本文主要是介绍如果看了此文还不懂 Word2Vec,那是我太笨,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转自http://www.sohu.com/a/128794834_211120
自从 Google 的 Tomas Mikolov 在《Efficient Estimation of Word Representation in Vector Space》提出 Word2Vec,就成为了深度学习在自然语言处理中的基础部件。Word2Vec 的基本思想是把自然语言中的每一个词,表示成一个统一意义统一维度的短向量。至于向量中的每个维度具体是什么意义,没人知道,也无需知道,也许对应于世界上的一些最基本的概念。但是,读论文去理解 Word2Vec 的模型生成,依然有些云里雾里,于是只好求助于读代码,然后就茅塞顿开,与大家分享。
任何一门语言,都是由一堆的词组成,所有的词,构成了一个词汇表。词汇表,可以用一个长长的向量来表示。词的个数,就是词汇表向量的维度。那么,任何一个词,都可以表示成一个向量,词在词汇表中出现的位置设为1,其它的位置设为0。但是这种词向量的表示,词和词之间没有交集,用处不大。
Word2Vec 的训练模型,看穿了,是具有一个隐含层的神经元网络(如下图)。它的输入是词汇表向量,当看到一个训练样本时,对于样本中的每一个词,就把相应的在词汇表中出现的位置的值置为1,否则置为0。它的输出也是词汇表向量,对于训练样本的标签中的每一个词,就把相应的在词汇表中出现的位置的值置为1,否则置为0。那么,对所有的样本,训练这个神经元网络。收敛之后,将从输入层到隐含层的那些权重,作为每一个词汇表中的词的向量。比如,第一个词的向量是(w1,1 w1,2 w1,3 ... w1,m),m是表示向量的维度。所有虚框中的权重就是所有词的向量的值。有了每个词的有限维度的向量,就可以用到其它的应用中,因为它们就像图像,有了有限维度的统一意义的输入。
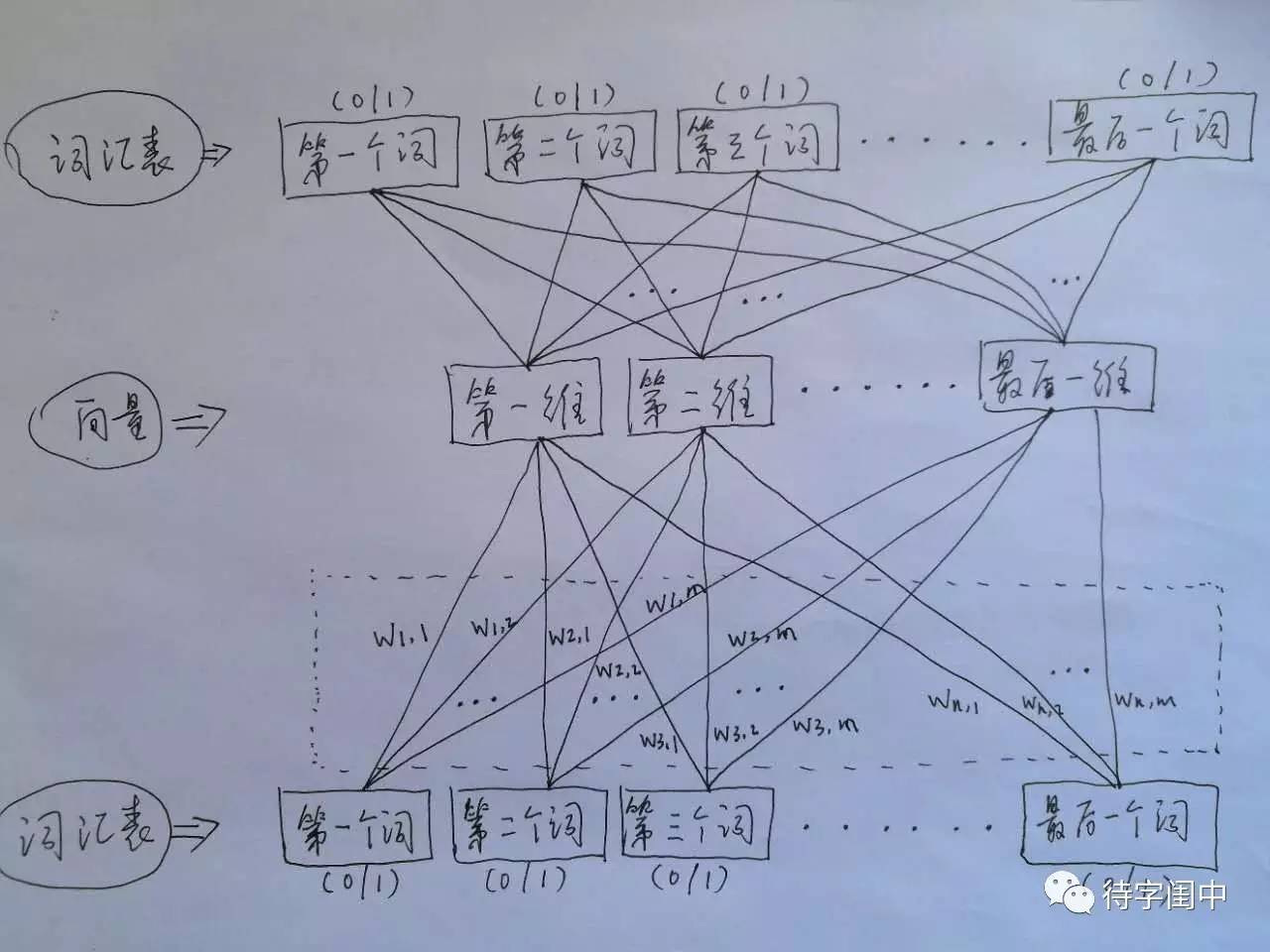
训练 Word2Vec 的思想,是利用一个词和它在文本中的上下文的词,这样就省去了人工去标注。论文中给出了 Word2Vec 的两种训练模型,CBOW (Continuous Bag-of-Words Model) 和 Skip-gram (Continuous Skip-gram Model)。
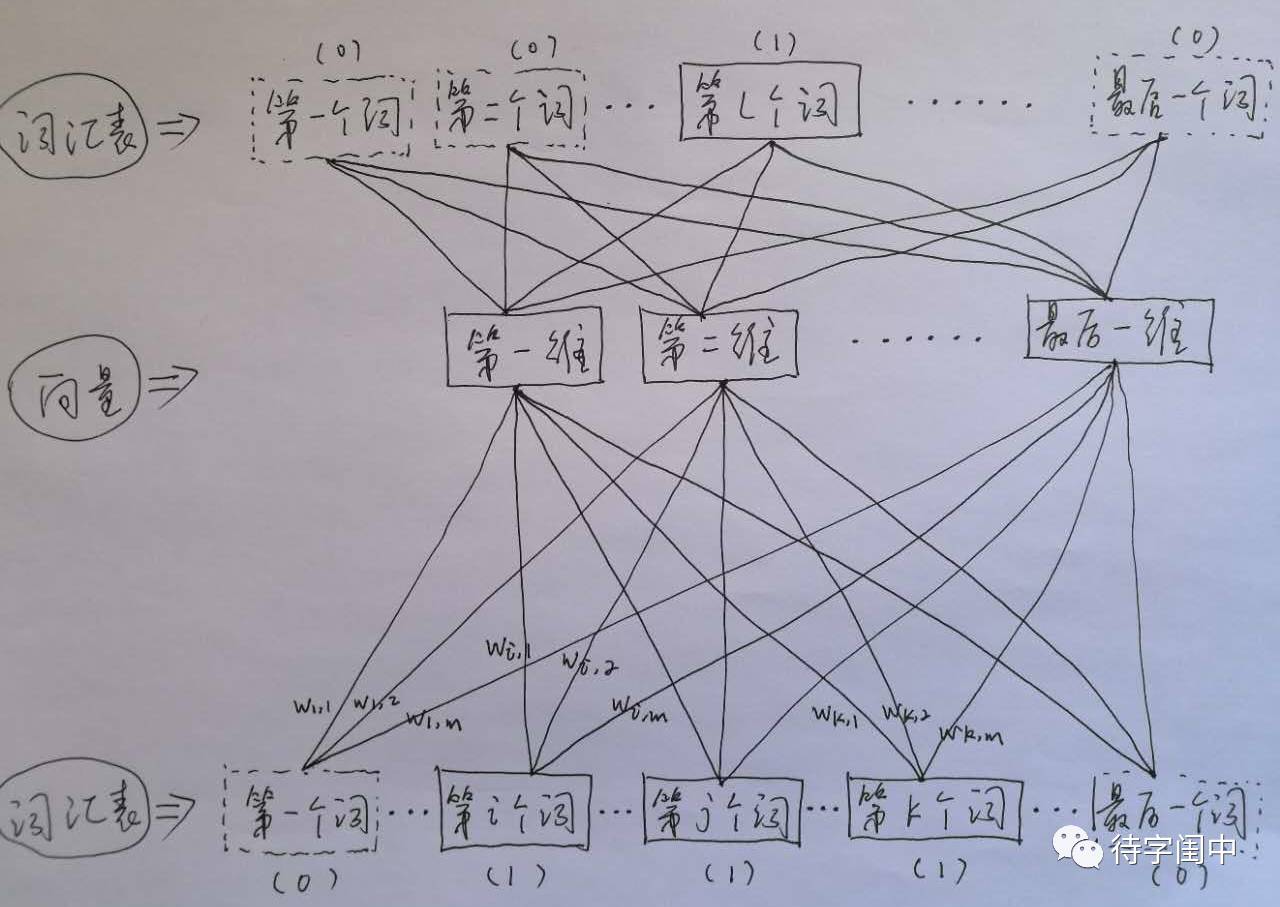
首先看CBOW,它的做法是,将一个词所在的上下文中的词作为输入,而那个词本身作为输出,也就是说,看到一个上下文,希望大概能猜出这个词和它的意思。通过在一个大的语料库训练,得到一个从输入层到隐含层的权重模型。如下图所示,第l个词的上下文词是i,j,k,那么i,j,k作为输入,它们所在的词汇表中的位置的值置为1。然后,输出是l,把它所在的词汇表中的位置的值置为1。训练完成后,就得到了每个词到隐含层的每个维度的权重,就是每个词的向量。
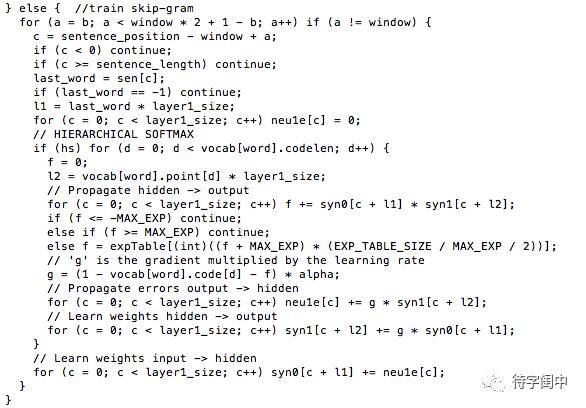
Word2Vec 代码库中关于CBOW训练的代码,其实就是神经元网路的标准反向传播算法。

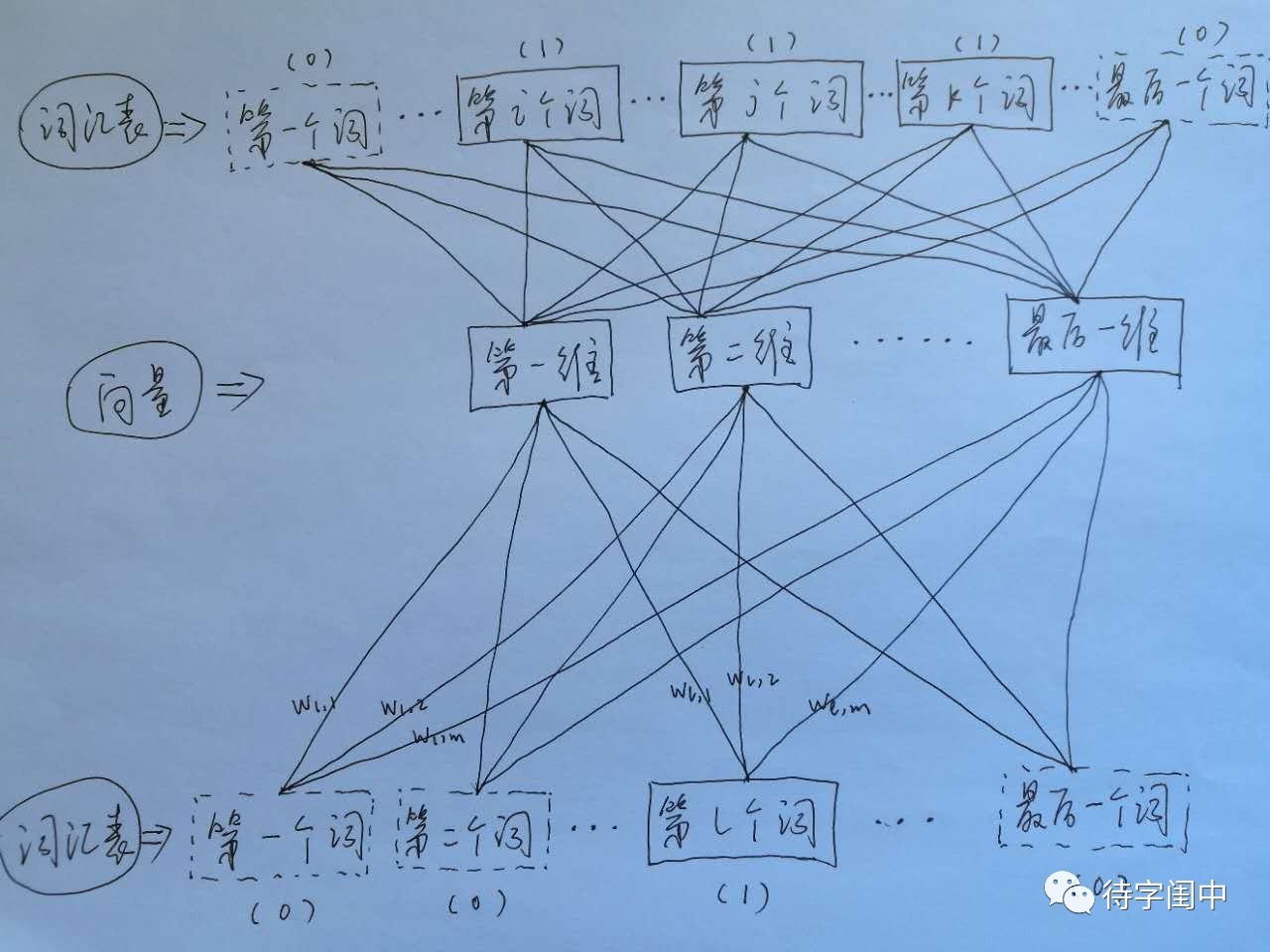
接着,看看Skip-gram,它的做法是,将一个词所在的上下文中的词作为输出,而那个词本身作为输入,也就是说,给出一个词,希望预测可能出现的上下文的词。通过在一个大的语料库训练,得到一个从输入层到隐含层的权重模型。如下图所示,第l个词的上下文词是i,j,k,那么i,j,k作为输出,它们所在的词汇表中的位置的值置为1。然后,输入是l,把它所在的词汇表中的位置的值置为1。训练完成后,就得到了每个词到隐含层的每个维度的权重,就是每个词的向量。
Word2Vec 代码库中关于Skip-gram训练的代码,其实就是神经元网路的标准反向传播算法。
一个人读书时,如果遇到了生僻的词,一般能根据上下文大概猜出生僻词的意思,而 Word2Vec 正是很好的捕捉了这种人类的行为,利用神经元网络模型,发现了自然语言处理的一颗原子弹。
这篇关于如果看了此文还不懂 Word2Vec,那是我太笨的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






