本文主要是介绍再也不用担心seo标题相似度过高了,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我们在做seo原创文章的时候,标题的原创同样是非常重要,这是百度是否收录的关键因素,原创标题的目的一是增加标题的吸引力,二是标题在百度搜索展示中没有相似度过高的标题。今天我们用python简易做一个查百度展现的标题与自己的标题的相似度,从而判断标题是否要修改。
一、目标标题
在文本中,放入我们事先准备好的标题。这次以我本网站的标题做一个简单的测试,比如测试“今日分享:如何用python进行seo文章发布”
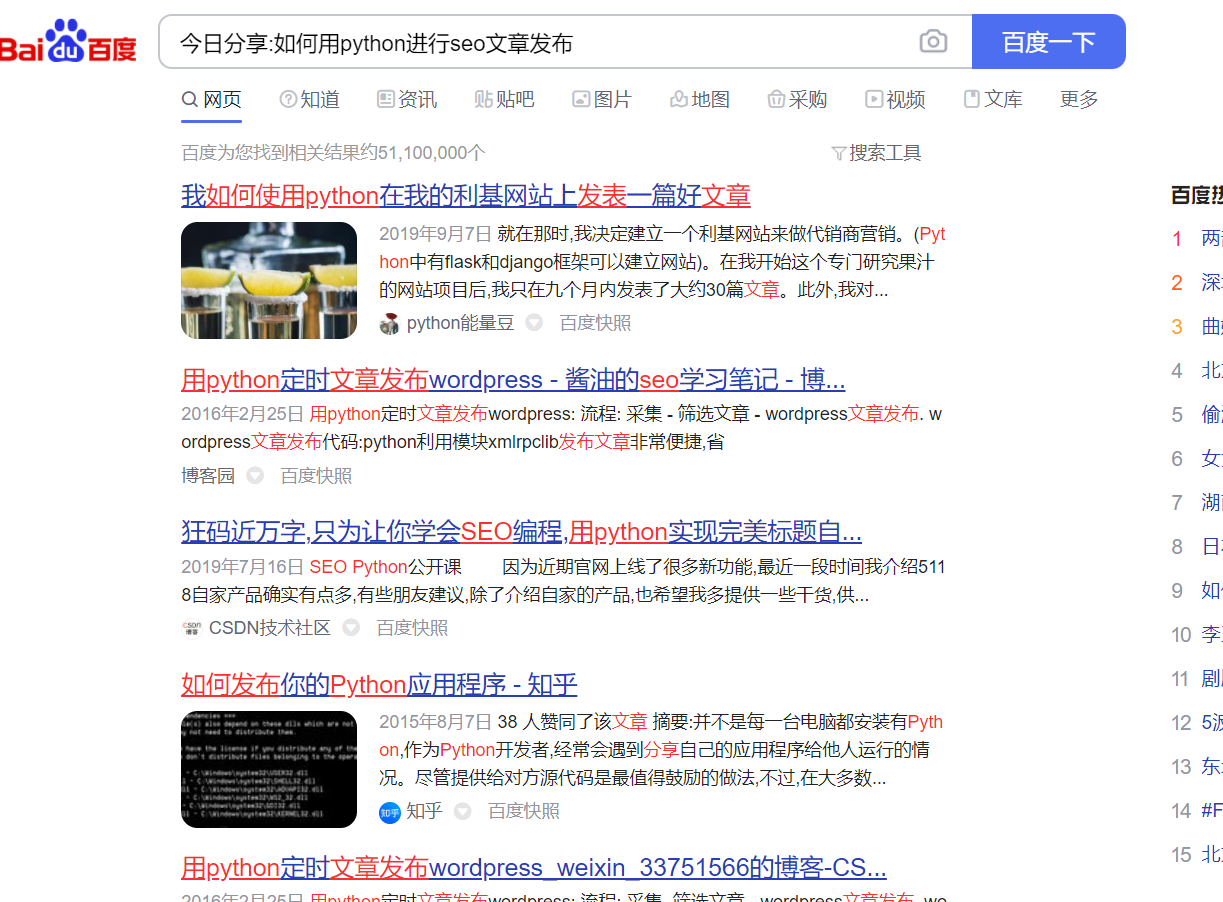
二、百度展现标题
用测试的标题在百度上搜索结果,查询到百度首页展示的标题,我们用python中的beautifulsoup解析库,去解析中百度展现的标题列表。

三、检测相似度
将我们的原标题和百度首页的标题列表,进行循环逐一判断其相似度的结果。

四、运行效果

从相似度来看,每个相似度低于0.5或0.6,那么目标标题在百度是没有飘红,是一个原创优质的标题,那么我们就可以进行原创文章的撰写了
这篇关于再也不用担心seo标题相似度过高了的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






