本文主要是介绍深入浅出讲解语音合成一:merlin、Gantts及其前端处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文字转语音(TTS)是一个给定文字输入,生成语音波形的系统。本系列文章将从传统的语音合成方法,到近期的端到端合成方案,各类型的声码器(个人认为比较有潜力的部分)进行讲解,作为近期实习结束后的工作总结。
语音合成过程分为前端的文本处理,中端的模型训练和后端的声码器合成过程。
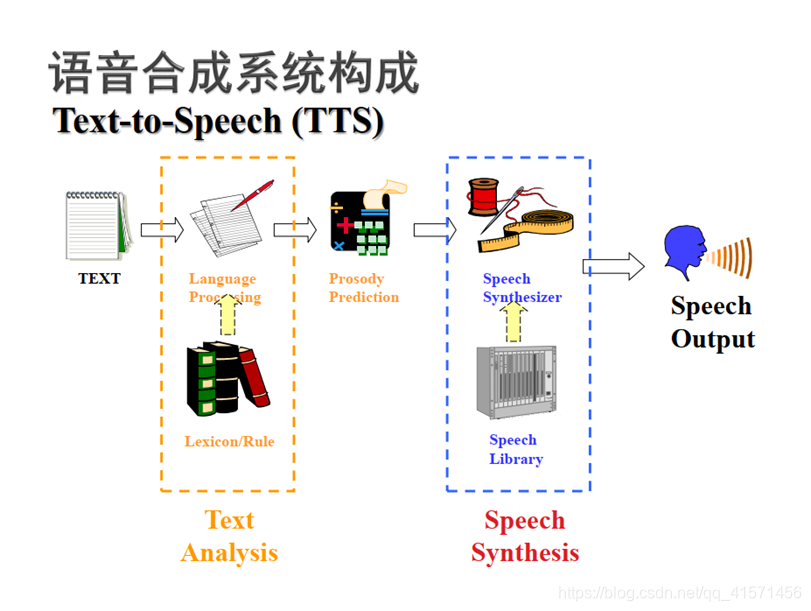
在传统语音合成方法中,前端处理的过程是非常麻烦的。首先,作为训练语料的文本需要转换为神经网络能够识别的数字特征,所以诞生了HTS样式的fullabel标注(又称为上下文相关标注),中文的语音合成可以借由开源的MTTS项目由文本和时间标注文件生成fulllabel。https://github.com/Jackiexiao/MTTS
fulllabel的问题集分为二值问题(QS)和实值问题(CQS),将fulllabel经过问题集提问后,产生二值特征(0,1)和实值特征(0-9之间)。问题集的三列字符分别表示问题序号(QS\CQS)、问题属性(如音素在字的位置等)、搜索问题的正则表达式。每一条fulllabel将遍历整个问题集一遍,并生成对应问题集个数的特征。其中,问题集个数是可变的,可以根据喜好自行删减和添加。
fulllabel格式(卡尔普陪外孙玩滑梯标注,你懂得)
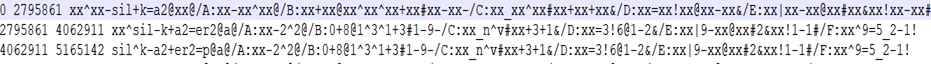
问题集格式

最后产生的特征将是一个矩阵,包含了对各类信息的描述性数据,具体内容可参看MTTS中的问题集设计规则。由于fulllabel中的特征条目是以音素为单位计算的,而一个音素在发音的不同时间段是有一定差别的,在后期使用问题集生成特征时,将对fullabel音素标注进行细化,以5ms为单位进行切分转换为状态级标注。下图中的424维特征将是音频除去静音段后,以5ms为单位划分出的特征个数(2.12/0.005=424).
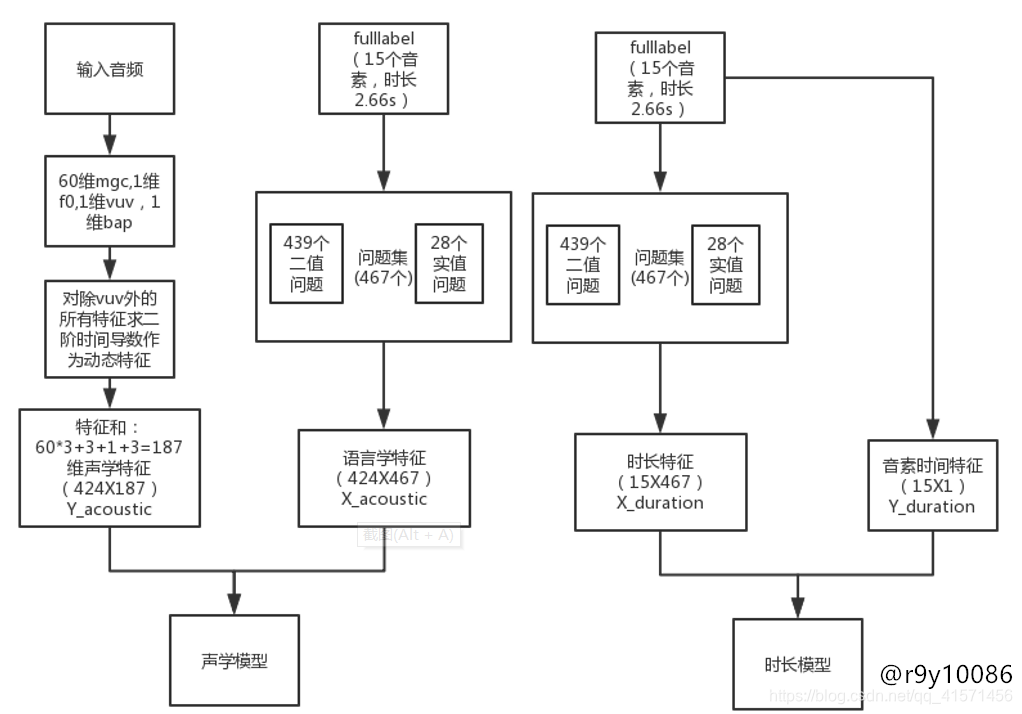
上图中使用的声码器为word,所以最左侧提取出的特征分别为mgc(梅尔谱)、f0(基音频率)、bap(非周期性,二次傅里叶变换并排序后的比值)、vuv(端点检测结果)。由于基音估计不准确(个人认为),合成的效果带有严重的合成音。最后,前端生成的特征矩阵将用于训练声学模型和时长模型,声学模型用于预测合成音频的特征,时长模型用于预测音素发音时长。
本文中,模型训练的方法将以merlin和gantts举例说明。其中,gantts训练过程中的model baseline即可等价为merlin,训练流程如下:
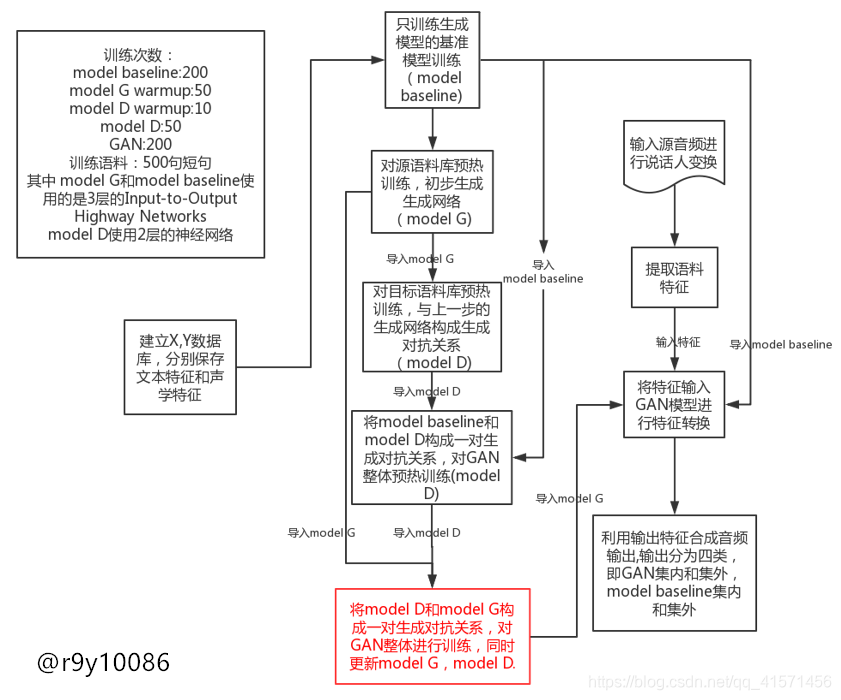
但遗憾的是,gantts采用了如此多的额外训练步骤,相比于merlin的音质合成提升极为有限。究其原因,个人认为是由以下两点限制了传统合成方案的合成性能:
1.采用HTS的fulllabel作为合成的文本特征,特征矩阵将由0-9之间的整型数据构成,冗余无用的特征过多,而对关键特征的描述信息过少(四五百个问题集中,生成的特征大多数为0)。
2.使用了传统的word声码器,虽然性能稳定,但合成音质不够自然。
这篇算是我的初次投稿,如果觉得写的不错,不妨给我点个赞吧,你的支持是我写作的最大动力。
各位大爷,别白嫖人家嘛~
这篇关于深入浅出讲解语音合成一:merlin、Gantts及其前端处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






