本文主要是介绍填报哪所大学更加容易脱单呢?“大数据”分析来为你解答,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
随着高考成绩纷纷揭晓,相信大家也纷纷开始考虑起填报哪所学校,填报哪个专业,在上一次小编分析了一下最有“钱景”的专业之后(Python数据分析来解析,2021年度最具“钱景”的大学专业),能否顺利的脱单恋爱相信也是各位考生考虑的事情,今天小编就带大家来看看全国众多高校中,哪几所高校比较容易脱单,哪几所高校脱单比较难以及为什么比较难脱单。
01
高校单身率排名
首先我们来看一份来自网络调查的“2020年中国高校单身率排行榜”,其中可以看到的“中华女子学院”以及“山东师范大学”这两所高校的单身指数是最高的,可能是受到了男女比例失调的影响,
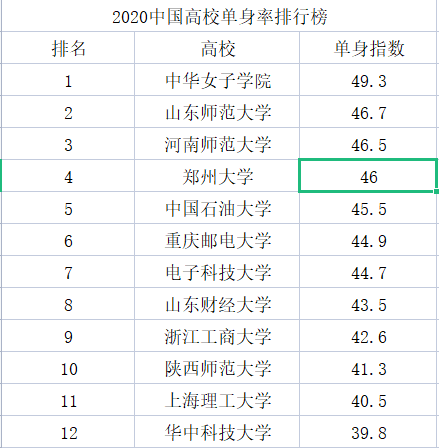
另外我们也可以发现,榜单上面的北方高校多于南方高校,而师范类高校更是占到了榜单Top50的半壁江山,所以之后要去师范类学校念书的考生们可能需要做好心理准备了哦
02
十大“男光棍”与“女光棍”院校
当然要是我们再看的细一点,对于男生来说,中国十大“男光棍”院校如下所示,
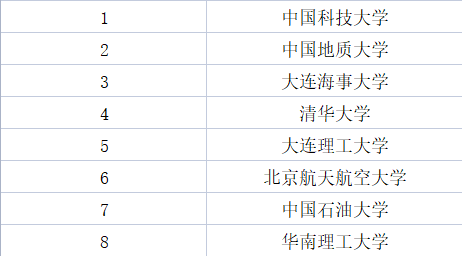
其中我们不难发现“理工院校”是比较容易产生众多男性“单身狗”的,其中清华大学也赫然出现在榜单中,不难想象可能是里面的学霸专心于学习,没时间找对象了,而对于女生来说,十大“女光棍”院校的第一名倒是有点让人出人意料,如下所示
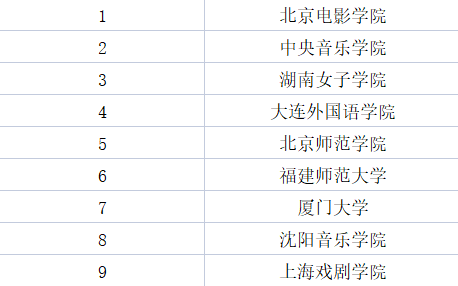
真可谓是“旱的旱死,涝的涝死”,女生多了则不太容易脱单,而男生多了也不太容易脱单,看来还是得去综合性的大学比较好。
03
不同专业的脱单率
聊完了学校,我们来聊一下专业,究竟哪些专业的单身率特别的高呢?可能还和男女比例还是脱不开关系,从下面的可视化绘图当中我们发现,
bar = (Bar().add_xaxis(majors[::-1]).add_yaxis("单身率", nums[::-1]).reversal_axis().set_global_opts(title_opts=opts.TitleOpts(title="不同专业的单身率"),yaxis_opts=opts.AxisOpts(axislabel_opts={"rotate":30}),).set_series_opts(label_opts=opts.LabelOpts(position='right'))
)
bar.render("major.html")
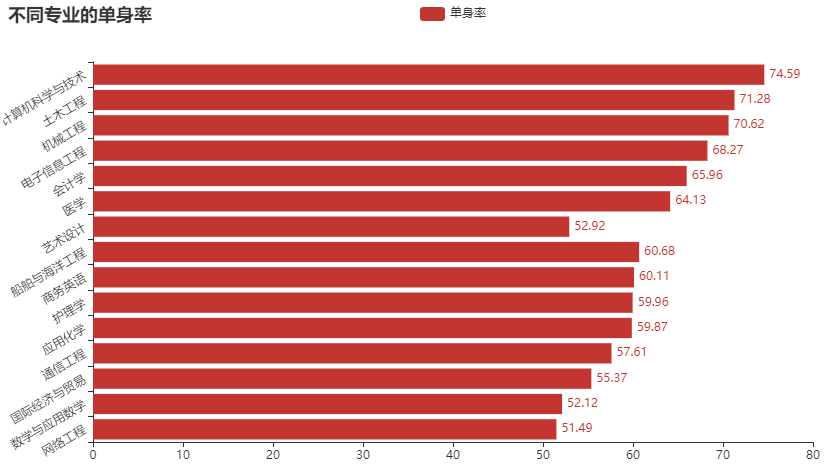
像是计算机专业、通信工程、电子信息工程等专业,男女比例差距悬殊,基本上都是男生,而像是会计学、商务英语、护理学等,基本上都是女生,身处在类似的环境中,要想脱单就得跨专业、跨学院等等,自然也就困难了一些,

当然除了男女比例失调之外,学业的繁忙也导致学生可能没有时间与精力与维持一段稳定的感情,例如建筑学专业、法学专业以及医学专业等,其他的大学情侣日常可能是吃饭逛街看电影等等,而这些专业的学生不是在忙学习就是在去学习的路上,熬过了漫长的本科生的时光,后面可能还有更加艰苦的研究生学习生涯等着他们,

04
写在最后
当然无论是脱单困难与否,作为学生还是应该将学习放在首要的位置,毕竟四年的时间一眨眼就过去了,毕业之后面对的就是来自社会的各种压力与考验,当然谈恋爱对于大学生来说也是一场必修课,从这过程当中去学习怎么样去经营好一段感情、维护好一段感情,无论最后的结果如何,都是人生成长过程中非常宝贵的经验与财富,所以当遇到了这么一个人的时候也一定要好好的去珍惜与把握,努力一起走下去!
分享10个常用的Python内置函数,可以极大的提高效率哦!!

厉害了,Python画出高颜值交互股票K线图

Python分析热门话题“不生孩子的人后来都怎么了”,看看丁克家庭最后都怎么样了

点点分享

点点赞

点点在看

这篇关于填报哪所大学更加容易脱单呢?“大数据”分析来为你解答的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






