本文主要是介绍S/4 HANA 大白话 - 财务会计-2 总账主数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
接下来看看财务模块的一些具体操作。
总账相关主数据
公司每天运转,每天办公室有租金,有水电费,有桌椅板凳损坏,鼠标损坏要换,有产品买卖,有收入。那么所有这些都得记下来。记哪里?记在总账里。
你从应收账款能看到赚了多少钱,同时你能看到应付账款里,你还欠多少钱。这些就是会计科目表里要弄的。
财务会计的核心就是总账。记录了所有跟钱有关的业务操作。总账会计里核心就是总账账户。总账账户在会计科目表里组织起来。
会计科目表
每个公司都得有会计科目表,不过同一个controlling area下的公司可以用同一个。这个就叫做运营会计科目表,会计人员记账的时候,用的科目都在这个运营会计科目表里。
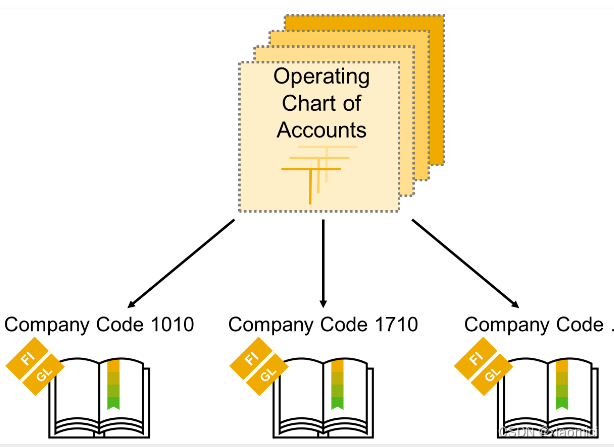
除了运营会计科目表以外,还有国家会计科目表和集团会计科目表。
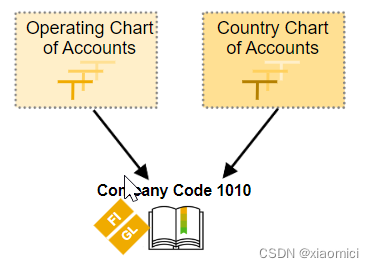
主要用来应对本地会计准则,比如国家会计科目表是分配在公司代码层的。而且和运营会计科目表里的科目是一对一的关系。等于是多记了一套备份。
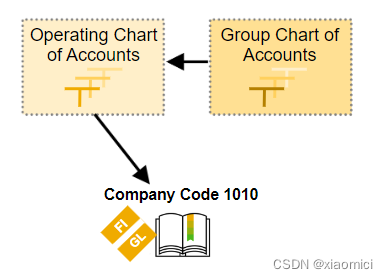
而集团会计科目表主要为了出具合并财务报表。就是有可能集团下面子公司用的是不同的运营会计科目表,那么我在这个不同的运营会计科目表之上,再整合出一个集团会计科目表,n个运营会计科目表中的科目最终我会给一个高等级的集团会计科目表科目。
有了会计科目表的定义,那我们就要去填充里面的总账科目了。
由于咱知道每个公司代码得有一个会计科目表。同一个控制范围下的公司代码可以用一套会计科目表。但是用了这个科目直接去记账的时候,我不同国家会有不同的货币啊,不同的记账的税率啊,这些都要单独配置的。
也就是说总账科目的设置,其实有两步。
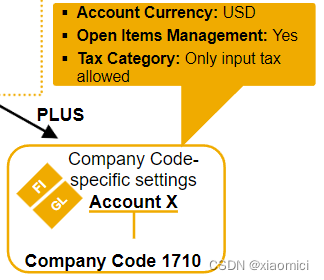
1. 在会计科目表层。配置账户的编号,名称,类型这些通用信息。
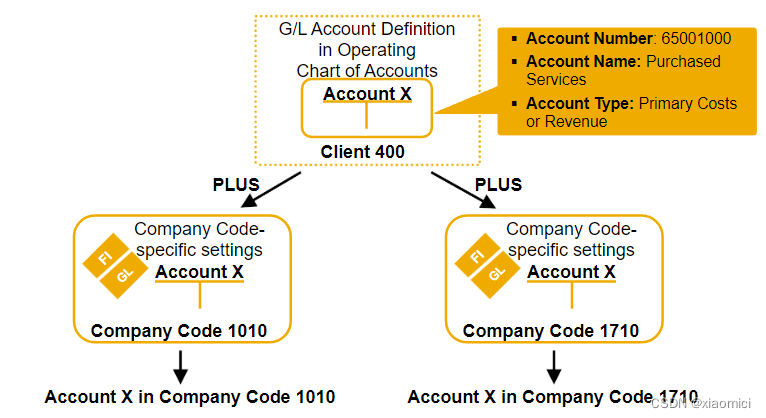
2.在公司代码层。可以配置不同的账户币别。未清项管理的设置,还有表明是哪个子分类账的统驭科目。

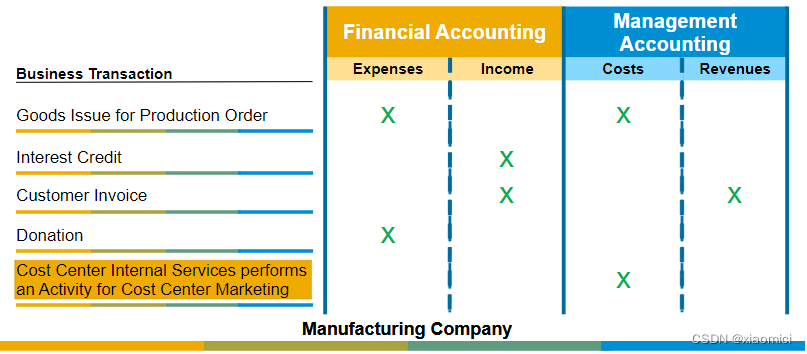
在财务会计中处理库存,费用,收入。在管理会计中只处理成本和收入。
这里要注意到不是所有财务中的费用和收入 都等同于 管控中的成本和收入。
这个怎么理解?比如在一个制造型公司。
对于生产订单的发货操作,由于是和产品及业务相关,所以财务里的费用和管控里的成本是一致的。
对于利息成本那就是只和FI相关。和CO无关。
对于客户发票,由于是交付货物才有的,所以FI和CO里的收入都一致。
对于捐赠,跟公司业务完全无关,所以只存在FI中。
对于为成本中心营销执行的内部成本中心服务,肯定是只和CO有关。所以说收入和费用类的,要看具体的业务活动。
总账科目类型
由于公司会有不同的经营活动,产生的费用和收入到底是属于FI的还是CO的,这个要怎么区分呢?
就是在建总账科目的会计科目表层就需要考虑了。
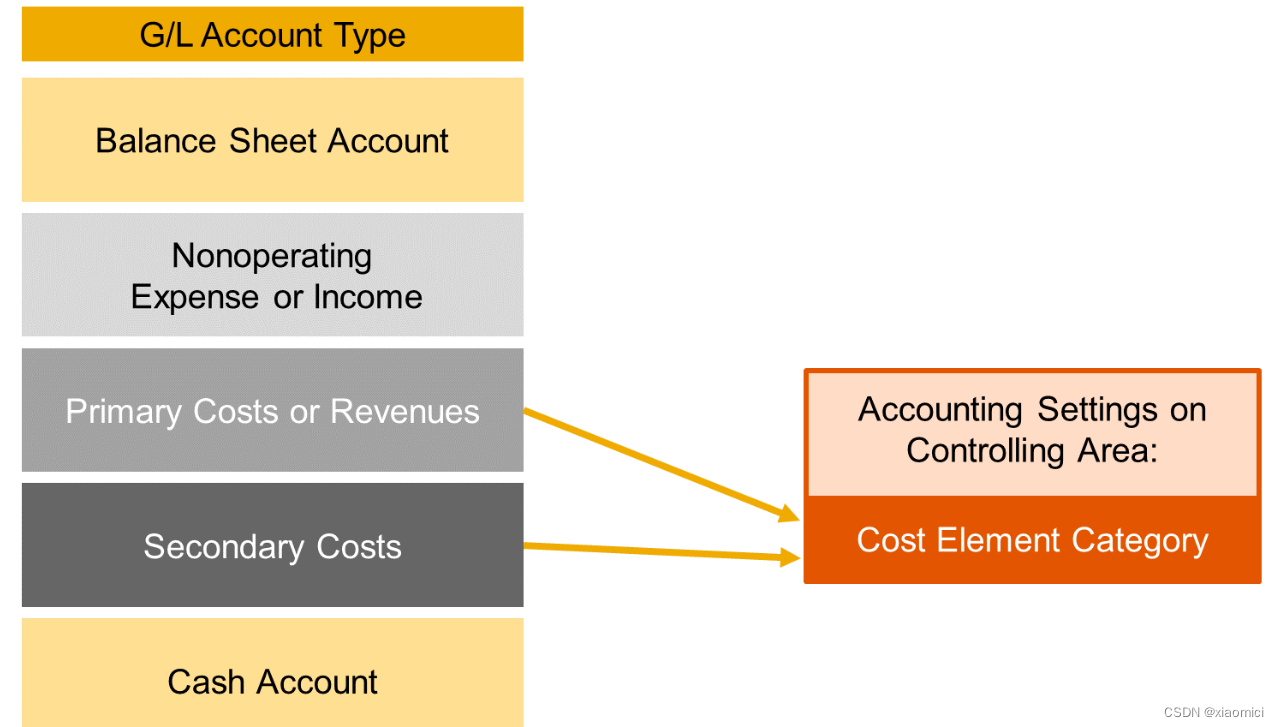
总账科目类型有5个。通过上面的例子,现在就很明确的理解了。另外我还写过另一篇,也可以再理解理解:S4HANA - Cost Elements成本要素_xiaomici的博客-CSDN博客
资产负债表科目。跟CO不相关的。只在资产负债表里用到的科目。
非运营费用或收入。(利润表科目,完全FI相关的,和生产业务毫不相关的,比如说捐款啥的)
主要成本或收入。(利润表科目,FI和CO相关的,比如人员工资,销售费用,货品发布费用等运营费用,跟个成本要素一个功能)
次级成本。(利润表科目,CO相关的,来自于组织内部价值流转,比如内部活动的成本分配,管理费用分配,以及一些结算交易)
现金账户。也是资产负债表里的科目,主要用统驭科目来管理银行账户。
上面这些科目类别,就是看科目是属于什么性质的业务活动来划分的。
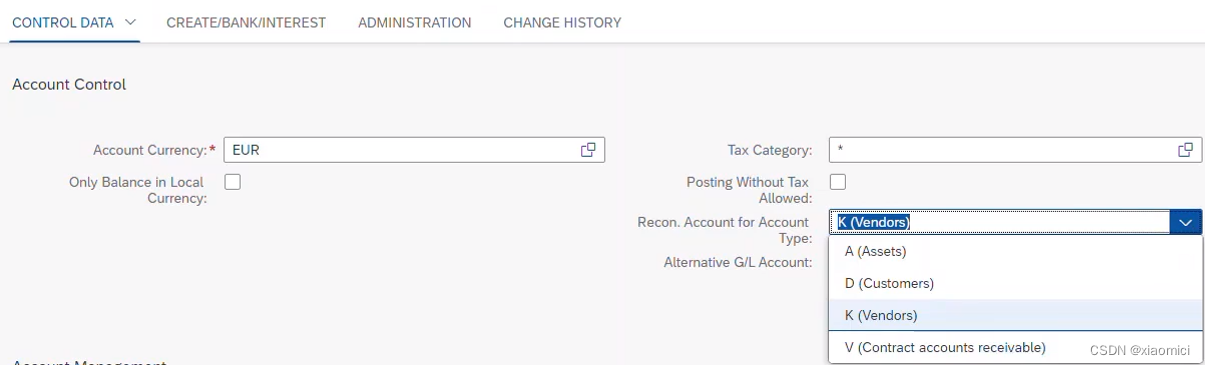
比如一个应收账款账户,是在资产负债表类型的的,那么它的会计科目表层账户组是在资产负债表类型,而公司代码层会有一个统驭科目类型,对应D 客户。应收账款模块下的凭证会自动更新到总账的这个科目下。
如果总账科目是主要成本或收入或者次要成本科目,那还得配置的时候附加一个cost/revenue element的信息。因为在CO里面人家就叫成本要素。
比如一个主要成本和收入类型账户,那么得给它设置一个控制范围数据,选定cost element category,这里的1 就是指CO里面的主要成本。在FI或者MM里记账的主要成本在这里集成到CO模块,也就是说会自动过账到CO模块的这个主要cost element下面。

以上就能看出来SAP的开发逻辑就是这么个玩法,集成就是把两边的控制数据都拉过来对应,我中有你,你中有我。我的应收账款账户数据,就是AR的客户的数据,客户的交易数据有了,就会直接填充到我的应收账款科目里。我的主要成本和收入,就是CO的成本要素的1级,我有了数据也会直接填充到CO的成本要素里面。同理次级成本对应cost element category 2。
账户类型就是以上,账户组是另外一个概念。账户组决定的是科目编码范围,还有字段状态(也就是哪些字段显示,哪些不显示啥的)
财务报表版本 Financial statement version(FSV)
就是因为有不同的会计准则,所以得给资产负债表和利润表啥的准备不同的结构。
在总账科目里咱知道所有所有会计活动都会以会计科目来记载。然后来生成财务报表。
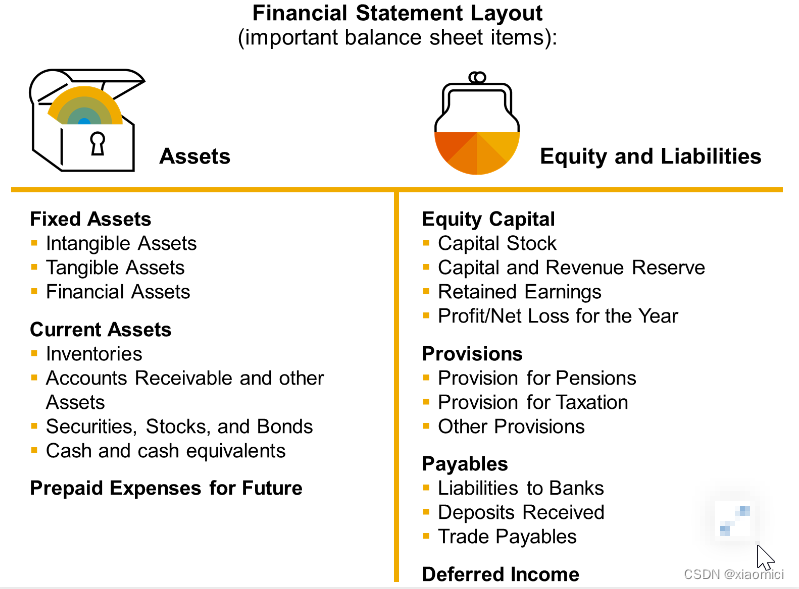
一个公司代码下可以用不同的财务报表版本,其实也就是把资产负债表里的科目组个层级结构来。至于为什么要这个搞:
原因有:并行会计,报告需要按照本地或者国际会计准则来编制。
或者要给内部一份,外部一份资产负债表,所以科目排列啥的侧重点不同。
利润中心
利润中心主要用来考量组织内部哪些部门赚钱的。
利润中心的划分没有统一逻辑,能按照地域大区来分的。看哪个大区赚钱最多的。
按照部门来分的,市场部,销售部,生产部,规划部等等。
按照产品线来分的,电缆事业部,家电事业部。
这个利润中心是CO里面的概念,内部管控要看哪个部门挣钱多。效益高。
所以它上头是controlling area。一个controlling area就只有一个标准的利润中心层级,当然如果说要弄计划啊啥的也可以建其他的利润中心层级。

所以利润中心还会有层级,这个利润中心的名字,负责人,部门。一开始的话,所有同属于一个controlling area的公司代码,都会有个利润中心层级。
这个是在controlling area层上的。比如下图,最顶层的利润中心节点是分配到控制范围上的。
再往下的利润中心组是根据不同业务划分的。也就是个组名。再往下的利润中心节点,才是真正的主数据,需要维护利润中心名字,有效期,归属的控制范围,以及是哪个公司代码上的。

由于一开始建在了控制范围上,所以一个控制范围下的公司代码都会被分配到一个利润中心,下面的就是能改掉的地方。
段 Segment
这个Segment不知道咋翻译,段,分部啥的。
为啥要有这个Segment?
首先是为了应对一些法定的会计标准,比如IFRS或者US GAAP。把业务再往下细分。不同的一些国家会要求你定期发布segment报表。这个segment就可能是说原本你是有一个家电事业部,那现在要让你把家电事业部划分为白电和黑电事业部。把你的业务领域再细分。
因为是一些国家的要求,那所以不是个必须选项,而且由于是对外发布,所以segment是属于FI模块的组织单位,跟profit center不一样。profit center 是属于CO模块的。
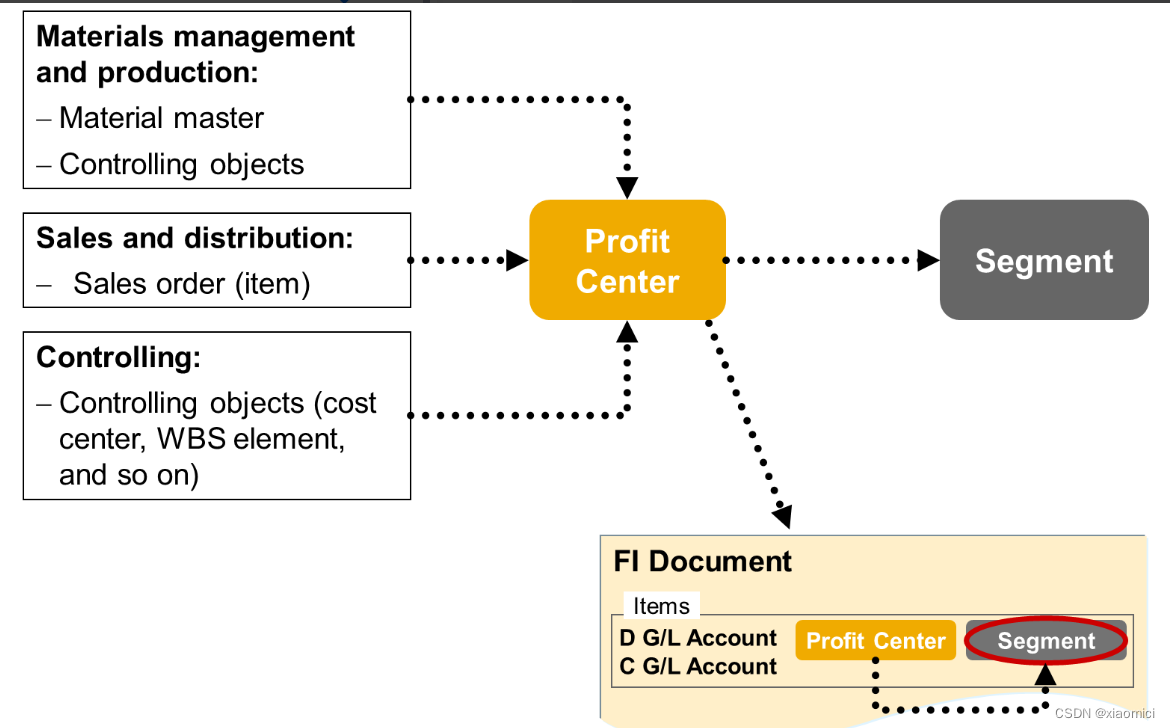
这个segment现在只是在手动凭证输入的时候作为一个可填的字段。
那自动集成怎么搞的呢?就是把segment当做Profit center的主数据一个属性。Profit center是完美集成到各个不同模块的。当一个凭证过账到利润中心的时候,就会同时过到这个segment上面了。按此理解就是,一个segment可以有一个或几个利润中心。从上图也能看到,生产部可以是一个利润中心,销售部可以是一个利润中心等等。

总账会计上的日常操作
通用日记账
会计分录就是来记录财务会计和管理会计里的所有业务交易。S4里有个转有名词:Universal Journal通用日记账。这里记录了所有的模块的日记账。所有的实际的财务核算和控制数据都会保存到表ACDOCA里,注意是实际的,不是说计划的。计划的在另外的一个表里,忘记表名了。

在这个通用日记账上的处理过程比如:一个收入的发票,由于它是财务会计里的收入科目,但是同时和成本中心费用类科目做了关联,那么日记账就会同时同步到FI和CO里。
由于数据只保存了一次,就保存在这个ACDOCA表里,所以就不需要在不同模块对账了。
可以直接在此表上出具灵活,快速的多维报表,就不需要复制数据到BW了。就算还需要BW,那么只要从一个数据源出数据就行了。
这就从根本上减少了数据冗余和内存的占用。
分类账
比如我们需要根据不同会计准则来发布会计报表。那么就得在系统里设置并行会计。也就是说得搞不同的ledgers。不同的会计准则下可能月度收益和资产折旧的估算方法会不同,那么可能就得单独录入到不同的Ledger里面。
这么一看还是很麻烦的么。
分类账就是会计中记账数据的集合,总账会计里的总分类账它也是在分类账这个级别进行管理,最后汇总起来的。而且是根据特定会计准则来汇总的。
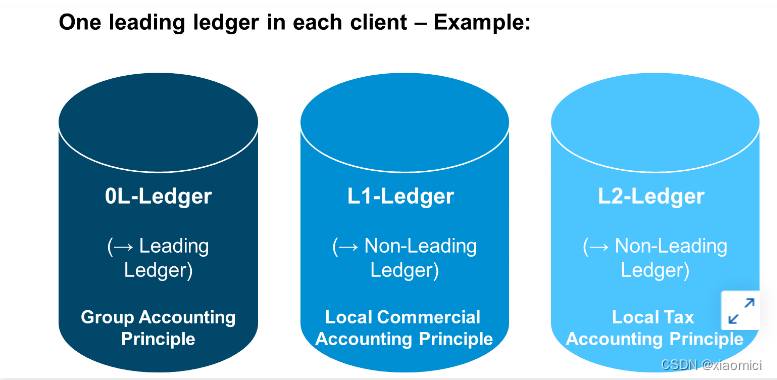
根据不同会计准则,一般一个client里会有一个0L。这就是会计和财务报告的基准。
主分类账0L
是强制设定的,跟所有公司代码自动关联的。而且和CO紧密集成,构成CO实际数据的基础。
其他分类账 L1、L2
平行记账要用的其他分类账,就是说在总账会计里需要用几种不同的估算方法来管理一个业务操作的话。
比如我们根据国际财务报告准则IFRS的会计原则创建合并财务报表。但是各个子公司还要根据当地商业和税务会计原则创建财务报表。
所以在记账之初,就要设定总分类账类型 0L 主分类账按照IFRS记录。
L1 非主分类账,根据本地商业法记账所有公司代码的账目。
L2 根据本地税法记账。
除了0L是默认设定的,L1和L2要自己配置的。
当你过账的时候,可以选是向所有分类账过账,或者向部分过账。这个在凭证过账是的的ledger group里配置。比如LO这个分类账组是包含了L1和L2,那过账就会同时过到下面两个上去。
如果不选就是过账到所有分类账。
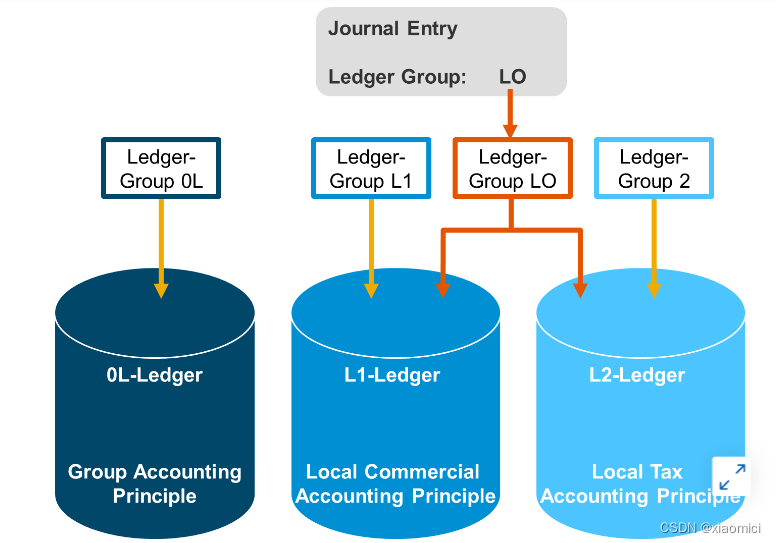
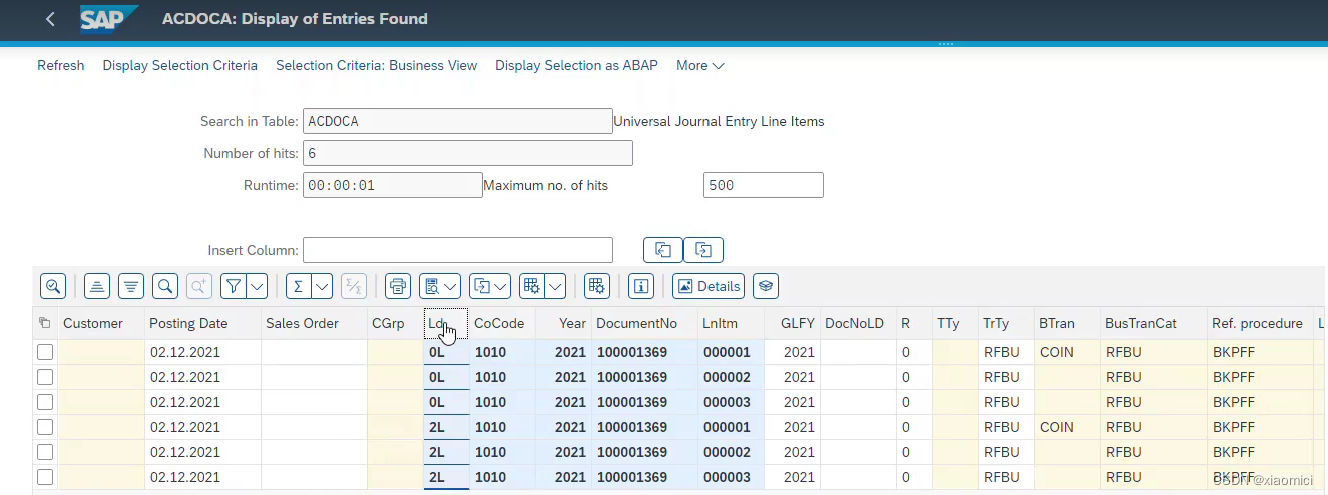
比如在凭证抬头上不选ledger group,那你就会在ACDOCA里看到不同的Ledger下面有重复的line itmes条目。
记账操作
抬头:过账日期,凭证日期,凭证类型,原始凭证,分类账组,货币。
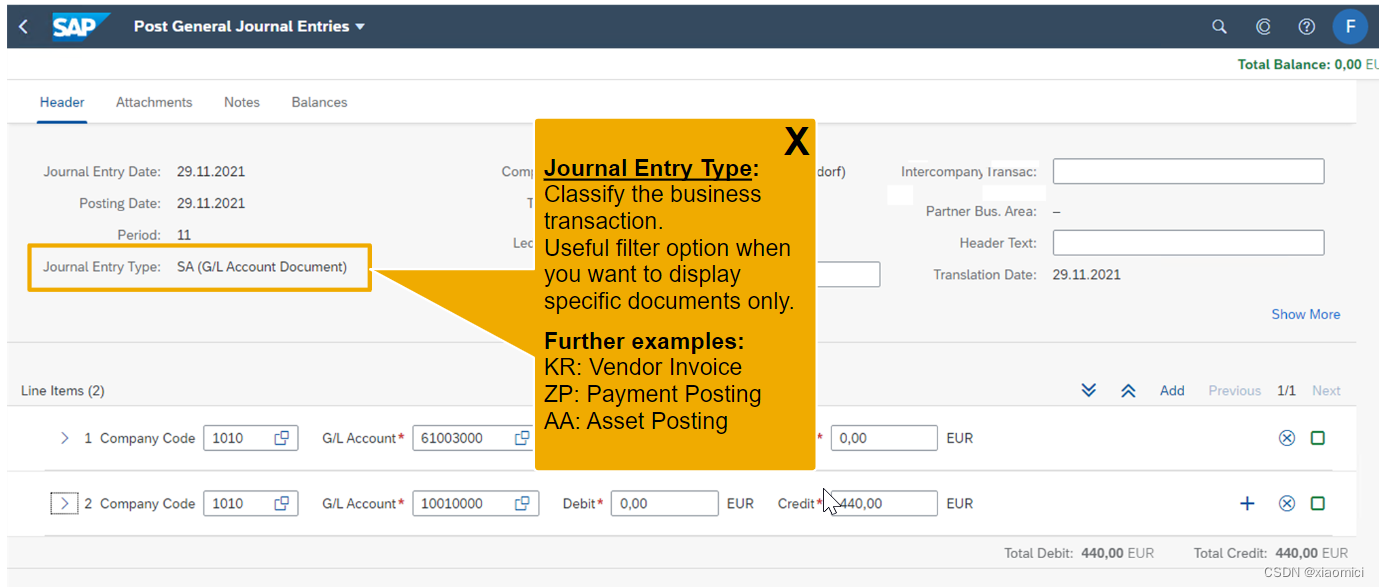
行项目:金额,账号,借贷方,或者和CO关联的需要填cost center。


记账分析
日记账和复式记账的关系:

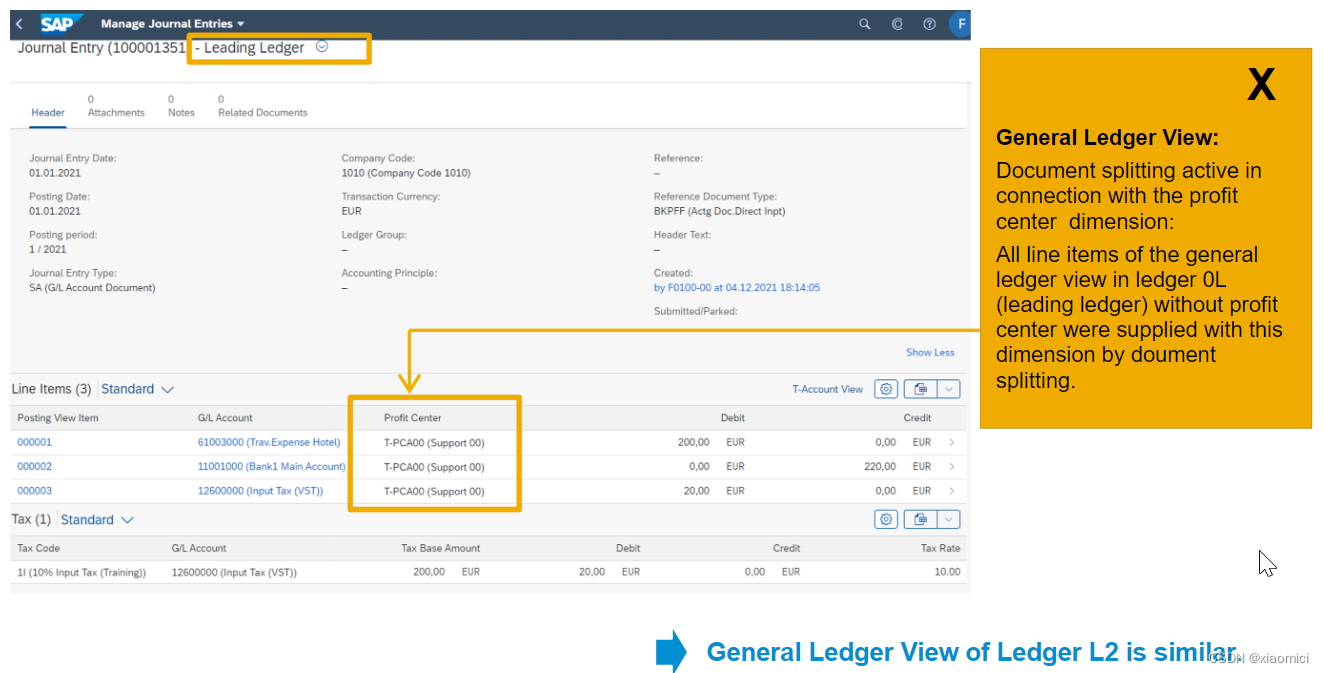
在账目记录上,我们会给主要成本分配一个成本中心,最后便于CO里管理会计统计成本。利润中心是成本中心的属性,所以利润中心会自动被带出来。 这个是原始记录。
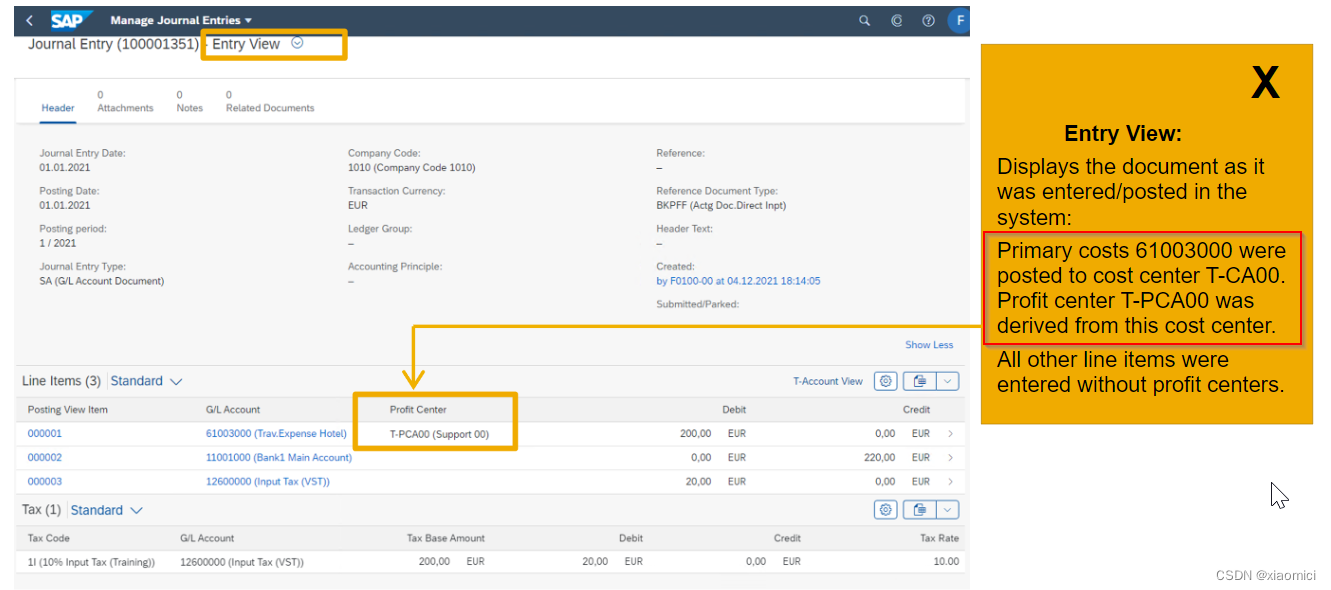
当从主分类进去看的时候,所有的行项目都会被分配同一个利润中心。因为需要一个平衡的借贷方。为了出报表考虑。 这个是系统自己的document split功能。
这篇关于S/4 HANA 大白话 - 财务会计-2 总账主数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






