 多核机器
12核的台式机正变得越来越普遍,8核的机器也被广泛使用。四核笔记本电脑正在成为新型中档电脑的标配。
4.2.2 CPU clusters CPU集群
研究机构和大学经常托管不同规模的并行计算集群。此外,在许多国家,研究人员可以申请由国家研究委员会支持的大型计算设施的计算时间。
4.2.3 GPU and multiGPU accelerators
常规桌面通常提供图形卡,可用于通过CUDA (http://www.nvidia.com)或OpenCL等应用程序编程接口(api)加速计算。此外,供应商还提供专门用于计算的GPU设备。最新一代gpu包含了全方位的计算能力,旨在使基于gpu的数值应用程序的功能在硬件层面(例如双精度浮点计算能力)和软件层面(例如广泛的数学库)上接近cpu所提供的功能。这种设备的种类包括多gpu配置,其中一台机器控制几个gpu。
在最近的过去,GPU计算已经引起了极大的关注,作为集中式CPU集群的廉价替代品。在电子显微镜中,这种兴趣已经转化为几个软件包,特别是单粒子技术(Li等人,2010年,Schmeisser等人,2009年,Tagare等人,2010年,Zhang和Zhou, 2010年),以及用于迭代重建程序的断层扫描(Castano Diez等人,2007年,Palenstijn等人,2011年,Xu等人,2010年,Zheng等人,2011年),倾斜序列的无标记对准(Castano-Diez等人,2010)和其他一般的三维图像处理任务(Castano-Diez et al., 2008, Gipson et al., 2011)。尽管取得了这样的进展,但与基于cpu的同类产品相比,目前可用的支持gpu的软件包仍然不多。
4.2.4 GPU clusters GPU集群
一些超级计算中心在它们的“经典”CPU内核中集成了附加在一个或多个gpu上的额外内核。这一有趣的进展不仅提高了可以分布在多个GPU之间的应用程序的潜在加速,而且还使没有资源购买或管理此类设备的用户可以使用高端GPU设备。
高计算资源的可用性很少成为其应用的限制因素。出于实际目的,更常见的限制是特定任务的适当工具的可用性和可用性,因为软件必须专门适应每个平台。这一步骤可能包括主要的代码重写,以使原始算法适应不同的体系结构需求,以及在代码中集成通信协议。
4.3 Dynamo implementation
Dynamo遵循不同的策略来适应上述所有超级计算平台。这种差异对用户是透明的,用户为所有的计算目标操作一个统一的界面。在内部,该包利用了两种不同的方式,其中先前描述的迭代算法可以加速,参见图4中的方案。
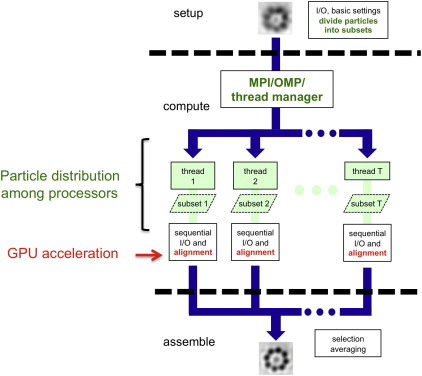
图4:并行化。
两种加速设置。在细化循环的开始,数据被分发到将分别对齐的集合中。Dynamo使用不同的计算设备来控制这种级别的并行执行:MPI(大型cpu或gpu集群)、OMP(多核)或Pthreads(多gpu)。此外,如果GPU设备可用,它们可以用来加速每个粒子的对齐,与单个CPU的类似计算相比,通常是10-20倍。
4.4 Coarse-grained parallelization: independent processing of particles 粗粒度并行化:粒子的独立处理
所有粒子与给定参考点对齐的循环属于“令人尴尬的并行算法”的范畴。这意味着算法的大部分是由任务组成的,这些任务可以在没有任何通信的情况下执行。
当开始一个循环时,Dynamo将标记为进一步处理的粒子分布在均匀分布的集合中,因此每个集合可以分配给不同的处理单元。这种方法适用于在大规模集群中的不同cpu之间、在服务器中的不同内核之间、在“多gpu系统”中的不同gpu之间(不同gpu安装在单个节点上)或在集群中安装在不同节点上的不同gpu之间分配任务。(Xu and Thulasiraman, 2011)。
对于cpu或gpu的大规模计算集群,提供了一个语法解析设备来指导用户调整Dynamo以适应操作其集群的排队系统使用的特定语法。这个设备分析一个典型的提交脚本,格式化后的排队系统的要求,并通知Dynamo如何创建相应的脚本。示例和具体步骤在Dynamo手册和Dynamo网站的FAQ(常见问题)部分中有详细说明。该设备已经过PBS和SGE排队系统的测试。但是,排队系统命令的语法非常依赖于系统管理员的设计决策,这可能会导致需要对解析设备进行微小的调整。
完成这些步骤后,任务分配将透明地发生给用户。在内部,多核计算由OpenMP(开放多处理器,(Chandra, 2001))接口驱动,而集群节点之间的任务分配通过MPI(消息传递接口,(Pacheco, 1997))来利用。
4.5 Fine-grained parallelization: FFT acceleration 细粒度并行化:FFT加速
此外,通过使用GPU加速对齐一个粒子所需的操作,可以获得显著的加速。在旋转参考点并将其与粒子进行比较的过程中涉及到不同的步骤,但最密集的计算是三维快速傅里叶变换(FFT3D),然后是旋转步骤。因此,整个算法可获得的最大有效加速是由硬件加速器、驱动程序和算法组合为FFT3D提供的最大加速给出的。当将计算从台式计算机的一个CPU移动到其GPU卡时,计算的小步骤(最大查找,标量积,归一化)可以获得高达100倍的加速因子(Castaño-Díez et al., 2008),目前由NVIDIA供应商为其图形卡的CUDA计算接口提供的CUFFT库中的FFT3D实现通常在子断层图平均应用程序(边长在32到128像素之间的体积)中发现的体积大小通常达到7 - 20倍的加速范围,这对单个当前可用的GPU系统所能达到的加速施加了上限。边长为256像素或以上的粒子体积很少被报道。表1显示了在120个粒子和不同扫描方向数的一次对齐轮上,对边长为32、64和128像素的粒子盒使用多gpu设置获得的加速因子。该表反映了应用于不同大小数据的GPU应用程序性能的一般特征。对于小尺寸的数据,如果启动GPU计算的开销与计算本身相当,则测量的性能将趋于下降。另一方面,大数据量也会降低性能,因为当应用程序试图以最佳方式布局GPU内部内存时,大量数据会造成困难。在我们在现实条件下的测试中,在当前GPU硬件和GPU接口协议下,边长为64像素时出现了最佳加速因子。
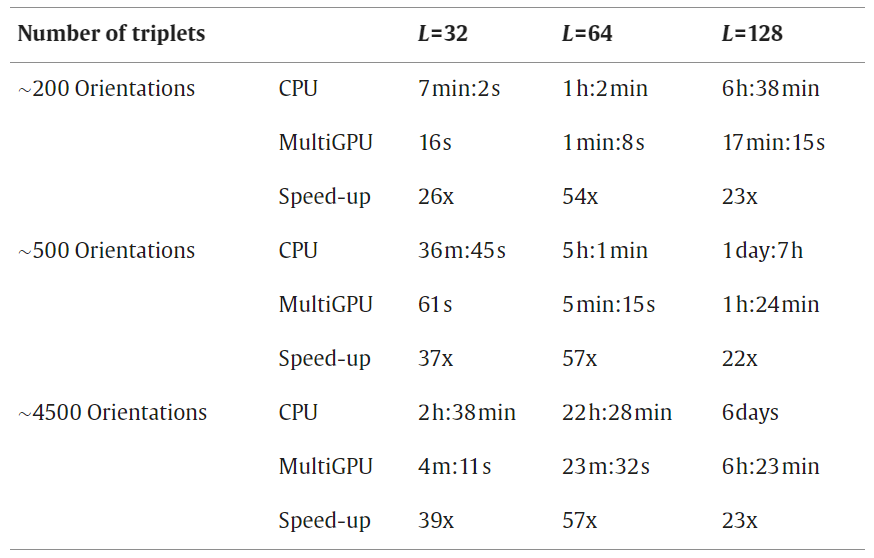
表1:在120个粒子的数据集上,对于不同角度的采样和不同的粒子大小,单次迭代的加速因子。L为每个粒子的边长(以像素为单位)。在一台3xC1060 Nvidia机器上获得了多gpu显示的时间。在AMD飞鸿9950四核处理器中计算单个线程的CPU时间。
从开发人员的角度来看,GPU应用程序的设计重点是确保算法不同部分之间的数据流不会产生瓶颈,从而阻止实际实现名义上的7 -20倍加速因子(Castano-Diez et al., 2010)。Dynamo实现恢复了单个gpu的这个加速因子,并且几乎与可用gpu的总数线性扩展,无论是多gpu设备(安装在单个服务器上的几个gpu,通过CUDA线程管理系统连接)还是gpu集群(不同的gpu安装在不同的计算节点上,通过MPI协议连接)。
4.6 Classification
在完成所有粒子的细化循环后,Dynamo提供了一个选项来计算和存储根据计算参数对齐的粒子之间的关联矩阵。该矩阵可用于集成在Dynamo流程中的不同分类方法(PCA和Hierarchical Ascendant),或用于用户自定义方法。
根据实验参数的不同,算法的分类部分的计算量会变得非常大。相关矩阵中独立元素的数量与粒子数量的平方成比例(对于一个有N个粒子的set组,相关矩阵包含 (N2+N)/2 - N 个独立元素)。如果 τcorrelation 是计算单个元素期间所花费的时间,则计算相关矩阵所消耗的总时间将按比例缩放为:
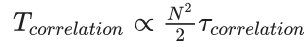
为了进行比较,在细化循环期间消耗的总时间为:
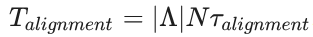
其中τalignment是计算一个欧拉角三元组的参考点和一个粒子之间的相似性值所花费的时间(平移对准是通过傅立叶相关定理计算的),并且|Λ|是一个粒子要测试的欧拉三元组的总数。对于大粒子集,如果N接近 2|Λ| · (τalignment / τcorrelation ) 的数量级,Tcorrelation变得可比或大于Talignment。这意味着在优化循环阶段获得的任何加速都将变得无关紧要,因为矩阵计算阶段将成为算法的瓶颈。
为了避免这种情况,Dynamo提供了以并行方式执行相关矩阵计算的可能性。该方法类似于前面讨论的循环并行化方法,尽管稍微复杂一些,因为要在处理单元之间均匀分布以确保良好的负载平衡的实体是与粒子对相关的矩阵元素,而不是单个粒子。这需要在精化循环期间不需要的小程度的任务合作。
5 Algorithm customization 算法定制
5.1 Motivation
除了它的主要算法,Dynamo还为用户提供了一个灵活的工具来测试和使用他们自己的子层析图平均方法。因此,使用GUI进行实验设计或在并行集群中的处理器之间透明地分配任务等实用功能直接继承,而不需要用户在GUI设计或并行计算方面进行任何特定的努力或技术知识。
对于想要设计和测试自己想法的用户来说,这是一个合适的框架。一般来说,评估由轻微的算法变化产生的真实分辨率增益需要用户将他或她的修改插入到完整的亚层析图平均程序中。为这个目标从头开始编写一个完整的包可能是一项不成比例的工作。即使将这种修改插入到现有的第三方代码中也可能存在问题。非计算专家禁止使用这种方法,而且经验丰富的软件开发人员还需要了解初始软件的内部流程。最后,用户预期的更改可能与初始包的内部结构不兼容。Dynamo结合了用户友好的算法扩展的特定工具,以克服这些限制。
5.2 Plugins
显然,并非潜在用户设计的每种可能的行动方案都可以作为给定特定算法的选项。GUI更不能提供传递参数的支持,特别是如果要保留实验设计的紧凑的视觉表示。
相反,Dynamo的方法是在其流中定义插入点。这些是单个迭代的处理管道的选定部分,可以用自定义功能替换或补充。当设计一个完整的实验,通常包含几个迭代时,用户可以完全控制哪些自定义修改将在哪些迭代中进行操作。自定义函数的参数作为本机Dynamo参数传递,可以从GUI传递,也可以通过脚本传递。
在创建自定义插件的阶段,用户需要准备可执行文件,这些可执行文件将参数和结果从文件系统中读写到与一般Dynamo工作流程一致的位置。这种插入所需的具体格式和约定在GUI的帮助功能中有说明,并在手册中有详细说明。这些可执行文件除了符合Dynamo的I/O语法外,没有任何设计限制,因此它们可以用用户感觉舒服的任何语言编写(MATLAB, c++, Fortran,…),并且可以包含来自其他包的工具,如SPIDER, Xmipp, Bsoft, TOM…
当前的Dynamo发行版已经包含了一些插件。它们的目的不仅是扩展主要算法的能力,而且还提供示例来指导用户构建自己的插件。图5给出了Dynamo中不同插入点的示意图。
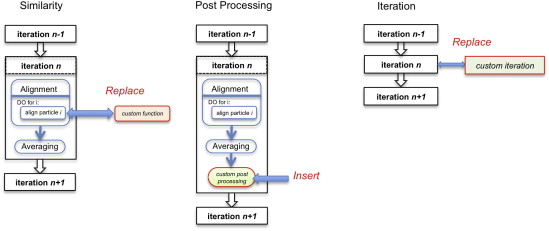
图5:Plugins
Dynamo插件。插件允许使用适应特定实验的自定义脚本。在任何设计的实验中,每次迭代都可以通过三种不同的方式分别进行修改:(左)自定义的相似度准则可以取代改进循环中本地归一化的相互关系;(中)在完成精化循环并对排列的粒子进行平均后,可以执行额外的后处理步骤;(右)一个完整的迭代可以用不同的方法完全替代。虽然相似性和后处理插件可以在同一轮中组合,但迭代插件排除了在同一轮中使用任何其他插件。
5.2.1 相似
这个插入点允许测试不同的方法来处理缺失的楔形,不同的算法来数值优化方向和平移搜索,应用直接空间掩模的替代方法,甚至是不基于相互关联的相似性测量。
5.2.2 后处理
在完成一个完整的迭代之后,即在对齐循环中访问了所有数据粒子并创建了一个新模板之后,用户可能仍然希望尝试引入一些后处理步骤。例如,提供了用于强制新计算平均值的螺旋对称的插件。
这个插入点也是在迭代中嵌入分类方案的自然框架。在这里,用户可以插入他/她自己的分类方法,并利用本机提供的选项来计算对齐粒子的相互关联矩阵。提供的插件示例基于PCA和分层聚类执行这种分类。
5.2.3 迭代
这提供了更深层次的算法灵活性:整个迭代可以用完全不同于主要Dynamo方法的算法来执行。Dynamo包括一些示例插件,它们插入对其他子断层图平均包的调用,格式化它们以使它们的输入和输出适应一般的Dynamo流。
5.3 Performance of user plugins
相似插件由Dynamo的MPI控制器干净地管理,而不会损失性能。在实践中,该功能允许用户在没有任何MPI知识的情况下测试她或他自己的大规模并行集群中的粒子对齐算法。
GPU计算提供的灵活性较差。Dynamo内部使用了两种完全不同的细化循环实现。一个版本在所有计算平台上运行CPU操作:使用相同的脚本集在单核、多核(共享内存系统)或并行集群(分布式内存系统)中执行计算,仅更改利用不同数据子集分布及其并行处理的API。这个版本是基于matlab的,高度模块化。
目前可用的GPU技术无法在不导致严重性能损失的情况下支持这种级别的灵活性。出于这个原因,虽然后处理插件不受影响,但目前交付的GPU版本不允许直接插入相似插件。但是,源代码和编译指南是为希望重用代码来实现自己的算法变体的gpu经验丰富的用户提供的。
6 Case study: Borrelia flagellar motors 疏螺旋体鞭毛马达
为了说明Dynamo在真实数据上的性能,我们在这里提出了一个关于螺旋体疏螺旋体鞭毛马达的案例研究,细菌利用它来产生鞭毛丝的旋转,从而导致细菌游泳(Kudryashev等人,2010)。
这里报告的所有分析步骤都是用Dynamo工具完成的:预处理、对齐、分类、可视化和最终的体绘制。
6.1 Data collection
该数据集包含从层析图中提取的138个粒子,如之前(Kudryashev et al., 2009)所述。简单地说,将3微升含血清和不含明胶的BSK培养基中的螺旋体伯氏疏螺旋体转移到EM碳网格上,孵育5-10分钟。去除多余的液体后,迅速将网格浸入液体乙烷中。栅格安装在Gatan冷冻机中,在配备场发射枪和Gatan柱后能量过滤器的飞利浦CM300电子显微镜中成像。在2k × 2k像素的Gatan CCD相机上,以43,000倍(0.82 nm/像素)的倍率,物镜欠焦10微米,记录了累计剂量低于20,000 e/nm2的累计剂量为2度增量的60-65幅低剂量图像的倾斜系列,并进行了零能量损失滤波。倾斜序列由基准金标记对齐,层析图由Etomo加权后投影生成(Kremer等,1996)。从非盒状层析图中手动提取粒子到128 × 128 × 128像素的盒子中。
6.2 Alignment and classification
前面提到的研究暗示了该数据集中可能存在的种群多样性,这表明马达的c环可能在很大一部分颗粒中缺失。我们开始确认这一观察结果,重新重复了原始分析的一部分,并补充了额外的处理步骤。在这里,整个过程包括三个步骤:
- 整个数据集的联合对齐 Joint alignment of the entire data set
通过将粒子的轴线正常地指向细胞膜,人工将粒子对齐。这些大致排列的粒子被加在一起,以提供一个初始模板,用作迭代排列循环的种子。在这个过程中,我们总共使用了16次迭代,分为两轮。前8个是用分组粒子操作的(得到64 × 64 × 64体素的立方体)。粒子和旋转模板之间的相关性被扫描为~ 700欧拉三元组,分布在六个网格级别,增加角分辨率,如补充材料中解释的那样。最粗糙的角度网格允许粒子轴从之前的位置漂移最多60°。第二轮8次迭代是在非分组粒子(128 × 128 × 128)上进行的,在一组更精细的~ 800欧拉三组中进行扫描,其中最粗糙的网格允许最大5°的角漂移。对于这个更精细的分布,完成了8次迭代,尽管在第二次迭代之后改进非常少。在此过程中没有应用阈值。在每次对齐迭代结束时获得的平均值上施加C16对称性,以便将它们用作下一轮的种子。
对于这16次迭代后的最终结构的构建,将表现出最佳相关系数的50%的粒子进行平均。图6a,是得到的密度的主要元素的表示,经过C16对称拼版。定子为红色(标记为z定子的平面周围),c环为绿色(标记为zc环的平面周围)。暗黑色密度代表膜。
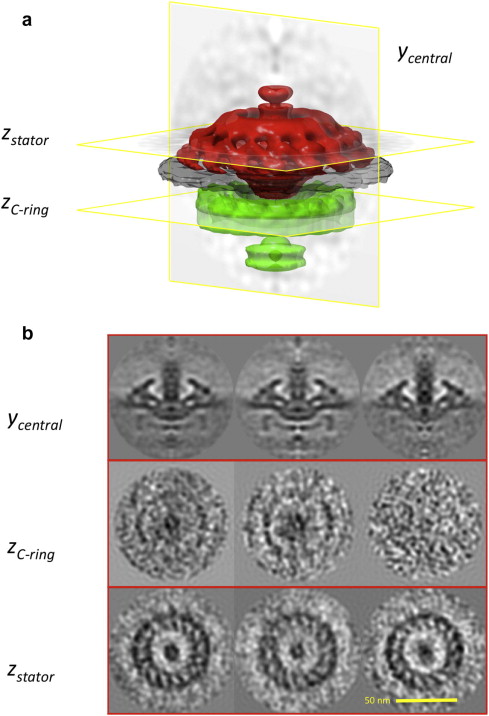
图6
应用示例:疏螺旋体数据集。在实际数据集上测试了对齐和分类任务的性能。a是(c16对称)伯氏螺旋体电机的等值面表示。每个标记切片(CCCC)按此顺序对应于面板b中的一行。其中,第一列表示之前对任何分类步骤获得的平均值。第二列和第三列表示对分类得到的两个类进行细化得到的密度。中心列的类似乎聚集了带有c环的粒子,而右边列的类已经失去了c环,但显然保留了结构的其余部分。请注意,沿y(上行)的视图是对称的,而在两个z视图(中央和底部行)中,感兴趣的特征是可识别的,没有对称。
- 排列粒子的分类 Classification of the aligned particles
通过前一步获得的平均值的目视检查表明,与C-ring相关的密度不如定子明确。如图6b所示,在该面板的第一列中。在这里,最上面一行是对称平均值的中心y截面(如图6a所示为ycentral)。本列中、下两行为切片a zstator为zCring的密度分布。这种表示没有使用对称。
鉴于这些结果,与(Kudryashev et al., 2010)中描述的观察结果一致,我们对排列的粒子进行了分类。这个过程包括三个步骤:
a. 计算粒子的协方差矩阵(考虑到不同的缺失楔)。为了计算矩阵项,对单个粒子进行了对称处理。此外,为了将每对粒子的互相关计算限制在c环周围区域,还使用了局部分类掩模。
b. 根据得到的矩阵进行主成分分析。鉴于特征值的急剧衰减(未显示),仅计算了五个特征体积。每个粒子在特征向量的基础上被它的五个系数替换。
c. 用扩展系数表示的数据的K-means分类。为了评估不同随机种子产生的结果,这个计算成本不高的步骤重复了几次。
类平均的定性检查显示,与步骤i中获得的联合平均相比,C-ring中具有或多或少明确定义强度的类和C-ring变得模糊的类。在这一步中,我们明确检查了类成员与粒子的方向无关。这对于确保分类算法实际上是根据它们的结构内容对粒子进行分组,而不是根据它们缺失楔进行分组是很重要的。
- Independent alignment of relevant classes 相关类的独立对齐
为了证实这一观察结果,从数据中提取了两个粒子子集并独立对齐。第一个子集由来自类的粒子组成,这些类的平均似乎保持一个c环。我们在这里选择了40个与第一步产生的平均值具有最佳相互相关系数的粒子。第二子集以类似的方式构建为没有c环的类别。
然后,我们允许每个子集迭代进化,而不受来自其他子集的可能不相干信号的干扰。提供各自的类平均值作为起始参考,然后执行8次细化迭代。结果显示在图b的中间和右边的两列。中间的一列显示,保留c环的班级能够稍微增强其周围的信号,如上图所示。右列显示了分配给具有模糊c环的类的粒子得到的细化。事实上,c环已经消失了,而结构的其余部分仍然存在。
6.3 Numerical performance
在包含三个Tesla C1060 gpu的多gpu系统上进行了相关的对齐计算。在步骤(i)中,对整个数据集进行对齐所需的计算时间为对binned粒子进行8次迭代的1 h 02 min,对binned粒子进行接下来的8次迭代的20 h。有了这些角度采样设置,单个CPU对齐整个数据集所需的计算就可以通过使用相同角度设置对齐单个粒子时测量的实际时间来推断。这产生了分组颗粒约65 h和未分组颗粒约21天的估计,与表1中所示的加速因子密切一致。在步骤iii中重复此协议,其中迭代地改进两个类,在多gpu系统中消耗~ 9小时(或在单个CPU中估计为~ 8天)。
因此,在3倍Tesla C1060多gpu系统上,整个过程花费了30小时,而在单个CPU上的总计算时间估计为34天。值得一提的是,没有实现特定的停止准则,并且迭代过程的迭代次数比实际需要的迭代次数要多,以获得定性相似的结果。
7 Distribution and portability 分发和可移植性
不需要商用第三方软件的许可证。虽然Dynamo的主干是在MATLAB中创建的,但Dynamo既可以作为MATLAB脚本分发,也可以作为Linux或OSX平台的预编译可执行文件分发。从Linux/OSX shell启动和操作Dynamo不需要许可。
想要在MATLAB环境(Linux、OSX或Windows平台)中使用Dynamo的用户将需要MATLAB本身的许可证。对于某些功能,这些用户还需要图像处理和曲线拟合工具箱的许可证。
由于MATLAB或自由分发的MATLAB Compiler Runtime (MCR)设备用于基于linux的操作,提供了对广泛的辅助任务的支持,将对外部库的依赖性降低到严格的最低限度,从而确保了软件在不同平台上的高度可移植性和稳定性。依赖关系只与利用加速设备所需的库相关:用于集群的MPI,用于多核计算的OMP和用于gpu的CUDA(3.2版本)。
该软件可通过网站http://www.dynamo-em.org免费获得。
8 Summary and outlook
Dynamo为子层析图平均提供了一个全面的工具。它的设计便于在所有常用的计算资源类型上进行操作。Dynamo的插件系统代表了该软件包的巨大增长潜力。它能够适应新的算法开发或特定任务的全套能力,而无需主要的编程工作,也没有向后兼容性问题。软件包的新扩展将作为不需要重新安装软件的实用程序库发布。由于这种算法灵活性和包健壮性的结合,Dynamo可以提供一个有价值的工具来促进用户之间的思想交流和测试。
虽然操作协议和算法骨干旨在保持稳定,但未来可能会修改不同计算平台的实现细节,以调整软件的性能以适应新的技术发展。
目前实现的细化循环的粗粒度并行化机制适应了当前算法的需要,其中每个粒子所消耗的时间预计大致相等,因为每个粒子测试的角度数量相同。在这种假设下,为每个可用的处理单元预先分配相同数量的粒子是一种适当的负载平衡策略。如果进一步的算法发展导致粒子对齐方法引入负载不平衡,因此不同的粒子将需要不同的计算时间(例如,如果某些粒子需要针对比其他粒子更多的角度进行测试以获得给定的公差),那么在计算期间有效地使用所有处理器将成为必要的不同方法。这样的新方法可能会从具有共享内存的多核系统中获益更多,在这些系统中,当前的任务分配策略似乎不是最优的。使用其他并行化设备,例如Posix线程(Butenhof, 1997),也可能导致Dynamo在这类平台上的性能改进。
Dynamo的GPU功能的软件架构在未来可能会有很大的变化。虽然cpu上并行计算的基础似乎已经稳定地为当前的api奠定了基础,但GPU计算是一个快速发展的领域,工具和接口的更新速度很快。特别是,MATLAB正在通过CUDA包整合完整的GPU支持。我们期望未来的发展将为Dynamo中GPU工具的灵活性增加做好准备,允许它们完全集成到插件系统中,而不会降低它们当前的性能。
从实用的角度来看,进一步的GPU工具的维护和开发是很重要的,因为我们的案例研究表明,图形加速设备的使用减少了典型的计算时间尺度,用于分析典型的、相当大的子层析图平均问题,从几天到几个小时。
这篇关于【论文阅读】Cyro-EM数据处理软件Dynamo的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







