本文主要是介绍【论文阅读】【基于方面的情感分析】Modelling Context and Syntactical Features for Aspect-based Sentiment Analysis,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- Modelling Context and Syntactical Features for Aspect-based Sentiment Analysis
- 一、该论文关注的是解决ABSA问题的哪个方面?驱动是什么?具体目标是解决什么问题?
- 二、该论文采用的方法是什么,方法的核心原理是什么?
- 三、该方法是如何提出的,是开创性的方法还是对已有方法进行的改进,创新点是什么?
- 四、该论文展示的结果如何?使用的是什么数据集?
- 五、该论文是否提出还有需要改进的地方,即future work?
- 六、该论文的实际应用点在于什么?
Modelling Context and Syntactical Features for Aspect-based Sentiment Analysis
一、该论文关注的是解决ABSA问题的哪个方面?驱动是什么?具体目标是解决什么问题?
方面:统一两个子任务的架构+改进模型(将句法信息集成到上下文嵌入模型中)
驱动:
①基于方面的情感分析(ABSA)包括两个概念任务,即AE(aspect extraction)和AOE(Aspect-oriented Opinion Extraction)。然而,报告的大多数工作只关注于这两个子任务中的一个,最近有研究试图开发一种综合解决方案,通过统一标记方案将两个子任务制定为单个序列标记,从而同时解决这两个任务,但是这种解决方式会带来开销和复杂度。
③NLU的最新进展引入了上下文嵌入语言模型(contextualized language models),即OpenAI GPT 、BERT和RoBERTa。这些模型可以捕捉单词使用的特征,并考虑单词出现的不同文本上下文。但是很明显,他们无法确定多字方面的边界。例如,提取器将“食品质量”的多词表达分解为“质量”和“食物”。这篇论文认为这一缺陷是由于上下文化嵌入无法编码丰富的语法信息造成的,之前的ABSA研究中没有充分利用句法信息。
具体目标:
①构建一个端到端的ABSA解决方案,而不是单独考虑任务【端到端的ABSA:即输入一个上下文有关联的句子S,端到端的ABSA旨在提取由m个方面词组成的序列A,输出每一个方面词的情感极性。】
②将句法信息集成到上下文嵌入语言模型中。
二、该论文采用的方法是什么,方法的核心原理是什么?
方法的提出:
-
①一个由AE和AEC组成的ABSA解决方案:
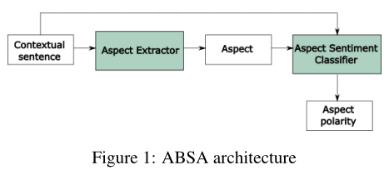
-
其中的AE——命名为CSAE(contextualized syntax-based aspect extraction)
- POS embeddings
- dependency-based embeddings
- RoBERTa layer
-
其中的ASC——命名为LCFS-ASC(local context focus on syntax -ASC)
- 在Zeng et al. (2019) 的工作的基础上做改进,采用依赖树中两个词之间的最短路径作为句法相对距离(SRD)
综上:
首先对AE和ASC两个子任务分别地进行改进,提出了CSAE和LCFS-ASC,然后综合构建了一个端到端的ABSA解决方案。
核心原理:
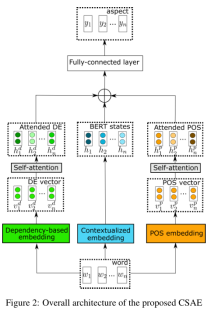
- CSAE
CSAE的架构如下图所示,输入一个句子,然后分别进行三个处理:
-
上下文嵌入contextualized embedding【预训练】
使用的是RoBERTa (Liu et al., 2019) -
POS(a part-of-speech) embedding【利用词法信息】
首先通过一个词法分析的工具(Universal POS Tags)来得到句子对应的词性标签序列,然后通过一个嵌入矩阵将词性转化为向量,接着输入到自注意力层来建模词性之间的依赖关系。 -
dependency-based embedding【利用句法信息】
使用的是(Levy and Goldberg, 2014) ,利用句法信息的核心仍是依赖树。
得到句子的表示后,通过一个全连接层来预测相应的情感极性。
-
LCFS-ASC
这个架构与LCF-BERT的思路相同,实际是这个模型上的改进。LCF-BERT的核心是:称[CLS]+S+[SEP]+A+[SEP]为global context(全局文本),而[CLS]+S+[SEP]为local context(上下文文本)。如何确定上下文是否属于特定方面的局部语境是重要的问题之一为了在local context引入属性词的信息,LCF-BERT中提出了两种方法(CDM/CDW)进行Local Context Focus(LCF)。
CDM即为context dynamic mask,是指根据与属性词之间的距离来屏蔽句子中的一些单词;而完全屏蔽某些单词可能过于绝对,因此CDW(context dynamic weighting)则是按照与属性词之间的距离为单词赋予一个0到1之间的权重。这里的“距离”就是通过位置计算的。LCFS-ASC与LCF-BERT的不同之处就在于,在进行CDM/CDW时所使用的单词之间的距离,不再是通过位置计算,而是两个单词在句法解析树中的距离。
三、该方法是如何提出的,是开创性的方法还是对已有方法进行的改进,创新点是什么?
参考的观点或模型:
-
①CSAE中:
上下文嵌入部分:使用的是RoBERTa (Liu et al., 2019)
POS部分:使用了词法分析的工具——Universal POS Tags
依赖嵌入部分:使用的是(Levy and Goldberg, 2014) -
②LCFS-ASC是在Zeng et al. (2019) 的工作的基础上做改进,Zeng et al. (2019) 的工作中,利用local context focus(LCF)机制来降低远离本地上下文的单词的贡献。这篇论文就是在此基础上引入句法信息,形成的local context focus on syntax(LCFS)机制。
创新点:
本文的模型拆解开来实际上都是一些过去提出的模型,这篇论文的创新点在于对这些模型进行了组合和局部的改进。其次是在消融实验中研究了SRD的重要性。
①提出了多通道CSAE模型,该模型将语法aspect分解为上下文特征,以改进顺序标注;
②改进LCF-BERT提出了LCFS-ASC(改进点在于,距离不再是通过位置计算,而是两个单词在句法解析树中的距离),它可以分析单词之间的句法联系,从而更好地理解与目标词相关的本地语境
③通过探究LCF层的注意分值(attention score)研究了SRD的重要性【一个可视化+分析】
四、该论文展示的结果如何?使用的是什么数据集?
使用的数据集:
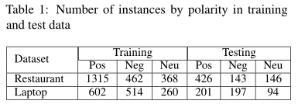
实验指标:F1
实验结果:
①AE单个任务结果+消融实验
- 使用了词法信息和句法信息后,f1值有了较大的提升(CSAE>RoBERTa-AE)
- 句法信息带来的提升更加明显(RoBERTa-Dep>RoBERTa-POS)
②单个ASC任务+消融实验
- 使用了LCFS的策略之后,模型性能有了很大的提高
- CDW优于CDM(因为CDM可能会错误地忽略有用的信号,另一方面,CDW强调灵活性,并允许根据其句法依存树上future sign和方面术语的关系提供微小权重)
- LCFS稍微优于LCF
五、该论文是否提出还有需要改进的地方,即future work?
我们提出了一个端到端的ABSA解决方案,将方面提取器和方面情感分类器串联起来。研究结果表明,利用句子的句法结构可使情境化模型在ASC和AE任务中提高现有的工作。我们提出的方面情感分类器优于训练后的ASC模型,并能够创建一个领域独立的解决方案。所提出的SRD允许方面情感分类器聚焦于关键情感词,通过基于依赖的结构修改目标方面词。实质性的改进突出了最近语境化嵌入模型在“理解”句法特征方面的性能不足,并提出了开发更多语法学习语境化嵌入的未来方向。
我们可以尝试通过应用统一的标记方案来将我们提出的CSAE体系结构用于集成方法;从而可以同时实现方面提取和情感分类。
六、该论文的实际应用点在于什么?
首先,这篇论文与其他论文的不同之处在于,其创建的并不是一个直接的模型,而是先独立地解决AE和ASC问题,然后统一架构。
其次,这篇论文虽然是许多已有模型的组合和局部改进,在引入“语境”(即在ABSA的问题解决中仍然关注上下文的信息)的基础上,关注句法信息(也是利用的依赖树的思想),是一种已有思想的新组合。
综上,通过这种组合和局部改进的思想,这篇论文提出的是一个端到端的ABSA解决方案,即输入一个上下文有关联的句子S,端到端的ABSA旨在提取由m个方面词组成的序列A,输出每一个方面词的情感极性,是一个很“自动化”的过程。
这篇关于【论文阅读】【基于方面的情感分析】Modelling Context and Syntactical Features for Aspect-based Sentiment Analysis的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





