本文主要是介绍基于python的心脏病个人指数数据集数据处理——结课论文,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
心脏病个人指数数据集数据处理
摘要:
本论文包含了对心脏病个人指数数据集的概述,数据预处理,数据可视化以及数据分析还有相关代码,整体论文实现以下内容:数据预处理,包括异常数据处理,缺省数据处理,重复值处理,数据标准化;数据可视化,包括受访人员性别比例可视化,种族分布可视化,睡眠时长可视化,心理健康和身体健康情况可视化;数据分析,包括年龄与心脏病的关系,抽烟,喝酒与心脏病的关系,BMI值与心脏病的关系,也包括了这些功能实现的操作步骤以及处理过程和详细代码。本论文所涉及的数据预处理,数据分析仅以此数据集为准,所有处理方法,结果以及结论仅个人观点。
目 录
1. 数据集概述.
2. 数据预处理.
2.1 缺省数据处理.
2.2 重复值处理.
2.3 异常数据处理.
2.4 数据标准化.
3. 数据可视化.
3.1 受访人员性别分布可视化.
3.2 种族比例可视化.
3.3 睡眠时长可视化.
3.4 心理健康和身体健康情况可视化.
4. 数据分析.
4.1 年龄与心脏病的关系.
4.2 抽烟,重度饮酒与心脏病的关系.
4.3 BMI值与心脏病患者的关系.
5. 代码.
数据预处理
数据可视化
数据分析
心脏病个人指数数据集数据处理
1. 数据集概述
该数据集来自美国疾病控制与预防中心,是行为风险因素监测系统(BRFSS)的主要组成部分,该系统每年进行电话调查,收集美国居民健康状况的数据。正如美国疾病控制与预防中心所描述的那样:“BRFSS成立于1984年,在15个州建立,现在在所有50个州以及哥伦比亚特区和3个美国领地收集数据。BRFSS每年完成40多万名成年人的访谈,使其成为世界上最大的连续进行的健康调查系统。
最近的数据集(截至2022年2月15日)包含了2020年的数据。它由401,958行和279列组成。大部分栏目都是针对受访者的健康状况的问题,如“你走路或爬楼梯有严重困难吗?”或“你一生中吸过至少100支烟吗?”。
背景描述
据美国疾病控制与预防中心的数据,心脏病是美国大多数种族(非裔美国人、美国印第安人、阿拉斯加原住民和白人)的主要死因之一。大约一半的美国人(47%)至少有三种导致心脏病的主要风险因素中的一种:高血压、高胆固醇和吸烟。其他关键指标包括糖尿病状况、肥胖(BMI高)、缺乏体育活动或饮酒过多。发现和预防对心脏病有最大影响的因素在医疗保健中非常重要。反过来,计算技术的发展使得机器学习方法的应用能够从数据中检测出“模式”,从而预测病人的病情。
数据说明
该数据集包含18个变量(9个布尔值,5个字符串和4个小数点)。在机器学习项目中,“HeartDisease ”可以用作探究变量,但请注意,类是严重失衡的。
| 数据名称 | 数据说明 | |
| 1 | HeartDisease | -曾报告患有冠心病(CHD)或心肌梗死(MI)的受访者 |
| 2 | BMI | -身体质量指数(BMI) |
| 3 | Smoking | -你一生中至少抽过100支烟吗? |
| 4 | AlcoholDrinking | -重度饮酒者(成年男性每周饮酒超过14杯,成年女性每周饮酒超过7杯 |
| 5 | Stroke | -中风 |
| 6 | PhysicalHealth | -现在想想你的身体健康,包括身体疾病和受伤,在过去的30天里,有多少天你的身体健康不好?(0-30天) |
| 7 | MentalHealth | -心理健康,在过去的30天里有多少天你的心理健康不好?(0-30天) |
| 8 | DiffWalking | -你走路或爬楼梯有严重困难吗? |
| 9 | Sex | -性别 |
| 10 | AgeCategory | -年龄范畴 |
| 11 | Race | -种族/民族 |
| 12 | Diabetic | -是否有糖尿病? |
| 13 | PhysicalActivity | -过去30天里从事体育活动或锻炼的成年人 |
| 14 | GenHealth | -你是否认为你的健康状况? |
| 15 | SleepTime | -平均来说,你在24小时内的睡眠时间是多少小时? |
| 16 | Asthma | -是否得有哮喘? |
| 17 | KidneyDisease | -不包括肾结石、膀胱感染或尿失禁,你是否曾被告知有肾病? |
| 18 | SkinCancer | -是否得过皮肤癌? |
表1-1 数据集数据说明
原始数据集部分数据如下:
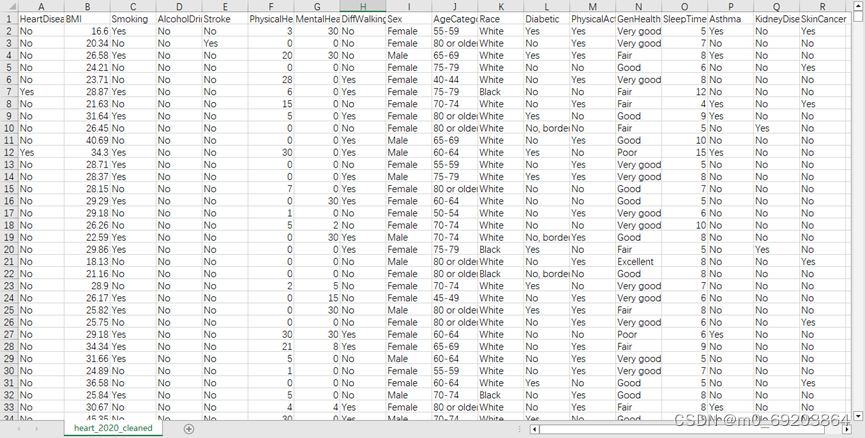
图 1‑1 数据集部分数据截图
2. 数据预处理
2.1 缺省数据处理
首先我们先将数据集导入,接下来查看一下heart数据集的基本信息,来观察数据集包含的数据类型,再用isnull()函数来查看数据集是否有缺省值,处理过程和效果如下图2-1-1和2-1-2所示 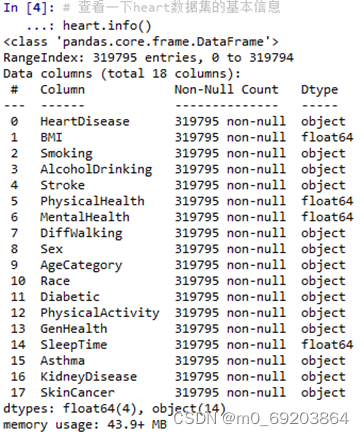
图 2-1-1 查看数据集基本信息
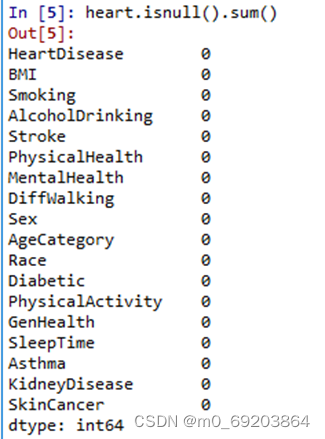
图 2-1-2 判断数据集是否有缺省值
从结果可以看出:
(1)一共319795条信息,这是个大数据集
(2)一共18个特征,其中4个浮点型数据,14个引用型数据
(3)所有数据均完整,无缺失
因此不需要对heart数据集进行缺省数据处理。
2.2 重复值处理
先用duplicated()方法进行逻辑判断,确定是否有重复值,处理过程如所示

图 2-2-1 判断数据集是否有重复值
再用duplicates(subset,keep,inplace)方法对某几列下面的重复行删除
subset:以哪几列作为基准列,判断是否重复,如果不写则默认所有列都要重复才算
keep: 保留哪一个,fist-保留首次出现的,last-保留最后出现的,False-重复的一个都不保留,默认为first
那么在这里我对重复的数据进行的操作是将数据集中所有列数据都重复的行进行删除,将重复值删除后的数据集保存为data1.csv文件,处理过程如所示

图 2-2-1 判断数据集是否有重复值
2.3 异常数据处理
检测数据异常值的方法有很多种,如3σ原则,箱线图分析等等,我这里选择的是使用箱线图来检测数据集的异常值,局限性是只能检测到列为数值型的数据,本次异常数据处理是基于data1.csv数据集上进行的,将处理后的数据集保存到data2.csv文件,操作过程和效果分别如下图2-3-1和图2-3-2所示。
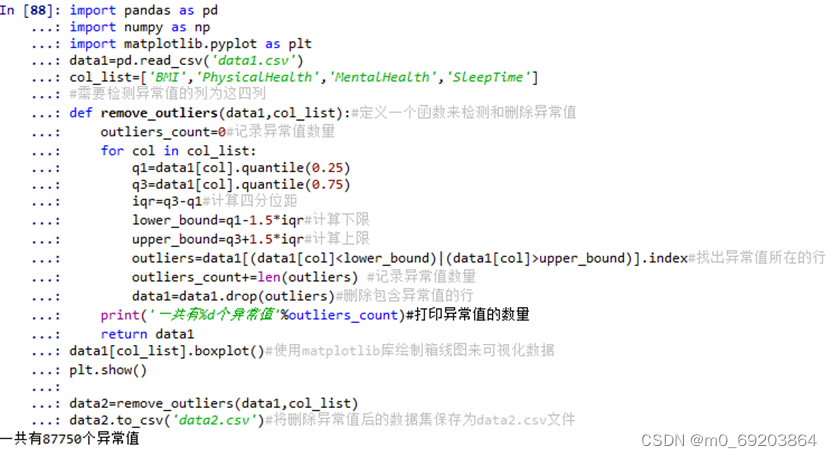
图 2-3-1 异常数据处理过程
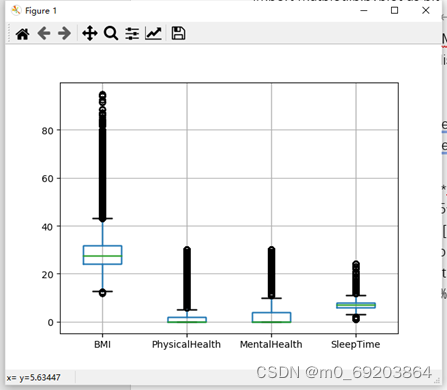
图 2-3-2 异常数据处理箱线图
2.4 数据标准化
数据标准化是基于data2.csv数据集上进行的,这里由于数据集有213956条数据,同样局限于数值型数据,我采用的是离差法标准化。
由于数据庞大,那么我们截取BMI,PhysicalHealth,MentalHealth,SleepTime四列数值型数据的前5行,操作过程如下图2-4-1所示

图 2-4-1 数据集数值型数据前五行
接下来,对数据集中的数值型数据进行离差标准化处理:打印出离差标准化处理前的前五行数据,和离差标准化处理后的前五行数据,并将标准化后的数据集保存至data.csv文件,操作过程和效果如下图2-4-2所示。
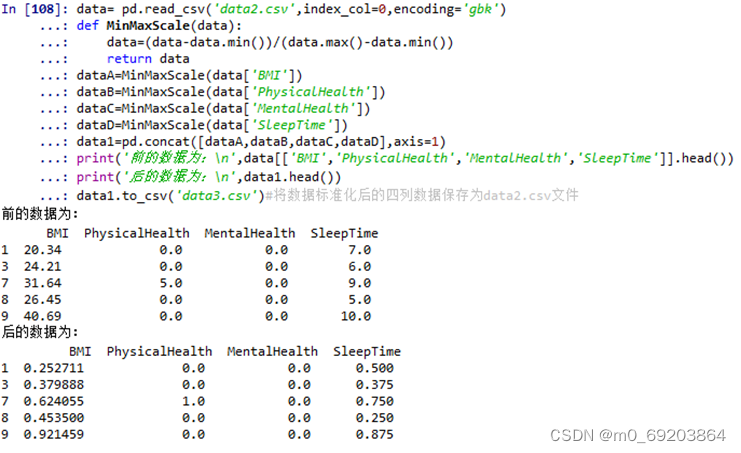
图 2-4-2 数据标准化处理过程与效果
3. 数据可视化
3.1 受访人员性别分布可视化
统计出受访人员的各个性别的人数,并使用直方图方式绘制出可视化图形,如图3-1所示。,具体操作步骤如下图3-1-1和3-1-2所示。
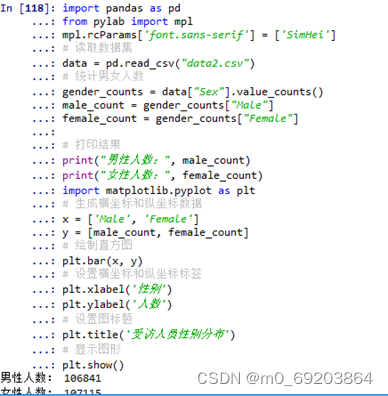
图 3-1-1 受访人员性别分布可视化处理过程
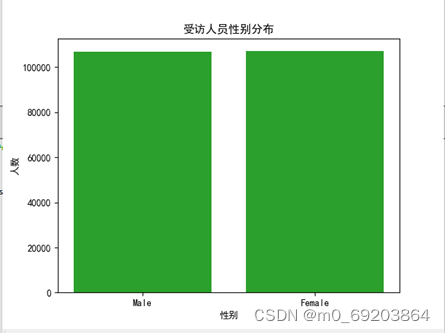
图 3-1-2 受访人员性别分布可视化效果
3.2 种族比例可视化
计算出受访人员的种族分布,然后统计出各个种族的人数,并使用饼图方式绘制出可视化图形,如图3-2所示,处理过程与效果如下图3-2-1和3-2-2所示,每个扇形表示一种情况,扇形的大小表示对应的人数比例。
图 3-2-1 种族比例可视化处理过程
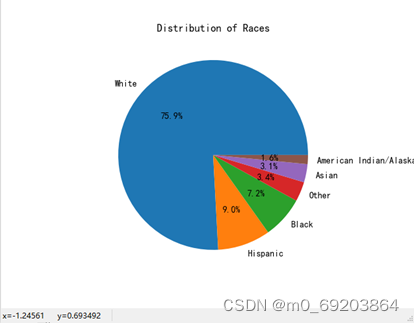
图 3‑2-2种族比例饼图
3.3睡眠时间分布可视化
统计出受访人员各个睡眠时长分布,并使用直方图方式绘制出可视化图形,如图3-3所示,处理过程和效果如图3-3-1和3-3-2所示。

图 3‑3-1睡眠时间分布处理过程
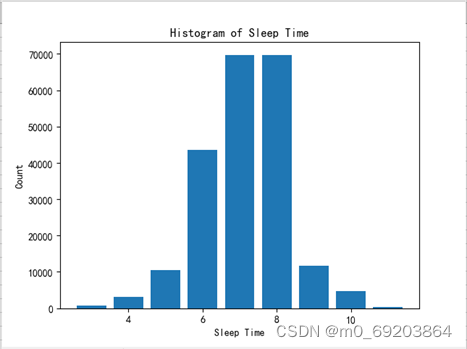
图 3‑3-2睡眠时间分布直方图
3.4心理健康程度和身体健康程度分布可视化
统计出受访人员心理健康程度和身体健康程度分布,并使用折线图方式绘制出可视化图形,如图3-4所示,操作步骤如下:
图 3-4-1 心理健康程度和身体健康程度分布可视化处理过程
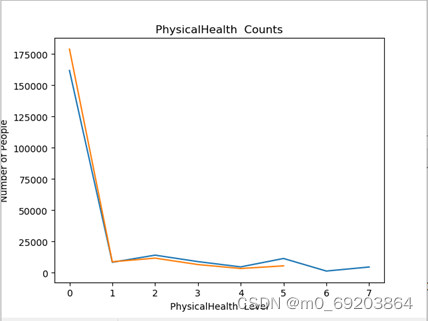
图 3‑4-2心理健康程度和身体健康程度分布折线图
4. 数据分析
4.1 年龄与心脏病的关系
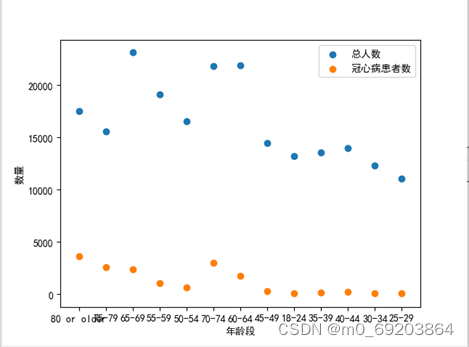
统计出不同年龄段的人员数量分布,并对不同年龄段的心脏病患者进行统计,使用散点图的方式绘制出可视化图形,如图 4‑1所示,处理过程与效果如图4-1-1和4-1-2所示。
通过分析散点图4-1-2可得,从整体上说,随着年龄越大,心脏病患者的人数也越多,所以可以得出随着年龄的增长,患心脏病的概率也会增大。
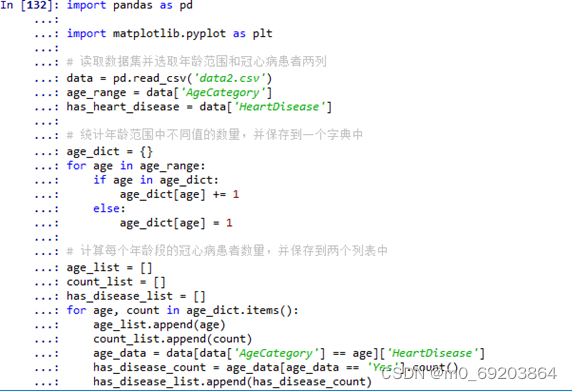

图 4-1-1年龄与心脏病关系分析过程
4.2 抽烟,重度饮酒与心脏病的关系
4.2.1抽烟与心脏病的关系
统计一个数据集中是否抽烟与是否是心脏病患者排列组合四种情况(抽烟且患有心脏病,不抽烟且患有心脏病,抽烟且不患有心脏病,不抽烟且患有心脏病)的人数,通过比例来分析抽烟与心脏病的联系,处理过程如下,结果如图4-2-1所示,每个扇形表示一种情况,扇形的大小表示对应的人数比例。
#首先,导入所需的库:
import pandas as pd
import matplotlib.pyplot as plt
#使用pandas读取数据集:
data = pd.read_csv('data2.csv')
#接下来,可以使用pandas的groupby函数对数据进行分组统计:
count = data.groupby(['Smoking', ' HeartDisease']).size().reset_index(name='人数')
#最后,使用matplotlib库绘制饼图:
plt.pie(count['人数'], labels=count['Smoking'] + ' ' + count[' HeartDisease '], autopct='%1.1f%%')
plt.axis('equal')
plt.show()
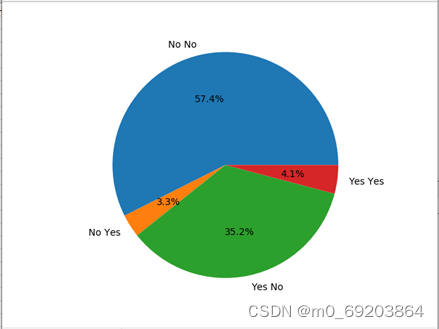
图 4-2-1抽烟与心脏病的关系饼图
通过分析图4-2-1可得,是否抽烟与心脏病患者的关系并不大,不能说明是否抽烟与心脏病患者存在什么明显的关系。
统计数据集中心脏病患者中抽烟人数的占比,再使用饼图的方式绘制出可视化图形表示他们的关系,如图4-2-4所示,每个扇形表示一种情况,扇形的大小表示对应的人数比例。
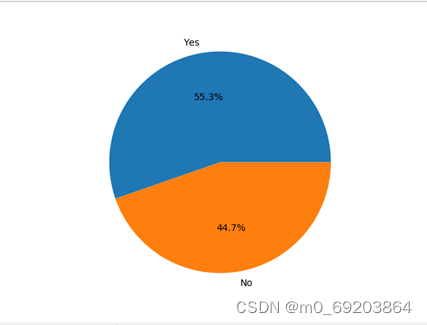
图 4-2-2心脏病患者中抽烟人数的占比饼图
通过分析图4-2-2可得,心脏病患者中有55.3%的人抽烟,可以说明抽烟会提高患有心脏病的概率。
4.2.2重度饮酒与心脏病的关系
统计数据集中重度饮酒与是否是心脏病患者排列组合四种情况(重度饮酒且患有心脏病,不重度饮酒且患有心脏病,重度饮酒且不患有心脏病,不重度饮酒且不患有心脏病)的人数,通过比例来分析抽烟与心脏病的联系,如图4-2-3所示,每个扇形表示一种情况,扇形的大小表示对应的人数比例。
#首先,导入所需的库:
import pandas as pd
import matplotlib.pyplot as plt
#使用pandas读取数据集:
data = pd.read_csv('data2.csv')
#接下来,可以使用pandas的groupby函数对数据进行分组统计:
count=data.groupby(['AlcoholDrinking','HeartDisease']).size().reset_index(name='人数')
#最后,使用matplotlib库绘制饼图:
plt.pie(count['人数'], labels=count['AlcoholDrinking'] + ' ' + count[' HeartDisease '], autopct='%1.1f%%')
plt.axis('equal')
plt.show()
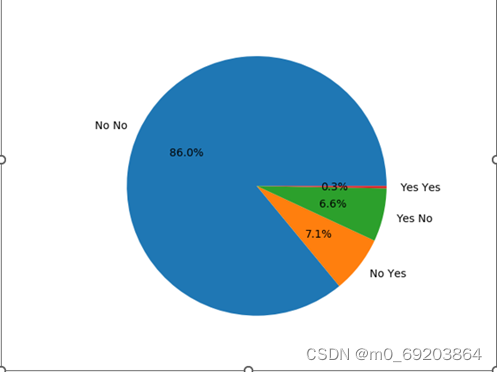
图 4‑2-3喝酒与心脏病的关系饼图
通过分析图4-2-3可得,是否抽烟与心脏病患者的关系并不大,不能说明是否抽烟与心脏病患者存在什么明显的关系。
统计数据集中心脏病患者中重度喝酒人数的占比,再使用饼图的方式绘制出可视化图形表示他们的关系,如图4-2-4所示,每个扇形表示一种情况,扇形的大小表示对应的人数比例。
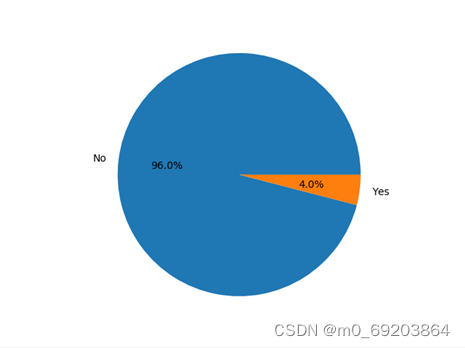
图 4-2-4喝酒与心脏病患者的关系饼图
通过分析图4-2-4可得,心脏病患者中仅有4.0%的人重度饮酒,可以说明重度饮酒不会提高患有心脏病的概率。
4.2.3抽烟,重度饮酒与心脏病的关系
统计数据集中是否抽烟与是否是冠心病患者和是否是饮酒的排列组合六种情况(抽烟重度饮酒患心脏病,抽烟不喝酒患心脏病,抽烟不重度饮酒不患冠心病,不抽烟但重度饮酒患心脏病,不抽烟但重度饮酒酒不患冠心病,不抽烟不重度饮酒不患冠心病 )的人数,并使用饼图进行可视化,处理过程如下,结果如下图4-2-5所示,每个扇形表示一种情况,扇形的大小表示对应的人数比例。
#导入所需的库:
import pandas as pd
import matplotlib.pyplot as plt
#使用pandas读取数据集:
data = pd.read_csv('data2.csv')
#使用pandas的groupby函数对数据进行分组统计,得到六种情况的人数:
count = data.groupby(['Smoking', 'HeartDisease', ' AlcoholDrinking ']).size().reset_index(name='人数')
#使用matplotlib库绘制饼图:
plt.pie(count['人数'], labels=count[' Smoking '] + ' ' + count[' HeartDisease '] + ' ' + count[' AlcoholDrinking '], autopct='%1.1f%%')
plt.axis('equal')
plt.show()
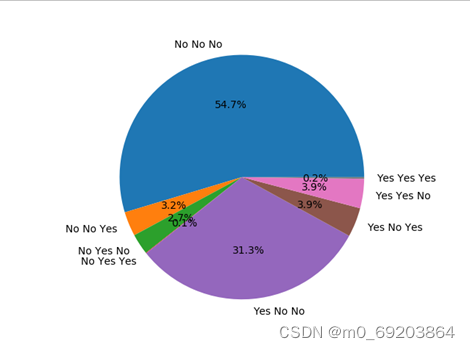
图 4-2-5抽烟,喝酒与心脏病患者的关系饼图
通过分析图4-2-5可得,仅抽烟,仅喝酒或既喝酒又抽烟与心脏病患者的关系并不大,不能说明他们存在什么明显的关系。
4.3 BMI值与心脏病患者的关系
统计数据集中心脏病患者不同BMI值的的数量,并以直方图的方式可视化数据,处理过程如下,结果如图4-3-1 所示。
通过分析图4-3-1 ,心脏病患者的人数随BMI值正态分布,BMI值越靠近中间,心脏病患者的人数越多,从中间向两边呈递减趋势。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
data = pd.read_csv('data2.csv')
count = data[data['HeartDisease'] == 'Yes']['BMI'].value_counts().sort_index()
plt.hist(data[data['HeartDisease'] == 'Yes']['BMI'], bins=10, edgecolor='black')
plt.xlabel('BMI值')
plt.ylabel('人数')
plt.title('心脏病患者的BMI值分布')
plt.show()
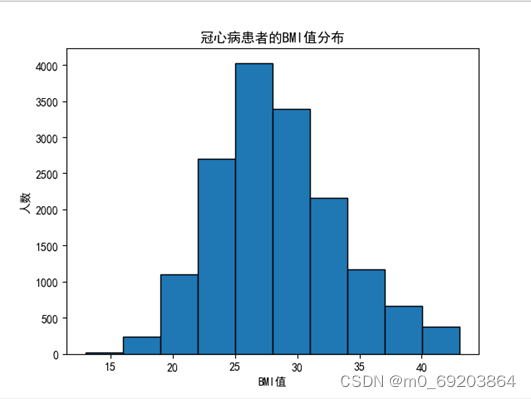
图 4-3-1 BMI值与心脏病患者的关系直方图
5. 代码
数据预处理
缺省数据处理:
#导入所需库import numpy as npimport pandas as pd#画图import matplotlib.pyplot as plt# 导入数据集"heart_2020_cleaned.csv"heart = pd.read_csv('heart_2020_cleaned.csv')# 查看一下数据heart.head()# 查看一下heart数据集的基本信息heart.info()#查看缺省数据并总计heart.isnull().sum()重复数据处理:
#先用duplicated()方法进行逻辑判断,确定是否有重复值data=pd.read_csv("heart_2020_cleaned.csv",encoding='gbk')#打印出重复值的数量print(data.duplicated().value_counts())#再用duplicates(subset,keep,inplace)方法对某几列下面的重复行删除#subset:以哪几列作为基准列,判断是否重复,如果不写则默认所有列都要重复才算#keep: 保留哪一个,fist-保留首次出现的,last-保留最后出现的,False-重复的一个都不保留,默认为first#那么在这里我对重复的数据进行的操作是将数据集中所有列数据都重复的行进行删除。data1=data.drop_duplicates(subset=None,keep='first',inplace=False)print(data1.duplicated().value_counts())#并将删除重复值后的数据保存到data1.csv文件data1.to_csv('data1.csv')异常值处理:
data1=pd.read_csv('data1.csv')#需要检测异常值的列为这四列col_list=['BMI','PhysicalHealth','MentalHealth','SleepTime']def remove_outliers(data1,col_list):#定义一个函数来检测和删除异常值outliers_count=0#记录异常值数量for col in col_list:q1=data1[col].quantile(0.25)q3=data1[col].quantile(0.75)iqr=q3-q1#计算四分位距lower_bound=q1-1.5*iqr#计算下限upper_bound=q3+1.5*iqr#计算上限outliers=data1[(data1[col]<lower_bound)|(data1[col]>upper_bound)].index#找出异常值所在的行outliers_count+=len(outliers) #记录异常值数量data1=data1.drop(outliers)#删除包含异常值的行print('一共有%d个异常值'%outliers_count)#打印异常值的数量return data1data1[col_list].boxplot()#使用matplotlib库绘制箱线图来可视化数据plt.show()data2=remove_outliers(data1,col_list)data2.to_csv('data2.csv')#将删除异常值后的数据集保存为data2.csv文件数据标准化:
#打印前几行数值型数据print(data2.loc[:10,['BMI','PhysicalHealth','MentalHealth','SleepTime']])#导入数据集data= pd.read_csv('data2.csv',index_col=0,encoding='gbk')def MinMaxScale(data):data=(data-data.min())/(data.max()-data.min())return datadataA=MinMaxScale(data['BMI'])dataB=MinMaxScale(data['PhysicalHealth'])dataC=MinMaxScale(data['MentalHealth'])dataD=MinMaxScale(data['SleepTime'])data1=pd.concat([dataA,dataB,dataC,dataD],axis=1)print('前的数据为:\n',data[['BMI','PhysicalHealth','MentalHealth','SleepTime']].head())print('后的数据为:\n',data1.head())data1.to_csv('data3.csv')#将数据标准化后的四列数据保存为data3.csv文件数据可视化
受访性别比例:
import pandas as pdfrom pylab import mpl mpl.rcParams['font.sans-serif'] = ['SimHei']# 读取数据集data = pd.read_csv("data2.csv")# 统计男女人数gender_counts = data["Sex"].value_counts()male_count = gender_counts["Male"]female_count = gender_counts["Female"]# 打印结果print("男性人数:", male_count)print("女性人数:", female_count)import matplotlib.pyplot as plt# 生成横坐标和纵坐标数据x = ['Male', 'Female']y = [male_count, female_count]# 绘制直方图plt.bar(x, y)# 设置横坐标和纵坐标标签plt.xlabel('性别')plt.ylabel('人数')# 设置图标题plt.title('受访人员性别分布')# 显示图形plt.show()种族分布可视化:
import pandas as pdimport matplotlib.pyplot as plt# 读取数据集data = pd.read_csv('data.csv')# 统计每种种族的人数count = data['Race'].value_counts()# 绘制饼图plt.pie(count, labels=count.index.tolist(), autopct='%1.1f%%')plt.title('Distribution of Races')plt.show()睡眠时间分布可视化:
import pandas as pdimport matplotlib.pyplot as plt# 读入数据集data = pd.read_csv('data2.csv')# 获取睡眠时间列的值,并计算每个唯一值的数量sleep_time_values = data['SleepTime'].value_counts()# 绘制直方图plt.bar(sleep_time_values.index, sleep_time_values.values)plt.xlabel('Sleep Time')plt.ylabel('Count')plt.title('Histogram of Sleep Time')plt.show()数据分析
年龄与心脏病患者的关系:
import pandas as pdimport matplotlib.pyplot as plt# 读取数据集并选取年龄范围和冠心病患者两列data = pd.read_csv('data2.csv')age_range = data['AgeCategory']has_heart_disease = data['HeartDisease']# 统计年龄范围中不同值的数量,并保存到一个字典中age_dict = {}for age in age_range:if age in age_dict:age_dict[age] += 1else:age_dict[age] = 1# 计算每个年龄段的冠心病患者数量,并保存到两个列表中age_list = []count_list = []has_disease_list = []for age, count in age_dict.items():age_list.append(age)count_list.append(count)age_data = data[data['AgeCategory'] == age]['HeartDisease']has_disease_count = age_data[age_data == 'yes'].count()has_disease_list.append(has_disease_count)# 绘制散点图plt.scatter(age_list, count_list, label='总人数')plt.scatter(age_list, has_disease_list, label='冠心病患者数')plt.xlabel('年龄段')plt.ylabel('数量')plt.legend()plt.show()抽烟,重度饮酒与心脏病的关系
抽烟与心脏病的关系:
#首先,导入所需的库:import pandas as pdimport matplotlib.pyplot as plt#使用pandas读取数据集:data = pd.read_csv('data2.csv')#接下来,可以使用pandas的groupby函数对数据进行分组统计:count = data.groupby(['Smoking', ' HeartDisease']).size().reset_index(name='人数')#最后,使用matplotlib库绘制饼图:plt.pie(count['人数'], labels=count['Smoking'] + ' ' + count[' HeartDisease '], autopct='%1.1f%%')plt.axis('equal')plt.show()重度饮酒与心脏病的关系:
#首先,导入所需的库:import pandas as pdimport matplotlib.pyplot as plt#使用pandas读取数据集:data = pd.read_csv('data2.csv')#接下来,可以使用pandas的groupby函数对数据进行分组统计:count=data.groupby(['AlcoholDrinking','HeartDisease']).size().reset_index(name='人数')#最后,使用matplotlib库绘制饼图:plt.pie(count['人数'], labels=count['AlcoholDrinking'] + ' ' + count[' HeartDisease '], autopct='%1.1f%%')plt.axis('equal')plt.show()抽烟,重度饮酒与心脏病的关系:
#导入所需的库:import pandas as pdimport matplotlib.pyplot as plt#使用pandas读取数据集:data = pd.read_csv('data2.csv')#使用pandas的groupby函数对数据进行分组统计,得到六种情况的人数:count = data.groupby(['Smoking', 'HeartDisease', ' AlcoholDrinking ']).size().reset_index(name='人数')#使用matplotlib库绘制饼图:plt.pie(count['人数'], labels=count[' Smoking '] + ' ' + count[' HeartDisease '] + ' ' + count[' AlcoholDrinking '], autopct='%1.1f%%')plt.axis('equal')plt.show()BMI值与心脏病患者的关系:
import pandas as pdimport matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei']data = pd.read_csv('data2.csv')count = data[data['HeartDisease'] == 'Yes']['BMI'].value_counts().sort_index()plt.hist(data[data['HeartDisease'] == 'Yes']['BMI'], bins=10, edgecolor='black')plt.xlabel('BMI值')plt.ylabel('人数')plt.title('心脏病患者的BMI值分布')plt.show()这篇关于基于python的心脏病个人指数数据集数据处理——结课论文的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




