本文主要是介绍清华大学利用可解释机器学习,优化光阳极催化剂,助力光解水制氢,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
水的太阳能光电化学 (PEC) 分解是将太阳能高效转换为氢能的方法,是一种很有前景的可再生能源生产方式。然而,受电极性质及电极缺陷的影响,PEC 反应的效率较低,需要合适的助催化剂辅助。而电解池、光电极和助催化剂组成的 PEC 系统非常复杂,参数繁多,系统优化成本很高。为此,清华大学的朱宏伟课题组利用机器学习,对 BiVO4 光阳极系统进行了优化。机器学习可以基于以往的实验数据,找出光阳极、助催化剂和电解池之间的关系。同时,可解释的机器学习能够识别出对反应性能最重要的参数,为系统优化提供指导。
作者 | 雪菜
编辑 | 三羊
本文首发自 HyperAI超神经微信公众平台~
太阳能光电化学 (PEC) 分解水是将太阳能高效转换为氢能和氧气的方法,是一种很有前景的可再生能源生产方式。
PEC 分解水需要一个光电极,充当电解池的阳极或阴极,而对电极作为电解池的阴极或阳极。光电极吸收太阳能,驱动水的氧化或还原反应,对电极上同时进行与之对应的还原或氧化反应。促进光生载流子的分离,还需要一个电源或光伏电池,为 PEC 提供偏压。

图 1:PEC 分解水流程示意图
PEC 分解水的效率受制于光电极的缺陷,如载流子在低偏压下的复合和不稳定性。而合适的助催化剂可以促进光载流子的分离,与光电极形成异质结并促进光吸收、降低表面能加速反应、抑制电极的化学腐蚀、加速电子传输等,提高反应效率。
研究人员已发现多种可以促进 PEC 反应的助催化剂,包括金属、金属氧化物、无金属助催化剂、双催化剂等。这些助催化剂的效率受其物理化学性质影响,如化学组成、形貌、晶型等。此外,电解池的反应条件如电极类型、电解液浓度、pH 等,也会对助催化效率有影响。
反应系统十分复杂,如何针对给定的光电极进行参数优化、选择合适的助催化剂,需要大量的试错实验。尤其是助催化剂的最佳厚度,会受到电极和助催化剂的双重影响,很难选择。然而,如果有足够的数据,机器学习可以迅速实现这一过程。
基于此,清华的朱宏伟课题组利用机器学习 (ML, Machine Learning),优化了 BiVO4 光阳极的助催化剂。首先,讨论了光阳极催化系统的基本影响因素和机制。随后,基于先前研究的实验数据创建数据库,训练机器学习模型,找出 BiVO4 光阳极、助催化剂和电解池之间的关系。最后,基于机器学习模型的可解释性,找出与反应效率联系最密切的特征,以此指导 BiVO4 光阳极助催化剂的选择。这一成果已发表于「Journal of Materials Chemistry A」。

这一成果已发表于「 Journal of Materials Chemistry A」
论文链接:
https://pubs.rsc.org/en/content/articlelanding/2023/TA/D3TA04148D
实验过程
数据集 文献调研
机器学习模型的输入为 12 个反应影响因素及电极面积,输出为 1.23 V (vs RHE ) 下的光电流密度提升。
从 84 篇文献中,找到了 112 组 BiVO4 光阳极催化水分解的实验数据,组成数据集。值得注意的是, BiVO4 光阳极的形貌被简化为 4 类,包括单晶、纳米虫、随机堆叠和致密薄膜。而助催化剂的形貌被简化为 3 类,包括均质膜、单层膜和分离膜。
模型的输出,即助催化剂对光电流密度的提升,被分为 3 个层次:低 (0)、中 (1)、高 (2)。

图 2:影响 PEC 反应效率的因素及助催化剂的形貌
数据处理 筛选与降维
数据收集完成后,对数据进行预处理,包括以下 7 个步骤:
1、数据清洗 (Cleaning)。数据清理是数据校正、修复和清除的过程。有 25 组数据由于不具代表性被排除;
2、数据插补 (Imputation)。很多研究提供的数据相当有限,且不同研究的数据之间缺乏连续性。因此,研究人员基于反应条件、光阳极形貌和尺寸,通过链式方程多重差值 (MICE),补充了缺失的助催化剂厚度;
3、数据分区 (Partition)。70% 的数据集被划分为机器学习模型的训练集,30% 用于测试。由于数据量有限,研究人员使用了 K-Fold 交叉验证,以验证模型的准确性;
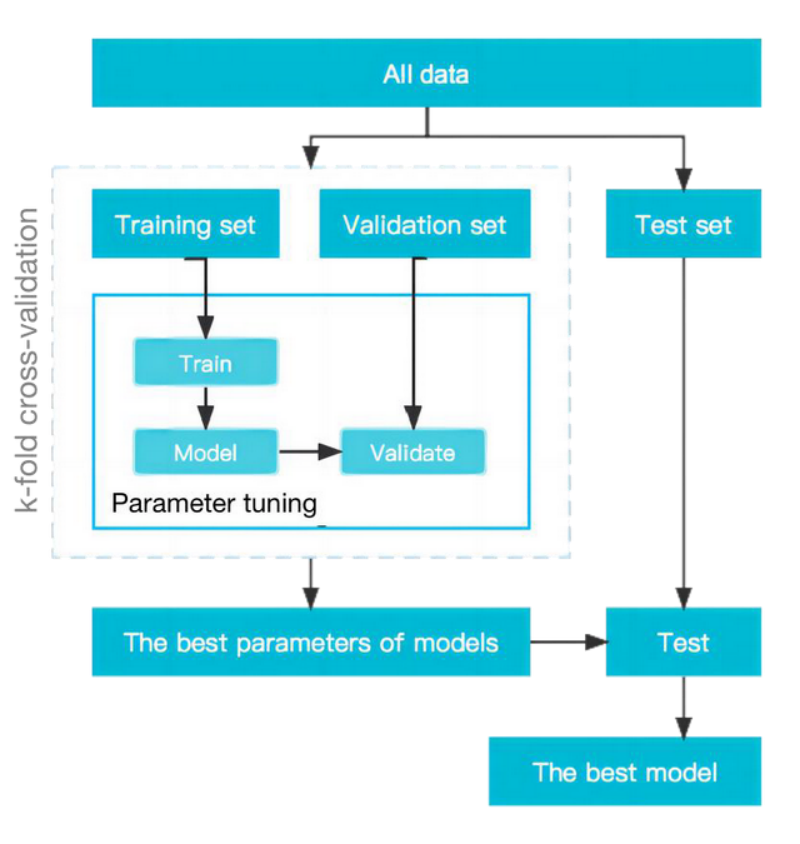
图 3:数据分区流程图
4、数据转化 (Conversion)。这一过程是将数据集转换为模型可读的集合。使用独热编码 (One-Hot Encoding) 将分类数据转换为数值数据后,输入变量有 109 个维度;
5、数据归一化 (Normalization)。数值数据范围不一致时,需要通过归一化将数据转换至同一范围,使得不同输入变量在集合中权重相同。本研究使用 StandardScaler 进行数据归一化;
6、数据平衡 (Balance)。本研究中,不同输出类别的数据分布明显不平衡,其中 0 约占 34%、1 约占 52%、2 约占 14%。常用过采样和欠采样方法对样本进行再处理,前者是在小样本集合中增加数据,后者是在大样本集合中删除数据。本研究使用 SMOTE 过采样算法进行数据平衡;
7、数据降维 (Dimensionality Reduction)。数据降维是在尽量保留数据信息的同时,降低数据的维度,以简化模型,避免过拟合。数据降维的常用方法包括特征选择和特征提取。
模型构建 神经网络 + 树模型
本研究使用的神经网络包括两个隐藏层,第一层的神经元数量在 8-96 之间,第二层在 0-96 之间。模型的超参数组合通过随机搜索 (Random Search) 和贝叶斯优化 (Bayesian Optimization) 进行自动优化。
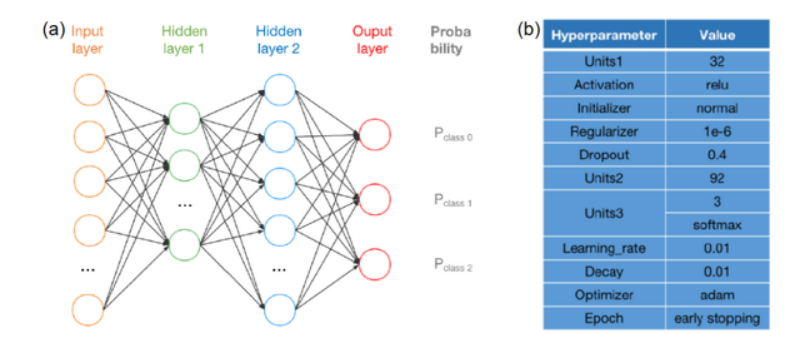
图 4:神经网络示意图 (a) 及最优超参数 (b)
此外,研究人员还对比了 4 种树模型算法的表现,包括并行的 Bagging 算法和随机森林 (RF, Random Forest) 算法、串行的 AdaBoost 算法和梯度提升 (Gradient Boosting) 算法。
模型的评价标准包括准确率、精确率、混淆矩阵、F1 分数、召回曲线及 AUC。
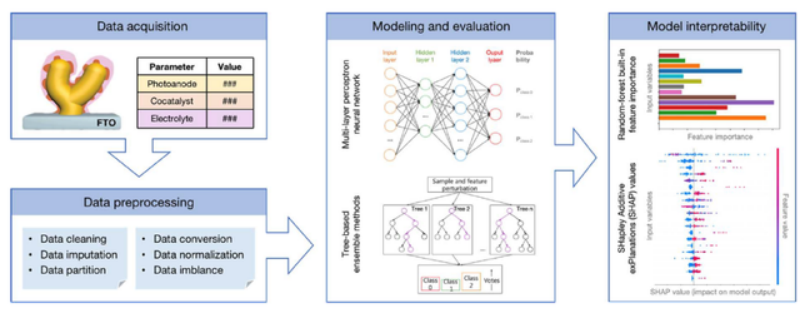
图 5:本研究的工作流
可解释性 SHAP
可解释的模型有利于帮助人们理解机器学习模型的决策过程。提高模型可解释性主要有两种技术:内在的可解释性 (Intrinsic Interpretability) 和事后的可解释性 (Post-hoc Interpretability)。
前者可以通过自解释 (Self-explanatory) 模型实现,如线性回归、逻辑回归和决策树等。这种方法可解释性强但准确率较低。后者通过代理模型 (surrogate Model) 来解释现有的模型,如集成方法、支持向量机和神经网络等。
此外,SHAP (Shapley Additive Explanation) 方法可以利用博弈论中的 Shapley 值计算模型中的特征重要性,为助催化剂的设计提供启发。
实验结果
性能对比 随机森林模型最佳
通过交叉验证对模型的超参数进行优化之后,研究人员对比了神经网络和树模型算法的性能。其中,随机森林算法有着最佳的泛化 (Generalization) 能力,测试准确率 70.37%,AUC 为 0.784。
值得注意的是,随机森林模型可以准确识别低性能和中性能的助催化剂,不会将其误认为高性能,说明随机森林模型可以准确捕获高性能助催化剂的特征。
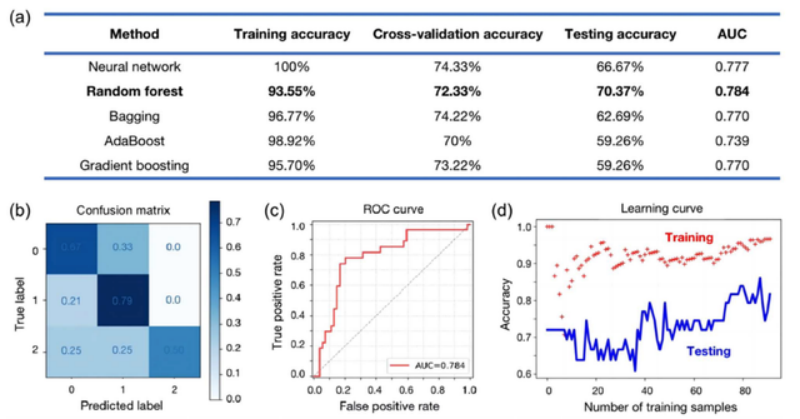
图 6:不同模型的性能对比结果
a:不同模型的准确率、交叉验证准确率、测试准确率和 AUC;
b:随机森林模型的混淆矩阵;
c:随机森林模型的 ROC 曲线;
d:随机森林模型的学习曲线。
随后,研究人员将低性能和中性能归于一类,高性能归为一类,将模型转换为二元输出,随机森林的准确率为 96.30%,AUC 为 0.79。
特征重要性 助催化剂类型
对拟合后的随机森林模型进行特征重要性分析,可以提升模型的可解释性。通过基尼 (Gini) 重要性或平均不纯度减少 (Mean Decrease Impurity),可以评价 PEC 电解池内在特征的重要性。
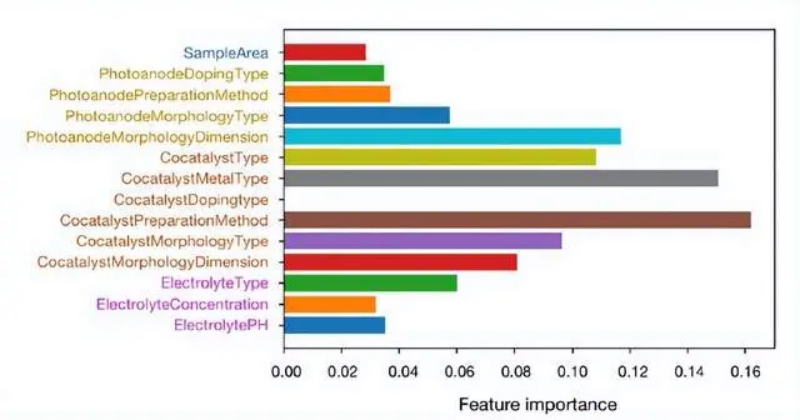
图 7:不同内在特征对 PEC 反应的重要性
助催化剂相关的参数对随机森林模型的预测影响最大,尤其是助催化剂的类型和助催化剂的金属类型。次重要的是助催化剂的准备方法,它对助催化剂的形貌和尺寸也会有影响。此外,光阳极的尺寸也会显著影响随机森林模型的输出。因此,优化 PEC 光阳极时,应以助催化剂为主要指标,同时优化光阳极尺寸。
SHAP分析 助催化剂厚度
研究人员还用 SHAP 计算了二元输出随机森林模型的特征重要性。
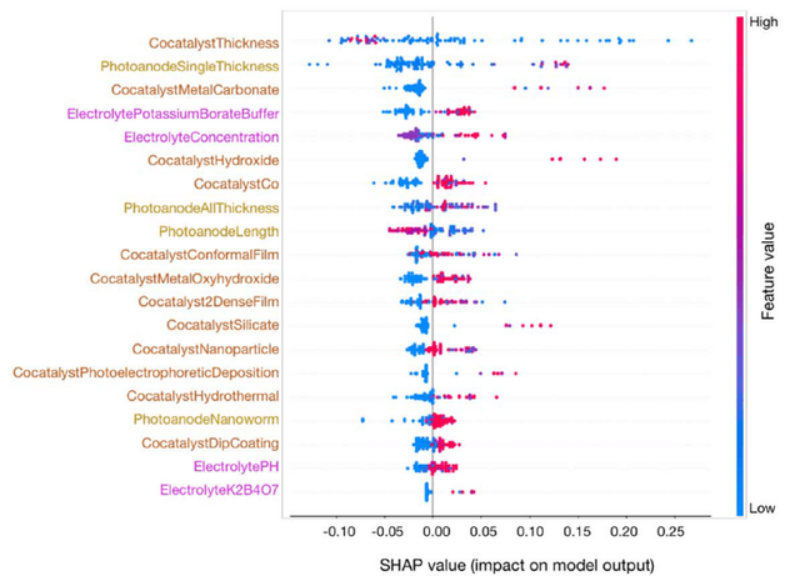
图 8:不同特征的 SHAP 值排序
其中,助催化剂的厚度为最重要的输入特征。随着厚度降低,SHAP 值不断增加,对模型性能的影响不断增加。当助催化剂的厚度在 5-10 nm 之间时,SHAP 为正值,说明厚度降低大概率能够提高模型性能。
当电解液浓度超过 0.5 M 时,SHAP 为正值,说明高浓度电解液有利于 PEC 光电极性能的提升。
结果还显示,硼酸钾缓冲液是最理想的电解液,含钴的助催化剂有利于性能的提升,且金属的氢氧化物有利于性能的提升。

图 9:不同特征变化后 SHAP 值的变化
c:助催化剂厚度对 SHAP 值的影响;
d:光阳极厚度对 SHAP 值的影响;
e:电解液浓度对 SHAP 值的影响。
综上所述,BiVO4 单晶上厚度介于 5-10 nm 之间的钴基氢氧化物,在浓度高于 0.5 M 的硼酸钾电解液中,可能会有良好的 PEC 分解水性能。
PEC 水分解:更有前景的制氢方案
随着全球人口的增长,世界对于能源的需求不断增加,寻求可再生能源成为亟待解决的问题。太阳能是可再生的无碳能源,能量占全球可再生能源的 99% 以上。然而,要完全取代化石能源,需要大规模的储能设备,以解决太阳能的间歇性问题。电池或许可以满足短期储能需求,但长期储能和季节性储能的唯一选择就是燃料。
植物可以通过光合作用,利用光能从水中提取电子,并将这些电子储存在高能的化学键中。受这一过程启发,研究人员开始利用太阳能分解水,将太阳能储存在产物氢气中。
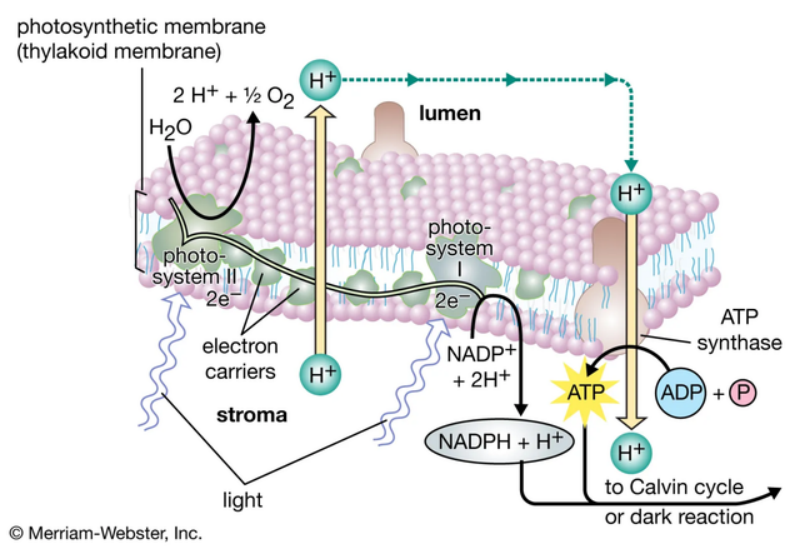
图 10:光合作用流程图
氢气能量密度高 (MJ/kg),无碳排放,可以直接参与到氢经济中,或是通过费托反应 (Fischer–Tropsch) 合成碳燃料,与现有的能源设施相匹配。
目前最有效的太阳能转换设备是光伏设备 (PV, Photovoltaics),将太阳能转换为电能之后,通过电解水产生氢气。但这种方法成本太高,无法与化石燃料竞争。
PEC 分解水提供了廉价的制氢方案。但由于这一反应中载流子传输速度慢、复合率高、电极易腐蚀、反应对水质要求高,PEC 的水分解效率较低,维护成本高。
在 AI 的帮助下,科研人员能够对 PEC 光阳极和助催化剂的组合进行优化,大大提高了 PEC 电极的设计效率。同时,可解释 AI 能够识别出对反应最重要的电极特征,为电极的优化提供参考,为化解全球能源危机提供新方案。
参考链接:
[1]https://onlinelibrary.wiley.com/doi/10.1002/aenm.201700555
[2]https://onlinelibrary.wiley.com/doi/10.1002/aenm.201802877
[3]https://www.britannica.com/science/photosynthesis
这篇关于清华大学利用可解释机器学习,优化光阳极催化剂,助力光解水制氢的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






