本文主要是介绍PP-Matting:trimap free的高精度自然图像抠图,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文:https://arxiv.org/abs/2204.09433
代码:https://github.com/PaddlePaddle/PaddleSeg
1、动机
在自然图像抠图领域,大多数方法都是基于Trimap来做抠图,这种trimap-based的方式在抠图时还需要用户绘制一个trimap作为模型输入,这大大限制了实际中的应用。虽然也有一些trimap-free方法提出,但其抠图质量往往不尽如人意,比如前景-背景模糊、过渡区域细节模糊等。
因此,本文提出了一种trimap-free的自然图像抠图方法。该方法提出了一个高分辨率细节分支(HRDB)在保持特征分辨率不变的情况下提取前景的细粒度细节,还提出了一个语义分割上下文分支(SCB)来避免在细节预测中因语义上下文缺失而引起局部歧义。
2、基础概念
抠图与分割的区别:
如图1所示,抠图生成的前景更为精细,而分割生成的前景在边缘处比较粗糙:

抠图公式表达:
对于一幅图像,其由前景
和背景
组成。原图第i个像素的值,可以有前景、背景通过一个α系数进行线性组合:
![]()
α对前景来说,是一个不透明度系数。因此,图像抠图是高度不适定的,它需要求解七个值(前景的RGB、背景的RGB、α)但只有三个值已知(原图的GRB)。
trimap-based:
为了降低解决图像抠图问题的难度,之前有些研究提出了使用trimap来作为辅助输入。trimap将图像分为三个区域:前景、过渡区域、背景,以此引入先验来辅助模型的学习。这种方式仅适用于PS之类的应用中用户可以方便绘图的场景,对于自然场景、视频抠图等场景,基于trimap的方法非常不方便。
trimap-free:
既然让用户给出trimap不太合适,那就有研究提出了一些替代方案:给出更容易获取的背景图和原图,或者只给出原图但通过第一阶段的模型先预测一个trimap再送入第二阶段进行抠图。这两种方式都有缺点:前者对背景图要求和前景一致,不能有丝毫误差;后者则严重依赖第一阶段的trimap生成质量,容易产生误差累计。因此,最好的方式是直接只使用原图,完全trimap-free的进行Matting。已有研究提出这样的方法,但效果都不理想。
3、方法
3.1. 网络结构
正确的语义上下文和清晰的细节是高精度Matting的关键。在trimap-based的方法中,trimap提供了足够的语义上下文,而模型只需关注过渡区域即可,所以trimap-based的方法才能效果不错。那么要是在trimap-free方法中也获得语义上下文,是不是就可以像trimap-based方法那样获取精确的结果了呢?
因此,作者提出了一个网络结构,包含了SCB分支来获取语义上下文,同是还有一个HRDB分支来获取高分辨率细节。具体网络结构如图2所示:
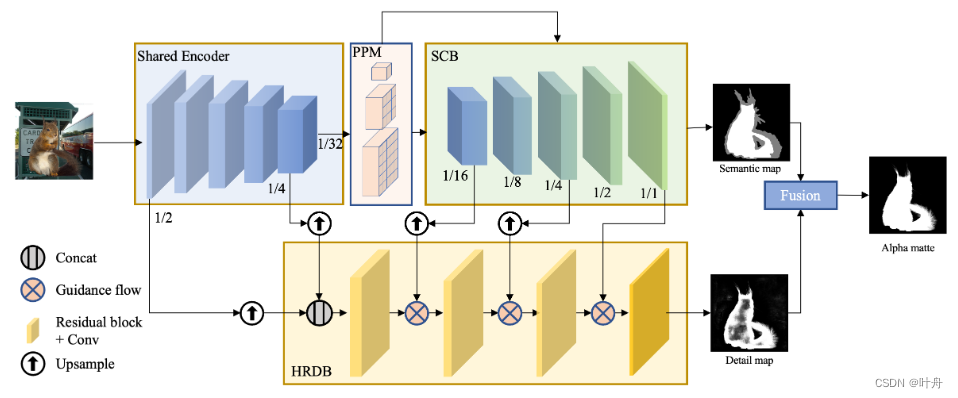
网络结构描述:
backbon使用的是HRNet,也是上图中的Shared Encoder;
backbone最后一个stage的输出送入金字塔池化(PPM)模块,以获取更为丰富的语义上下文;
SCB分支:PPM得到的feature map和Shared Encoder的1/32倍下采样的feature map作为SCB的输入;SCB由五个块组成,每个块由Conv、BN、ReLU以及一个双线性上采样组成;此外,SCB的输出也被一个包含三个类别(前景、背景、过渡区域)的语义分割任务监督,如图2中的semantic map,和trimap非常相像;
HRDB分支:Shared Encoder的中间特征通过上采样后concat起来作为HRDB的初始输入,然后分别从SCB的1/16 、1/4中间特征引入引导流(Guidance Flow),以引入语义信息,辅助HRDB获取更为精细的细节;
Guidance Flow:引导流的结构如图3所示,其将来自SCB的语义上下文feature map和HRDB的细节feature mapconcat起来,送入ConvBNReLU和ConvBNSimoid得到Guidance map,然后再与来自HRDB的细节feature map点乘、相加,得到HRDB的下一级feature map;

Guidance Flow可用公式表示为:
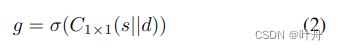
![]()
3.2. 损失函数
loss包含三部分:
第一部分,SCB中的语义分割loss,是三分类分割任务的交叉熵损失:
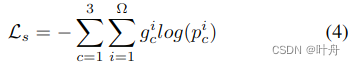

第二部分,HRDB中的细节loss,仅在过渡区域起作用,由alpha预测loss和梯度loss组成:


第三部分,最终的alpha matte loss,由alpha预测loss、梯度loss、成分loss组成,其中,成本loss是预测图与原图的绝对差:

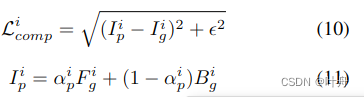
因此,最终的loss是上述三部分loss的加权组合:

4、实验结果

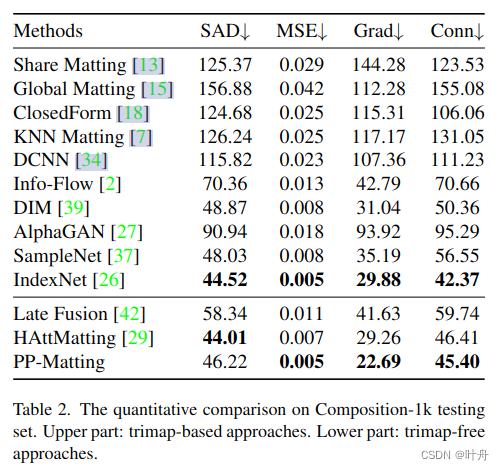


5、写在后面
PP-Matting提出了一种trimap-free的方法,通过引入SCB和HRDB分支,并在两个分支之间增加Guidance Flow来进行信息融合,达到了trimap-free方法中的SOTA,非常适合应用与自然图像抠图。
之前不管是trimap还是背景图,都需要用户使用时提供额外的辅助信息,这在实际使用时相当不便。而trimap-free方法只需要用户提供一张图片,即可得到最终的抠图效果,这大大方便了使用。未来一定是trimap-free的天下~
这篇关于PP-Matting:trimap free的高精度自然图像抠图的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








