本文主要是介绍独家数据!搭载率逼近30%!智能网联从「偏科」到「全能」战役打响,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
从早期的智能座舱(斑马、比亚迪DiLink),到后来的智能驾驶(理想、小鹏的NOA),再到今年刮起的中央计算、驾舱一体风潮,汽车智能化正在从偏科走向全域智能化的关键周期。
本周,高工智能汽车研究院发布独家数据,2023年1-9月,中国市场前装同时标配搭载智能座舱+车联网+OTA+智能辅助驾驶(L2为基线)交付新车416.29万辆,同比增长67.64%,前装搭载率升至28.09%。
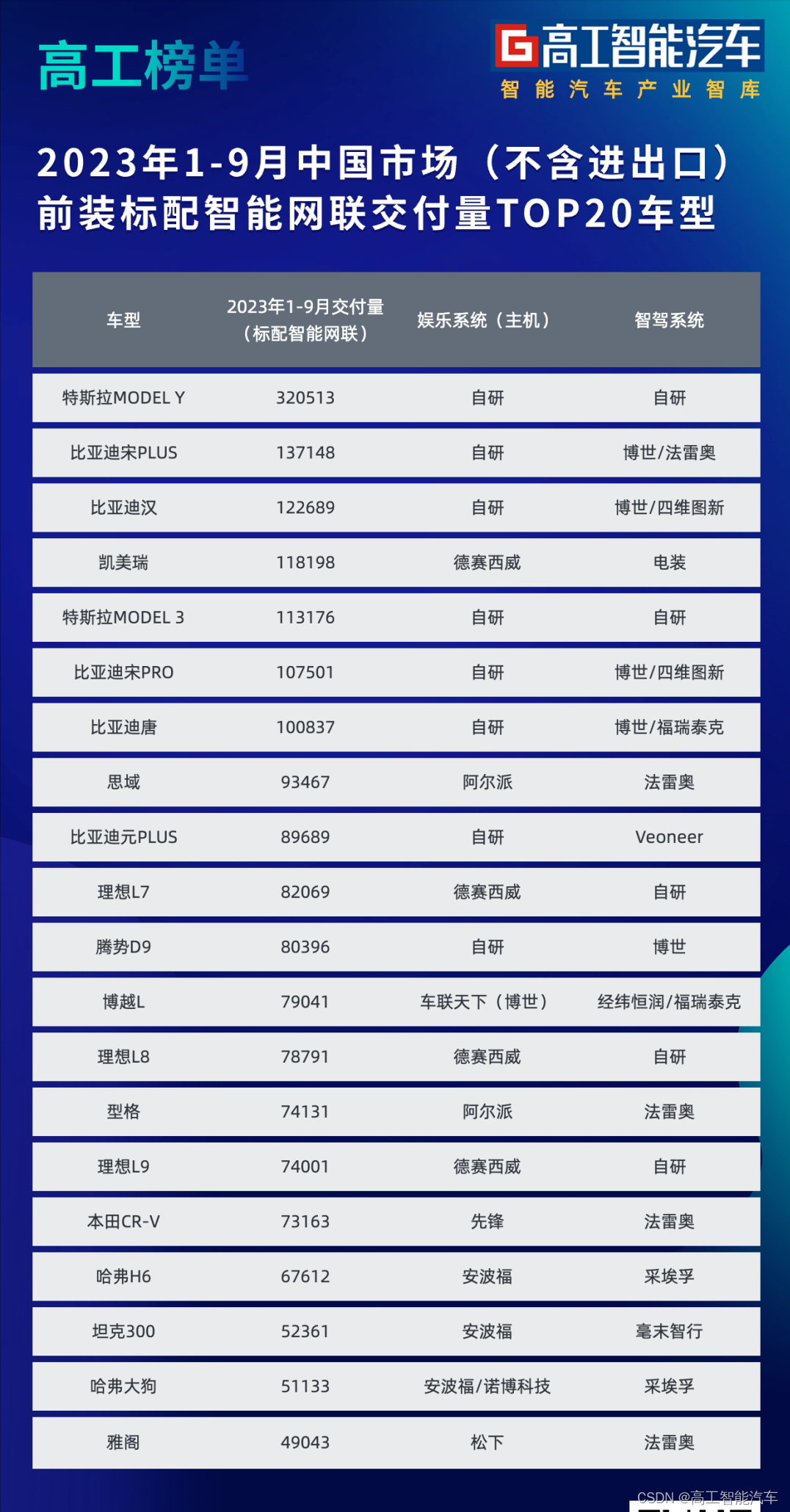
与此同时,整车智能化开始进入电子架构升级(中央计算、区域控制)、底盘(线控)智能化的新周期。整体行业的风向,也从过去几年激进推动智能化功能落地,转向基础设施(电子架构)的重构阶段。
高工智能汽车研究院监测数据显示,目前国内多个自主品牌(包括理想、小鹏、埃安、零跑、哪吒等新势力)已经正在开发全新一代中央计算E/E架构核心技术与车型产品,以进一步提升整车的智能化集成水平。
此外,在传统品牌方面,去年8月,长安汽车与德赛西威签署战略合作协议,双方将在域控制器领域深入合作,共同打造行业领先的中央计算机产品,推进中央计算机相关关键零部件的研发及产品量产落地。
今年7月,埃安Hyper GT首搭AEP 3.0平台和星灵架构正式上市交付。星灵架构由3个核心计算单元+4个区域控制器构成,成为行业首个量产的车云一体集中式电子电气架构。
从数据来看,2022年中国市场(不含进出口)前装标配搭载座舱及智驾域控制器合计279.78万套,同比增长55.21%;预计2023年将突破500万套,前装搭载率突破20%大关。
同时, 在车身网关融合域(包括与座舱、中央控制等融合)、区域控制方面,2023年也将突破20%,多种形态的「中央计算+区域控制」架构进入规模化增量周期。
另一个有意思的地方是,这场大规模的整车电子架构变革,并非从传统的高端豪华车市场开始。原因是,面向普及化的智能电动汽车更需要降本。
以零跑为例,目前,该品牌的主力车型交付均价处于10-15万元区间;在过去传统燃油车时代,这个细分市场的技术远远落后于豪华品牌。但今天,这样的局面正在改变。
比如,今年7月31日,零跑汽车对外发布全域自研的“四叶草”中央集成式电子电气架构,实现座舱域、智驾域、动力域和车身域的系统融合。
四叶草架构根据芯片不同,共推出标配、中配、高配三种配置可选,覆盖10至30万级车型。同时,未来还将考虑国产芯片适配,这将进一步降本。
其中,“标准解决方案”为高通8155+NXP S32G中配(集成泊车、网关,智驾独立),这套方案类似目前小鹏G9、G6搭载的方案。
中配方案为高通8295+NXP S32G高配(集成L2/L2+智驾),高通8295的冗余算力也给舱驾一体提供了更多的可能性。

高配方案则为高通8295+NXP S32G高配+英伟达OrinX(集成L2、高阶智驾独立),这是目前最强的智驾/座舱算力+车载网络处理方案之一。
按照官方给出的数据,这套架构在控制器、线束方面也进行了大幅优化,同时拓宽数据带宽、以及电源管理模式,让系统间的交互做到更高效。
“我们希望优化成本结构,用最适合的成本做好的能力做全标配,而不是最强的能力最高的成本做选配。”对于架构升级,小鹏汽车坚定认为,未来新车型研发周期将缩短20%,基于架构部分的零部件通用化率最高可达80%。
另一组数据显示,集成度更高的中央超算及区域控制架构平台,可以实现整车综合研发成本降低50%,智能体验迭代周期缩短30%,极速OTA速率提升300%。
SOA分层式整车及数据接口设计平台,可以帮助车载智能系统的软件适配成本降低85%。实现座舱整体的基础原子化能力可以标准化复用。
此外,集中域控制相比于分布式多域更高效、平台化效应更为突出。典型的代表,就是整车OTA,“车上的设备更容易远程管理,也更方便通过OTA进行更新迭代。”
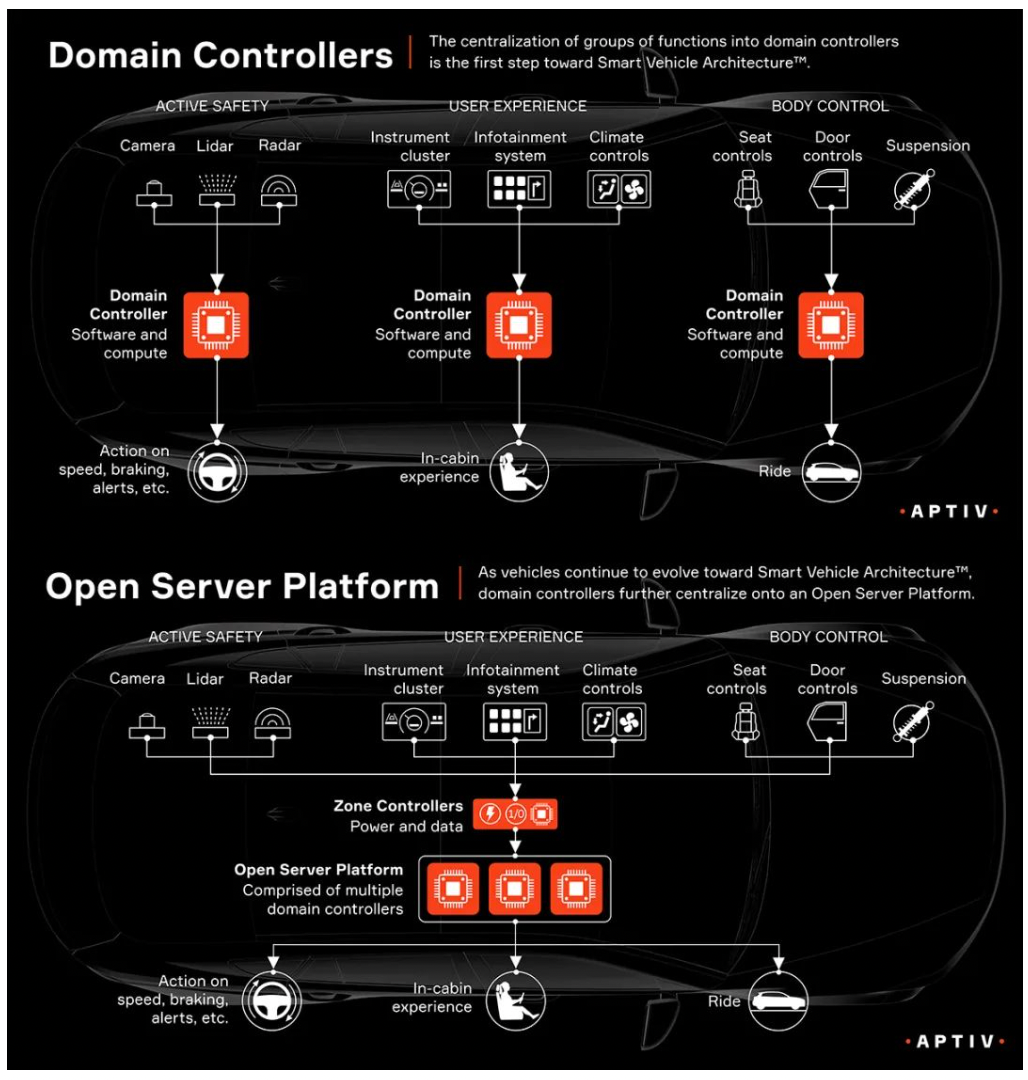
一组来自安波福的数据显示,一旦使用中央计算+区域控制器,可以整合多个ECU,与传统的分布式架构相比,大约可以降低25%的重量,以及25%的线束成本。
按照业内人士的评价,“目前大部分车企的这一代架构还不是真正意义上的整车集中,下一代会向整车集中化架构演进,中央计算的程度会更高。”
而中央计算+区域架构给传统供应链带来的冲击在于,过去为整车提供不同ECU的供应商,将开始进入新一轮洗牌周期。比如,传统车身、网关供应商,将逐步被座舱域控制器、中央域控制器供应商替代。
比如,在小鹏汽车,新车型的上市,之前的中央网关(供应商:经纬恒润)被集成至中央域控制器,经纬恒润也被伟创力、航盛等供应商替代。
而在文章开头部分展示的车型供应商体系,也会随着新的电子架构的升级,出现更多的变化。或许,到2025年,会看到全新的整零关系网。
这篇关于独家数据!搭载率逼近30%!智能网联从「偏科」到「全能」战役打响的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







