本文主要是介绍postgres wal2json插件jsonb字段数据丢失问题解决,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
使用pg+wal2json+debezium进行数据同步时,发现偶尔会有jsonb字段数据丢失的问题
进行测试时发现:
1、发生数据丢失的jsonb字段长度都比较大(超过toast阈值,使用toast表存储)
2、针对发生jsonb字段丢失的数据,jsonb字段本身未发生修改时,能够百分百重现问题;而如果jsonb字段发生修改,就不会有问题
针对这个情况,分析是由于wal2json针对pg toast存储的处理导致
GitHub上找到相应的issue:https://github.com/eulerto/wal2json/issues/98
首先理解下什么是toast:
TOAST(The Oversized-Attribute Storage Technique)是一种机制,用于处理大数据对象(LOBs,Large Objects)或者超长字段的存储。当某个表中包含大量的大数据对象或超长字段时,这些数据可能会占据大量的存储空间,影响数据库性能。为了优化存储和处理性能,PostgreSQL 将大数据对象和超长字段称为 “TOAS Table” 数据,并将其存储在单独的 TOAST 表中。
而wal2json针对pg toast的存储做了"性能优化",如果发现toast字段未发生改变,就不输出这个字段。但是下游的debezium并不知道它做了这个优化,当然就无法进行处理了(debezium误识别为schema变更,把jsonb字段更新为null)
于是自己尝试修改wal2json代码,重新编译
修改方法很简单:搜索VARATT_IS_EXTERNAL_ONDISK关键字,把对应的代码逻辑注释掉

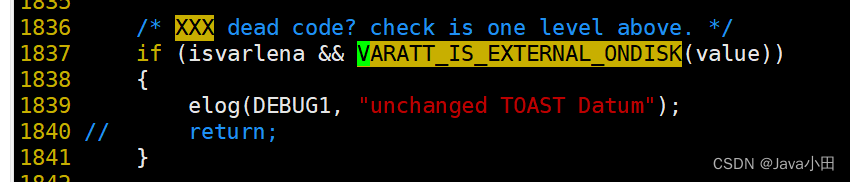

(其实这里看注释都能看出问题了)
修改之后重新编译(执行make命令即可),把新编译生成的wal2json.so文件,拷贝到pg的lib目录(我这里是/usr/pgsql-11/lib)
然后重新启动pg (systemctl start postgresql-11),问题解决
附带测试使用的命令:
创建slot:
pg_recvlogical -d postgres --slot test_slot --create-slot -P wal2json消费slot:
pg_recvlogical -d postgres --slot test_slot --start -o pretty-print=1 -o add-msg-prefixes=wal2json -f -删除slot:
pg_recvlogical -d postgres --slot test_slot --drop-slot
这篇关于postgres wal2json插件jsonb字段数据丢失问题解决的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






