本文主要是介绍NVIDIA Tesla V100部署与使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在先前的实验过程中,使用了腾讯云提供的nvidia T4GPU,尽管其性能较博主的笔记本有了极大提升,但总感觉仍有些美中不足,因此本次博主租赁了nvidia V100 GPU,看看它的性能表现如何。
和先前一样,只需要将服务器使用xshell连接我们就可以使用了。我们首先看下其配置情况:
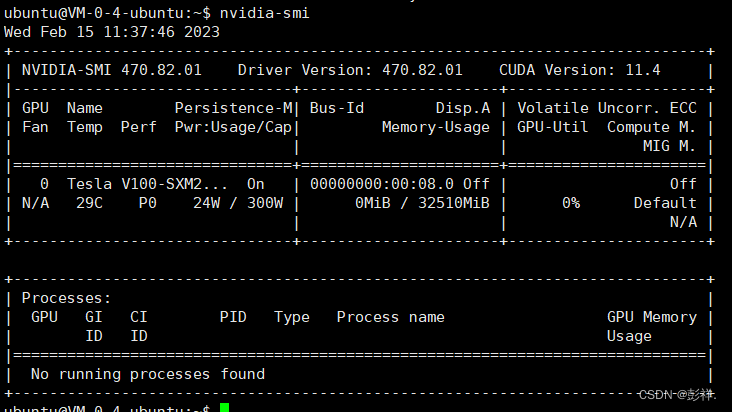
可以看到,其GPU显存达到了32G,先前博主查询V100的显存仅为16G的,这可当真是意外之喜。
然后便是老生常谈的环境部署过程了:
创建虚拟环境:
conda create -n yolo python=3.8
此时报错:
NoWritableEnvsDirError: No writeable envs directories configured.- /home/ubuntu/.conda/envs- /usr/local/miniconda3/envs
这是没有写入权限造成的,修改一下:
sudo chmod a+w .conda
或者执行下面命令,注意路径可能不同
sudo chmod -R 777 /home/ubuntu/miniconda3
再次创建环境:成功。随后激活yolo环境
source activate yolo
然后安装pytorch及其依赖
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
其他依赖包
pip install matplotlibpip install scipypip install tensorboardpip install tqdmpip install opencv-python当然这里可以一次性使用以下命令全部安装:pip install matplotlib,scipy,tensorboard,tqdm,opencv-python
随后我们使用pycharm连接服务器。
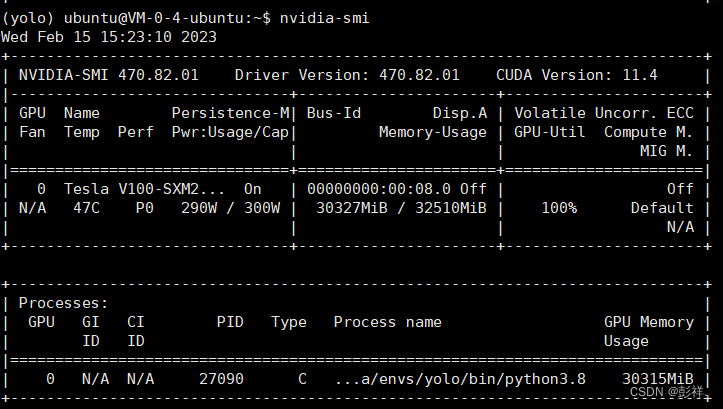
然后便可以开始训练了,设置batch-size=32,epoch为400,此时GPU使用情况如下:
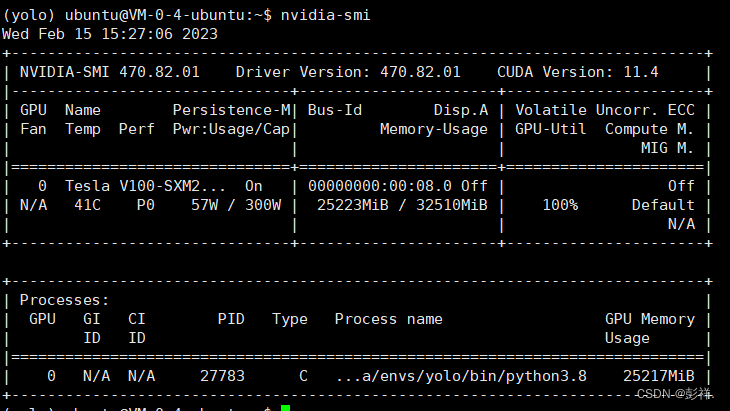
当我们将batch-size调整为48时,在训练过程中,其会保存一些数据,此时便存在显存溢出的风险了。
警告:
根据实验,将batch-size设置为32依旧会爆显存,因此将其设置为24,其实在监控中可以发现,GPU可能只是在一瞬间对显存需求较大,从而造成爆显存问题,如我们在训练完第一轮后保留一些梯度信息,模型信息时会对显存需求激增,从而出错。
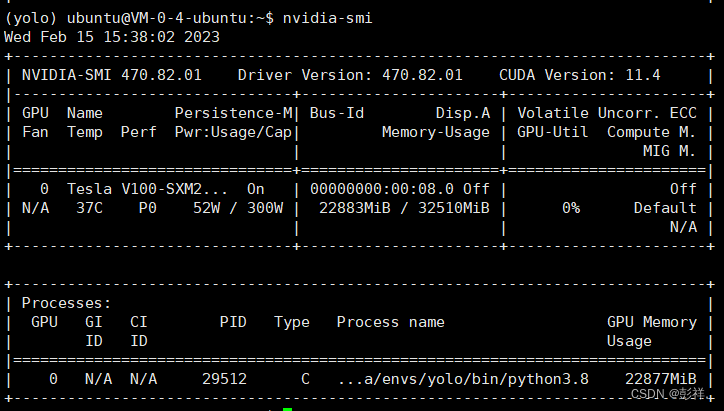
最终本次实验设置batch-size=24,epoch=400
实验环境:
GPU为 NVIDIA Tesla V100,显存32G
CPU为Intel® Xeon® Gold 6133 CPU @ 2.50GHz
下图是CPU配置信息,使用cat /proc/cpuinfo即可查询
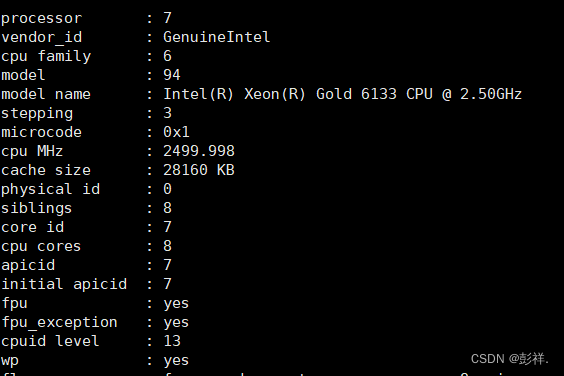
使用下面命令查询cpu信息,可知该服务器上由8个CPU,每个CPU有8个核心,每个核心为8线程。共8×8×8=512个线程
(yolo) ubuntu@VM-0-4-ubuntu:~$ grep 'processor' /proc/cpuinfo | wc -l
8
(yolo) ubuntu@VM-0-4-ubuntu:~$ grep 'physical id' /proc/cpuinfo
physical id : 0
physical id : 0
physical id : 0
physical id : 0
physical id : 0
physical id : 0
physical id : 0
physical id : 0
(yolo) ubuntu@VM-0-4-ubuntu:~$ grep 'core id' /proc/cpuinfo | sort -u |wc -l
8
(yolo) ubuntu@VM-0-4-ubuntu:~$ grep 'processor' /proc/cpuinfo | sort -u | wc -l
8
(yolo) ubuntu@VM-0-4-ubuntu:~$
历时28个小时,epoch=400,batch-size=24。
在本次运行完成后,竟然惊奇的发现较先前有了很大进步,而且在运行时也发现其loss依旧还有下降的趋势,因此决定在此基础上再次迭代200次并进行观测结果。
如此看来进行简单原因分析,首先说较先前训练轮数增加了,此外batch-size也增大了。可能便是此使其产生变化。
这篇关于NVIDIA Tesla V100部署与使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




