本文主要是介绍4+m6A+机器学习+分型,要素过多,没有思路的同学可借鉴,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天给同学们分享一篇生信文章“Diagnostic, clustering, and immune cell infiltration analysis of m6A regulators in patients with sepsis”,这篇文章发表在Sci Rep.期刊上,影响因子为4.6。

结果解读:
脓毒症中m6A调节因子的转录改变
为了鉴定脓毒症患者中编码m6A调节因子的差异表达基因,使用“limma”软件包进行差异表达分析,以分析来自GSE65682数据集的802份血液样本,即760份来自脓毒症患者,42份来自健康对照。热图显示,脓毒症患者和健康对照组之间17种m6A调节因子的表达显著不同(图第1A段)。作者发现METTL3、METTL14、RBM15、RBM15B、CBLL1、YTHCD1、YTHDC2、YTHDF1、YTHDF2、YTHDF3、HNRNPC、LRPPRC、HNRNPA2B1、RBMX、ELAVL1和FTO的表达在脓毒症患者中显著降低,而IGFBP2的表达在脓毒症患者中显著升高。然而,作者观察到WTAP、FMR1和ALKBH5的表达没有显著差异(图1B)。
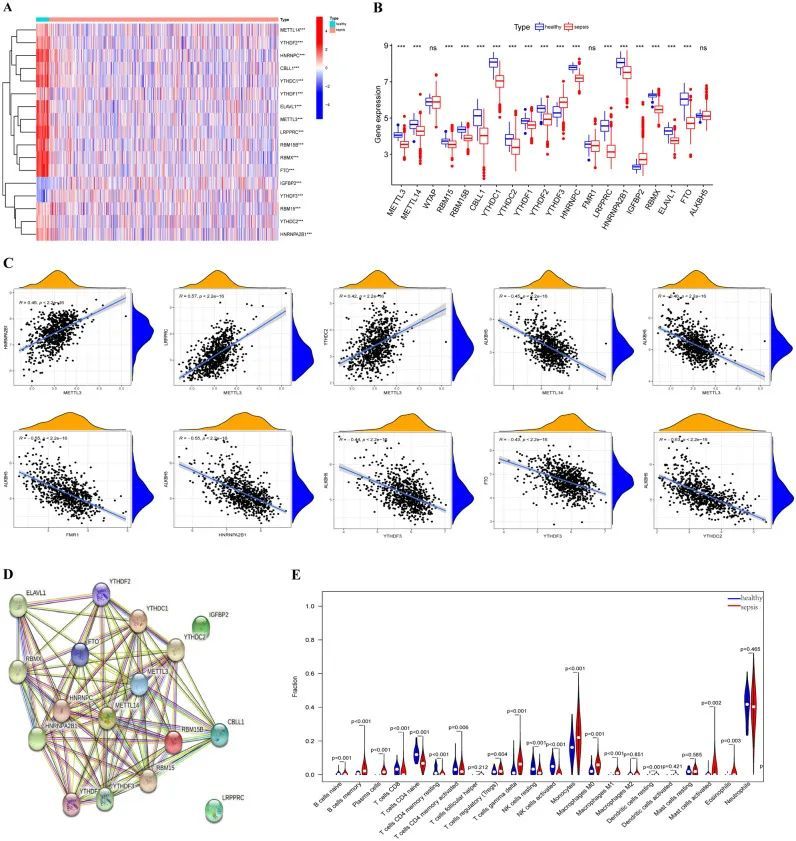
随机森林(RF)模型和支持向量机(SVM)模型的构建
为了建立诊断m6A相关基因特征,分别构建了RF和SVM模型。显示|残差|和|残差|值的反向累积分布的箱图显示,RF模型的残差分布低于SVM模型的残差分配(图2A,B)。基于上述结果,RF模型被认为是预测脓毒症发生的更合适的模型。然后,根据模型误差与决策树数量之间关系的概述,选择500棵树作为该模型中的变量,呈现出稳定的误差概率(图2C)。接下来,作者通过评估m6A相关基因的重要性对其进行排序,结果表明FTO、HNRNPC和RBMX是最重要的3个基因。此外,ROC分析用于比较两个模型的准确性,以及RF模式的AUC值
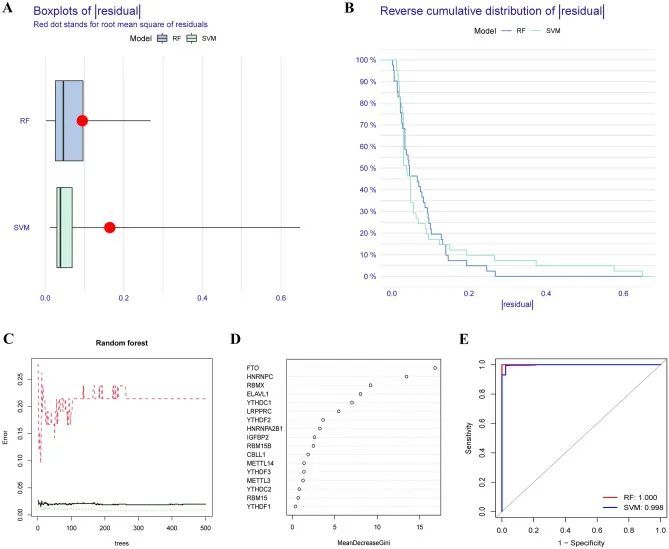
预测列线图的构造
为了更好地评估脓毒症的风险,构建了一个列线图来结合10种推荐的m6A调节因子(图第3A段)。在该预测列线图中,FTO、HNRNPC、RBMX、YTHDC1、LRPPRC和RBM15B的表达水平与脓毒症患者的风险评分呈负相关,并被视为脓毒症的保护因素。使用校准曲线来确定列线图的预测精度(图3B)。DCA表明,脓毒症患者可以从基于该列线图的预测决策中受益,因为用m6A调节因子相关模型构建的决策曲线显示出最大的益处。
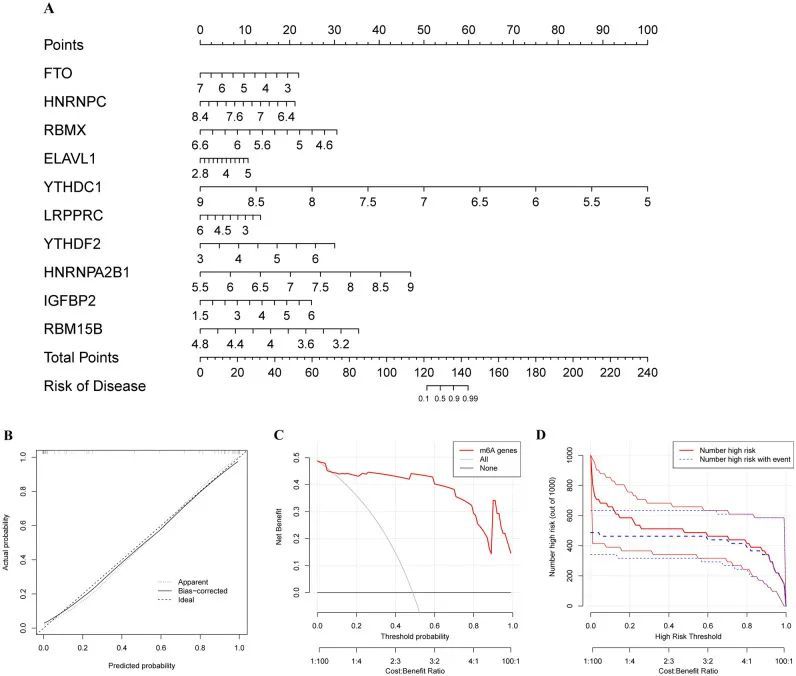
m6A调节器的亚型分析
为了进一步确定m6A调节因子的表达模式与脓毒症亚型之间的关系,使用一致聚类方法来揭示m6A相关基因的作用,并且当 = 2,脓毒症患者被分为两个亚组(m6A亚型A和B),两组之间的相关性高于其他k值(图4A)。热图显示了两组之间m6A相关基因表达的差异(图4B)。METTL3、METTL14、RBM15、RBM15B、CBLL1、YTHDC1、YTHD2、YTHDF1、YTHDF2、YTHDF3、HNRNPC、LRPPRC、HNRNPA2B1、RBMX和ELAVL1在m6A亚型A中上调,而IGFBP2和FTO在m6A聚类B中上调。主成分分析结果表明,这两个m6A亚型可以显著区分。此外,单样本基因集富集分析(ssGSEA)用于量化两者之间浸润免疫细胞的差异
m6A基因标记的构建
为了研究m6A相关亚型的潜在生物活性,作者在m6A亚型A和m6A亚型B之间鉴定了699个与m6A相关的亚型相关的DEG(图6A)。接下来,使用“limma”软件包进行功能分析,以揭示DEG的作用。在生物过程(BP)类别中,DEG主要参与蛋白酶体蛋白质分解代谢过程、蛋白酶体介导的泛素依赖性蛋白质分解代谢和细胞成分分解。DEG在细胞成分(CC)类别中的富集主要集中在分泌颗粒膜、核膜和细胞器外膜。DEG的分子功能(MF)主要与泛素样蛋白转移酶活性、泛素蛋白转移酶活力和镁离子结合有关(图6B)。此外,KEGG分析表明,DEG在神经退行性变多种疾病的途径中富集
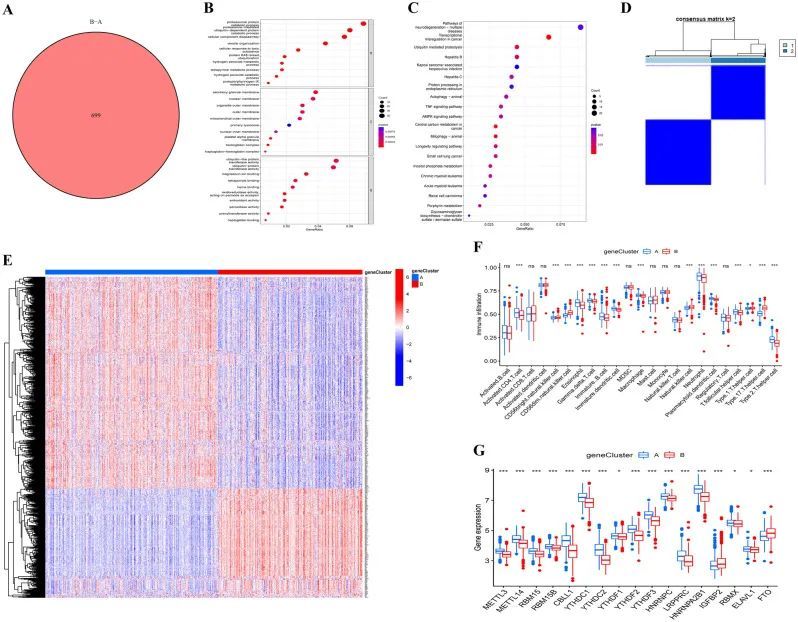
m6A亚群与细胞因子的相关性
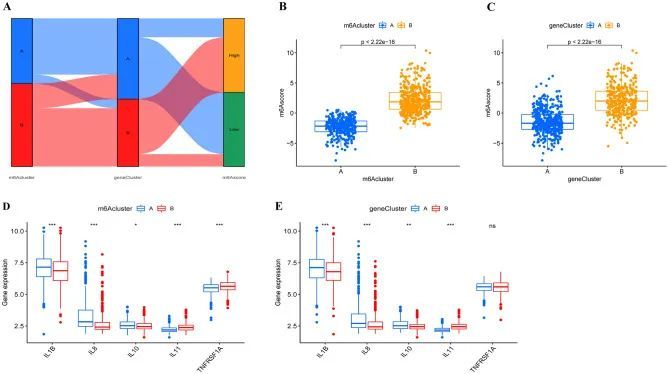
根据m6A相关基因的表达,使用主成分分析(PCA)来确定每个脓毒症患者的评分,该评分被定义为m6A评分。桑基图显示了两个m6A聚类、两个基因聚类和两个m6A得分的分布(图7A)。此外,作者发现m6A亚型和基因亚型之间的m6A评分存在显著差异(图7B),m6A亚型B和基因亚型B的m6A得分较高,揭示了m6A评分与免疫激活的相关性。在脓毒症的整个过程中,炎症因子的失衡是脓毒症病因的关键32。进一步的研究揭示了脓毒症中m6A模式与炎症因子之间的关系,包括白细胞介素(IL)-1β、IL-8、IL-10、IL-11和TNF受体超家族成员1A(TNFRSF1A)。
总结
作者对脓毒症患者中m6A调节因子的综合分析揭示了影响免疫细胞浸润特征和炎症因子水平的调节机制,并构建了一个列线图来确定它们在预测脓毒症风险中的价值。基于17种重要的m6A调节因子的表达,鉴定出两种m6A亚型,亚型B可能与脓毒症明显相关。
这篇关于4+m6A+机器学习+分型,要素过多,没有思路的同学可借鉴的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









