本文主要是介绍细致入微的理解ROS中的入门级别之手写数字识别在ROS领域的研究,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一种东西只要懂得他是如何工作的,原理是什么,那么与之类似的东西我们都可以一通百通,就比如手写数字识别被称为进入机器学习的hello world,那么我想如果我们要想学习其他的项目的话,我们只要深刻理解了其基本内涵,我想对于机器学习之路就会得心应手的。
下面来看一个完整的在ROS里边运用Tensorflow来实现手写数字的识别:
#!/usr/bin/env python
# -*- coding: utf-8 -*-import rospy
from sensor_msgs.msg import Image
from std_msgs.msg import Int16
from cv_bridge import CvBridge
import cv2
import numpy as np
import input_data
import tensorflow as tfclass MNIST():def __init__(self):image_topic = rospy.get_param("~image_topic", "")self._cv_bridge = CvBridge()#MNIST数据输入 self.mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) self.x = tf.placeholder(tf.float32,[None, 784]) #图像输入向量 self.W = tf.Variable(tf.zeros([784,10])) #权重,初始化值为全零 self.b = tf.Variable(tf.zeros([10])) #偏置,初始化值为全零 #进行模型计算,y是预测,y_ 是实际 self.y = tf.nn.softmax(tf.matmul(self.x, self.W) + self.b) self.y_ = tf.placeholder("float", [None,10]) #计算交叉熵 self.cross_entropy = -tf.reduce_sum( self.y_*tf.log(self.y)) #接下来使用BP算法来进行微调,以0.01的学习速率 self.train_step = tf.train.GradientDescentOptimizer(0.01).minimize(self.cross_entropy) #上面设置好了模型,添加初始化创建变量的操作 self.init = tf.global_variables_initializer() #启动创建的模型,并初始化变量 self.sess = tf.Session() self.sess.run(self.init) #开始训练模型,循环训练1000次 for i in range(1000): #随机抓取训练数据中的100个批处理数据点 batch_xs, batch_ys = self.mnist.train.next_batch(100) self.sess.run(self.train_step, feed_dict={self.x:batch_xs, self.y_:batch_ys}) ''''' 进行模型评估 ''' #判断预测标签和实际标签是否匹配 correct_prediction = tf.equal(tf.argmax(self.y,1),tf.argmax(self.y_,1)) self.accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) #计算所学习到的模型在测试数据集上面的正确率 print( "The predict accuracy with test data set: \n")print( self.sess.run(self.accuracy, feed_dict={self.x:self.mnist.test.images, self.y_:self.mnist.test.labels}) ) self._sub = rospy.Subscriber(image_topic, Image, self.callback, queue_size=1)self._pub = rospy.Publisher('result', Int16, queue_size=1)def callback(self, image_msg):#预处理接收到的图像数据cv_image = self._cv_bridge.imgmsg_to_cv2(image_msg, "bgr8")cv_image_gray = cv2.cvtColor(cv_image, cv2.COLOR_RGB2GRAY)ret,cv_image_binary = cv2.threshold(cv_image_gray,128,255,cv2.THRESH_BINARY_INV)cv_image_28 = cv2.resize(cv_image_binary,(28,28))#转换输入数据shape,以便于用于网络中np_image = np.reshape(cv_image_28, (1, 784))predict_num = self.sess.run(self.y, feed_dict={self.x:np_image, self.y_:self.mnist.test.labels})#找到概率最大值answer = np.argmax(predict_num, 1)#发布识别结果rospy.loginfo('%d' % answer)self._pub.publish(answer)#rospy.sleep(1) def main(self):rospy.spin()if __name__ == '__main__':rospy.init_node('ros_tensorflow_mnist')tensor = MNIST()rospy.loginfo("ros_tensorflow_mnist has started.")tensor.main()
以上是完整的在ROS里边运用Tensorflow来实现手写数字的识别的代码。要总结就要总结的到位,让其他朋友们看懂,有收获,产生共鸣!虽然这个项目已经被很多大佬演示过,研究的滚瓜烂熟,但是对于像我这样的刚接触Tensorflow学习者来说,我今天这个总结应该算是一个空闲功夫拿出来消遣的文章。
下面这个就是最简单的在Tensorflow中的手写数字项目识别。
#!/usr/bin/env python3
# -*- coding: utf-8 -*- import input_data
import tensorflow as tf #MNIST数据输入
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) x = tf.placeholder(tf.float32,[None, 784]) #图像输入向量
W = tf.Variable(tf.zeros([784,10])) #权重,初始化值为全零
b = tf.Variable(tf.zeros([10])) #偏置,初始化值为全零 #进行模型计算,y是预测,y_ 是实际
y = tf.nn.softmax(tf.matmul(x,W) + b) y_ = tf.placeholder("float", [None,10]) #计算交叉熵
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
#接下来使用BP算法来进行微调,以0.01的学习速率
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy) #上面设置好了模型,添加初始化创建变量的操作
init = tf.global_variables_initializer()
#启动创建的模型,并初始化变量
sess = tf.Session()
sess.run(init) #开始训练模型,循环训练1000次
for i in range(1000): #随机抓取训练数据中的100个批处理数据点 batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict={x:batch_xs,y_:batch_ys}) ''''' 进行模型评估 '''
#判断预测标签和实际标签是否匹配
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
#计算所学习到的模型在测试数据集上面的正确率
print( sess.run(accuracy, feed_dict={x:mnist.test.images, y_:mnist.test.labels}) )
纵观以上两处完整代码,我们就可以发现他们的差异,第一个是运用即传承了ROS的技术,有话题,有发布,有接受,现在我来逐一解释代码含义:
第一条
class MNIST():def __init__(self):image_topic = rospy.get_param("~image_topic", "") rospy.loginfo('-----------------------------------')rospy.loginfo(image_topic)rospy.loginfo('---------------++------------------')#/usb_cam/image_rawself._cv_bridge = CvBridge()#类的实例化
这里呢,我们用Python语法写了一个名字叫做MNIST的类,在这里边的def init(self): 如果没有在__init__中初始化对应的实例变量的话,导致后续引用实例变量会出错,实现类本身相关内容的初始化。当一个Class,稍微复杂一点的时候,或者内部函数需要用得到的时候,往往都需要在,别人实例化你这个类之前,使用你这个类之前,做一些基本的,与自己的类有关的,初始化方面的工作。而这部分工作,往往就放到__init__函数中去了。换句话说,你要用人家的类(中的变量和函数)之前,总要给人家一个机会,做点准备工作,然后才能为你服务吧,我想也就是这个意思。
好了,我们继续往下看,
image_topic = rospy.get_param("~image_topic", “”) 获取私有命名空间参数

在终端输入:rosrun rqt_graph rqt_graph,我们就可以得到这幅图。
从这幅图我们可以得到,当我们在工作区间输入rosrun rqt_graph rqt_graph后得到上述png图片(不知道什么是工作区间的童鞋可以看看我以前写的关于ROS入门的文章,里边讲述了如何去创建工作区间,初始化,编译,然后牵引我们的环境变量),当这些工作已经做好了之后我们就可以进行下一步,有的人会想为什么我们在这里要来存储命名空间呢?
[可以看看这里:]
(https://www.cnblogs.com/qixianyu/p/6576075.html)
第二条
#MNIST数据输入 self.mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) self.x = tf.placeholder(tf.float32,[None, 784]) #图像输入向量 self.W = tf.Variable(tf.zeros([784,10])) #权重,初始化值为全零 self.b = tf.Variable(tf.zeros([10])) #偏置,初始化值为全零 #进行模型计算,y是预测,y_ 是实际 self.y = tf.nn.softmax(tf.matmul(self.x, self.W) + self.b) self.y_ = tf.placeholder("float", [None,10])
在这一段代码之前有import input_data
self.mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
这句话意思就是我们应该先下载这个数据集,tensorflow提供一个input_data.py文件,专门用于下载mnist数据,我们直接调用(import input_data)就可以了,执行完成后,(程序会检验本地是否有相关文件,没有则会自动下载)会在当前目录下新建一个文件夹MNIST_data, 下载的数据将放入这个文件夹内。下载的四个文件为:
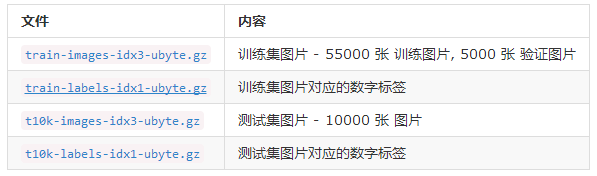
input_data文件会调用一个maybe_download函数,确保数据下载成功。这个函数还会判断数据是否已经下载,如果已经下载好了,就不再重复下载。下载下来的数据集被分三个子集:5.5W行的训练数据集(mnist.train),5千行的验证数据集(mnist.validation)和1W行的测试数据集(mnist.test)。因为每张图片为28x28的黑白图片,所以每行为784维的向量。
整体来说,使用TensorFLow编程主要分为两个阶段,第一个阶段是构建模型,把网络模型用代码搭建起来。TensorFlow的本质是数据流图,因此这一阶段其实是在规定数据的流动方向。第二个阶段是开始训练,把数据输入到模型中,并通过梯度下降等方法优化变量的值。
第三条详细分析程序
#!/usr/bin/env python
# -*- coding: utf-8 -*-import rospy
from sensor_msgs.msg import Image
from std_msgs.msg import Int16
from cv_bridge import CvBridge
import cv2
import numpy as np
import input_data
import tensorflow as tfclass MNIST():def __init__(self):image_topic = rospy.get_param("~image_topic", "") rospy.loginfo('-----------------------------------')rospy.loginfo(image_topic)rospy.loginfo('---------------++------------------')#/usb_cam/image_rawself._cv_bridge = CvBridge()#类的实例化#MNIST数据输入 self.mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) self.x = tf.placeholder(tf.float32,[None, 784]) #图像输入向量 self.W = tf.Variable(tf.zeros([784,10])) #权重,初始化值为全零 self.b = tf.Variable(tf.zeros([10])) #偏置,初始化值为全零 #进行模型计算,y是预测,y_ 是实际 self.y = tf.nn.softmax(tf.matmul(self.x, self.W) + self.b) self.y_ = tf.placeholder("float", [None,10]) #计算交叉熵 self.cross_entropy = -tf.reduce_sum( self.y_*tf.log(self.y)) #接下来使用BP算法来进行微调,以0.01的学习速率 self.train_step = tf.train.GradientDescentOptimizer(0.01).minimize(self.cross_entropy) #上面设置好了模型,添加初始化创建变量的操作 self.init = tf.global_variables_initializer() #启动创建的模型,并初始化变量 self.sess = tf.Session() self.sess.run(self.init) #开始训练模型,循环训练1000次 for i in range(1000): #随机抓取训练数据中的100个批处理数据点 batch_xs, batch_ys = self.mnist.train.next_batch(100) self.sess.run(self.train_step, feed_dict={self.x:batch_xs, self.y_:batch_ys}) ''''' 进行模型评估 ''' #判断预测标签和实际标签是否匹配 correct_prediction = tf.equal(tf.argmax(self.y,1),tf.argmax(self.y_,1)) self.accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) #计算所学习到的模型在测试数据集上面的正确率 #预测模型的准确率#0.9144print( "The predict accuracy with test data set: \n")print( self.sess.run(self.accuracy, feed_dict={self.x:self.mnist.test.images, self.y_:self.mnist.test.labels}) ) #订阅了Image主题,并定义回调函数callback。#self.callback函数是主要的处理函数,将摄像头捕捉到的图片,经过识别处理后发布为result主题self._sub = rospy.Subscriber(image_topic, Image, self.callback, queue_size=1) #定义发布的主题为result,#后续我们可以订阅result主题来显示识别结果self._pub = rospy.Publisher('result', Int16, queue_size=1)def callback(self, image_msg):#预处理接收到的图像数据#Convert the message to a new imagecv_image = self._cv_bridge.imgmsg_to_cv2(image_msg, "bgr8")#转化成灰度cv_image_gray = cv2.cvtColor(cv_image, cv2.COLOR_RGB2GRAY)#cv2.THRESH_BINARY_INV-->黑白二值反转#这个函数有四个参数,第一个原图像,第二个进行分类的阈值,第三个是高于(低于)阈值时赋予的新值<----#--->第四个是一个方法选择参数ret,cv_image_binary = cv2.threshold(cv_image_gray,128,255,cv2.THRESH_BINARY_INV)#把cv_image_binary形式的图片转化成长宽均为28的图片cv_image_28 = cv2.resize(cv_image_binary,(28,28))#转换输入数据shape,以便于用于网络中np_image = np.reshape(cv_image_28, (1, 784))predict_num = self.sess.run(self.y, feed_dict={self.x:np_image, self.y_:self.mnist.test.labels})#-----------------例如:-------------------# [[0. 0. 0. 0. 0. 0. 0. 0. 1. 0.]] -----> 8# [[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]] -----> 5rospy.loginfo('--------------------预测开始---------------------')rospy.loginfo(predict_num)rospy.loginfo('--------------------预测结束---------------------')#找到概率最大值#在以上列表中找出索引值answer = np.argmax(predict_num, 1)#发布识别结果#rospy.loginfo('索引的结果为:{}'.format(predict_num[0].index(1)))rospy.loginfo('识别的结果为:%d' % answer)#发布answerself._pub.publish(answer)rospy.sleep(1) def main(self):#rospy.spin()简单保持你的节点一直运行,直到程序关闭。rospy.spin()if __name__ == '__main__':rospy.init_node('ros_tensorflow_mnist')tensor = MNIST()rospy.loginfo("ros_tensorflow_mnist has started.") tensor.main()可以借鉴的博客:
https://www.jianshu.com/p/db2afc0b0334
https://blog.csdn.net/mwlwlm/article/details/75126670
今天就写到这里吧,一个一个打的字,懵懵懂懂,真心希望每一位看过这个文章的童鞋和我一起讨论一下,共同研究研究机器学习的奥秘,理解它的运作内涵,以及其他各种算法的奥秘,有何联系,随时在线等!
这篇关于细致入微的理解ROS中的入门级别之手写数字识别在ROS领域的研究的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






