本文主要是介绍读程序员的制胜技笔记02_算法与数据结构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 认知偏见
1.1. 程序员也是人,他们和其他人在软件开发实践中有着同样的认知偏见
1.2. 只有你的同事真正关心你是如何做事的——其他人都只想要一个好的、有效的产品
1.3. 高估了不使用的类型
1.4. 不关心正确数据结构的好处
1.5. 认为算法只对库作者重要
2. 理论
2.1. 理论可以是压倒性的和不相关的
2.2. 算法、数据结构、类型理论、Big-O表示法和多项式复杂度可能看起来很复杂,但与软件开发无关
2.3. 现有的库和框架已经以一种优化和经过良好测试的方式处理了这些问题
2.4. 你永远不要从头开始实现算法,特别是在对信息安全有较高要求或开发时限紧张的情况下
2.5. 为什么关心理论
2.5.1. 从头开始实现算法和数据结构
2.5.2. 正确地决定何时需要使用它们
2.5.3. 帮助你理解不同决策带来的成本
2.5.4. 帮助你理解正在编写的代码的可伸缩性特征
2.5.5. 帮助你向前看
3. 算法
3.1. 一套解决问题的规则和步骤
3.1.1. 它们只需要为你的需要工作
3.1.1.1. 根据你的需要,可以有更智能的算法
3.1.2. 它们不一定要创造奇迹
3.1.3. 它们能一点儿都不聪明,但确实有效,而且有道理
3.1.3.1. 算法本身并不意味着它很聪明
3.2. 检查一个数组的元素以找出它是否包含一个数字
3.2.1. 算法1
3.2.1.1. public static bool Contains(int[] array, int lookFor) {
for (int n = 0; n < array.Length; n++) { if (array[n] == lookFor) { return true; } } return false; }
3.3. 如果你知道数组只包含正整数,你可以为非正数添加特殊处理
3.3.1. 算法2
3.3.1.1. public static bool Contains(int[] array, int lookFor) {
if (lookFor < 1) { return false; } for (int n = 0; n < array.Length; n++) { if (array[n] == lookFor) { return true; } } return false; }
3.3.1.2. 算法运算速度的提升幅度取决于你用负数作参数调用它的次数
3.3.1.3. 在最坏的情况下,你的函数将总是以正数作参数调用,这样就会产生额外的不必要的检查
3.3.2. 算法3
3.3.2.1. public static bool Contains(uint[] array, uint lookFor) {
for (int n = 0; n < array.Length; n++) { if (array[n] == lookFor) { return true; } } return false; }
3.3.2.2. 你总是可以接收到正数,如果你违反了这个规则,编译器会检查它,但不会导致性能问题
3.3.2.3. 类型限制固定了正数需求,而不是改变算法,但根据数据的类型进行处理,还可以使运行速度更快
3.4. 数组排序了
3.4.1. 算法4
3.4.1.1. public static bool Contains(uint[] array, uint lookFor) {
int start = 0; int end = array.Length - 1; while (start <= end) { int middle = start + ((end - start) / 2);⇽--- 找到中间点,防止溢出 uint value = array[middle]; if (lookFor == value) { return true; } if (lookFor > value) { start = middle + 1; ⇽--- 消除给定范围的左半边 } else { end = middle - 1; ⇽--- 消除给定范围的右半边 } } return false; }
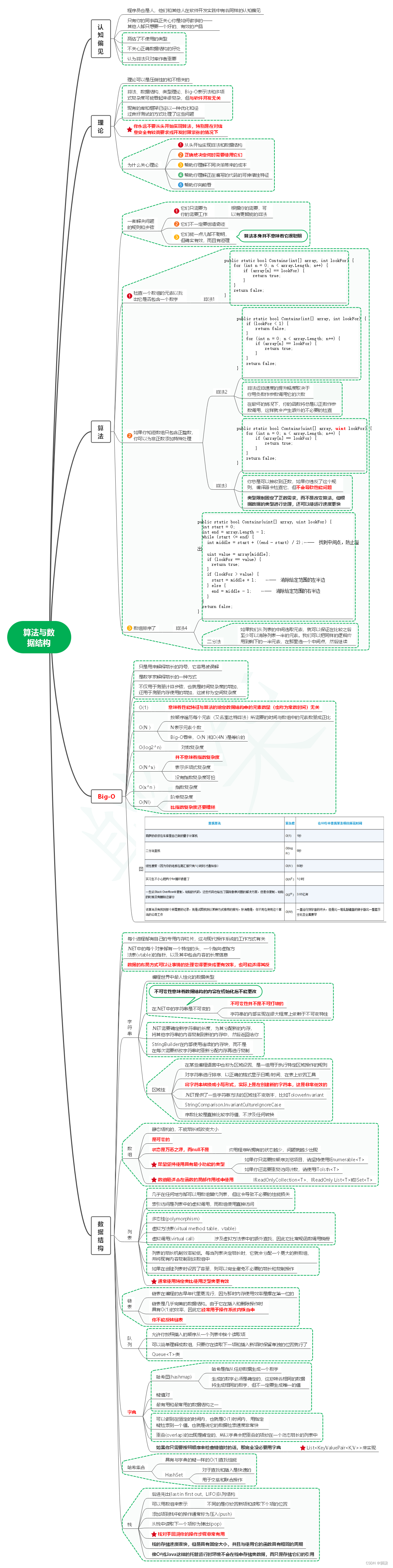
3.4.1.2. 二分法
3.4.1.2.1. 如果我们从列表的中间选取元素,就可以保证在比较之后至少可以消除列表一半的元素。我们可以把同样的逻辑应用到剩下的一半元素,在那里选一个中间点,然后继续
4. Big-O
4.1. 只是用来解释增长的符号,它容易被误解
4.2. 是数学家解释增长的一种方式
4.3. 不仅用于测量计算步骤,也就是时间复杂度的增加,还用于测量内存使用的增加,这被称为空间复杂度
4.4. O(1)
4.4.1. 意味着性能特征与算法的给定数据结构中的元素数量(也称为常数时间)无关
4.5. O(N )
4.5.1. 按顺序遍历每个元素(又名塞达特算法)所需要的时间与数组中的元素数量成正比
4.5.2. N表示元素个数
4.5.3. Big-O看来,O(N )和O(4N )是等价的
4.6. O(log2^n)
4.6.1. 对数复杂度
4.7. O(N^x)
4.7.1. 并不意味着指数复杂度
4.7.2. 表示多项式复杂度
4.7.3. 没有指数复杂度可怕
4.8. O(x^n )
4.8.1. 指数复杂度
4.9. O(N!)
4.9.1. 阶乘复杂度
4.9.2. 比指数复杂度还要糟糕
4.10. 图
5. 数据结构
5.1. 每个进程都有自己的专用内存切片,这与现代操作系统的工作方式有关
5.2. .NET中的每个对象都有一个特定的头、一个指向虚指方法表(vtable)的指针,以及其中包含内容的长度信息
5.3. 数据的布局方式可以让事情的处理变得更快或更有效率,也可能适得其反
5.4. 字符串
5.4.1. 编程世界中最人性化的数据类型
5.4.2. 在.NET中的字符串是不可变的
5.4.2.1. 不可变性意味着数据结构的内容在初始化后不能更改
5.4.2.2. 不可变性并不是不可打破的
5.4.2.3. 字符串的内部实现在很大程度上依赖于不可变特性
5.4.3. .NET需要确定新字符串的长度,为其分配新的内存,将其他字符串的内容复制到新的内存中,然后返回给你
5.4.4. StringBuilder在内部使用连续的内存块,而不是在每次需要修改字符串时重新分配内存再进行复制
5.4.5. 区域性
5.4.5.1. 在某些编程语言中也称为区域设置,是一组用于执行特定区域操作的规则
5.4.5.2. 对字符串进行排序、以正确的格式显示日期/时间、在表上放置工具
5.4.5.3. 将字符串转换成小写形式,实际上是在创建新的字符串,这是非常低效的
5.4.5.4. .NET提供了一些字符串方法的区域性不变版本,比如TolowerInvariant
5.4.5.5. StringComparison.InvariantCultureIgnoreCase
5.4.5.6. 序数比较是直接比较字符值,不涉及任何转换
5.5. 数组
5.5.1. 静态结构的,不能增长或改变大小
5.5.2. 是可变的
5.5.3. 状态是万恶之源,而null不是
5.5.3.1. 应用程序所拥有的状态越少,问题就越少出现
5.5.4. 尽量坚持使用具有最小功能的类型
5.5.4.1. 如果你只需要按顺序浏览项目,请坚持使用IEnumerable<T>
5.5.4.2. 如果你还需要重复访问计数,请使用ITolsth<T>
5.5.5. 数组最适合在函数的局部作用域中使用
5.5.5.1. IReadOnlyCollection<T>、IReadOnly List<T>或ISet<T>
5.6. 列表
5.6.1. 几乎在任何地方都可以用数组替代列表,但这会导致不必要的性能损失
5.6.2. 索引访问是列表中的虚拟调用,而数组使用直接访问
5.6.3. 多态性(polymorphism)
5.6.4. 虚拟方法表(vitual method table,vtable)
5.6.5. 虚拟调用(virtual call)
5.6.5.1. 涉及虚拟方法表中的额外查找,因此它比常规函数调用稍慢
5.6.6. 列表的增长机制效率较低。每当列表决定增长时,它就会分配一个更大的新数组,并将现有内容复制到该数组中
5.6.7. 如果在创建列表时设置了容量,则可以完全避免不必要的增长和复制操作
5.6.8. 通常使用特定类比使用泛型类更有效
5.7. 链表
5.7.1. 链表在编程的古早年代里更流行,因为那时内存使用效率是摆在第一位的
5.7.2. 链表是几乎完美的数据结构。由于它在插入和删除操作时具有O(1)的效率,因此它经常用于操作系统内核当中
5.7.3. 你不能反转链表
5.8. 队列
5.8.1. 允许你按照插入的顺序从一个列表中挨个读取项
5.8.2. 可以简单理解成数组,只要你在读取下一项和插入新项时保留单独的位置就行了
5.8.3. Queue<T>类
5.9. 字典
5.9.1. 哈希图(hashmap)
5.9.1.1. 哈希是指从任意数据生成一个数字
5.9.1.2. 生成的数字必须是确定的,这意味着相同的数据将生成相同的数字,但不一定要生成唯一的值
5.9.2. 键值对
5.9.3. 最有用和最常用的数据结构之一
5.9.4. 可以做到在恒定的时间内,也就是O(1)时间内,用指定键检索到一个值。也就是说它的数据检索速度非常快
5.9.5. 重叠(overlap)的出现是肯定的,所以字典会把重叠的项放在一个动态增长的列表中
5.9.6. 如果你只需要按照顺序来检查键值对的话,那完全没必要用字典
5.9.6.1. List<KeyValuePair<K,V>>来实现
5.10. 哈希集合
5.10.1. 具有与字典的键一样的O(1)查找性能
5.10.2. HashSet
5.10.2.1. 对于查找和插入是快速的
5.10.2.2. 用于交集和联合操作
5.11. 栈
5.11.1. 后进先出(last in first out,LIFO)队列结构
5.11.2. 可以用数组来表示
5.11.2.1. 不同的是你放置新项和读取下个项的位置
5.11.3. 添加项到栈中的操作通常称为压入(push)
5.11.4. 从栈中读取下一个项称为弹出(pop)
5.11.5. 栈对于回溯你的操作步骤非常有用
5.11.6. 栈的存储速度很快,但是具有固定大小,并且与使用它的函数具有相同的周期
5.11.7. 像C#或Java这样的托管运行时环境不会在栈中存储类数据,而只是存储它们的引用
这篇关于读程序员的制胜技笔记02_算法与数据结构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








