本文主要是介绍Visual Reinforcement Learning with Imagined Goals,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Visual Reinforcement Learning with Imagined Goals
文章来自 University of California, Berkeley,提出了一种将 goal-conditioned RL 与 无监督表示学习相结合的算法 — RIG (Reinforcement learning with Imagined Goals),该算法具有较高的样本效率,能够在真实世界中训练。

Contribution:
1)提出了一个新算法 RIG。
Code: https://github.com/vitchyr/rlkit
Env: https://github.com/vitchyr/multiworld
算法框架
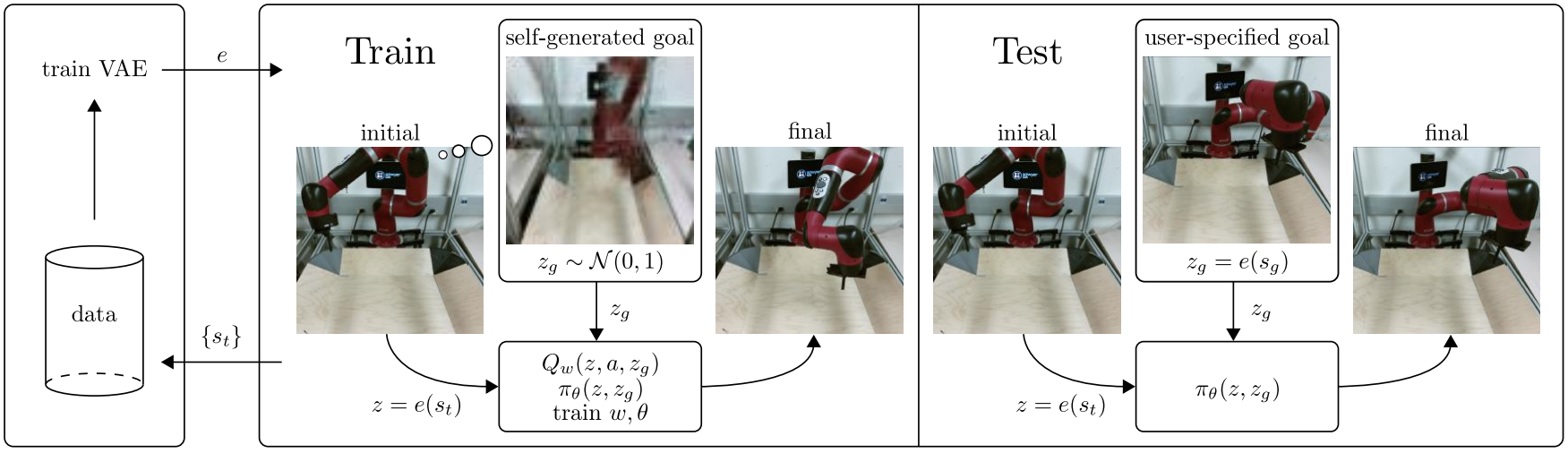
如图,框架分为三个部分,左边是 VAE 的训练,中间是 Agent 的训练,右边是 Agent 的测试。
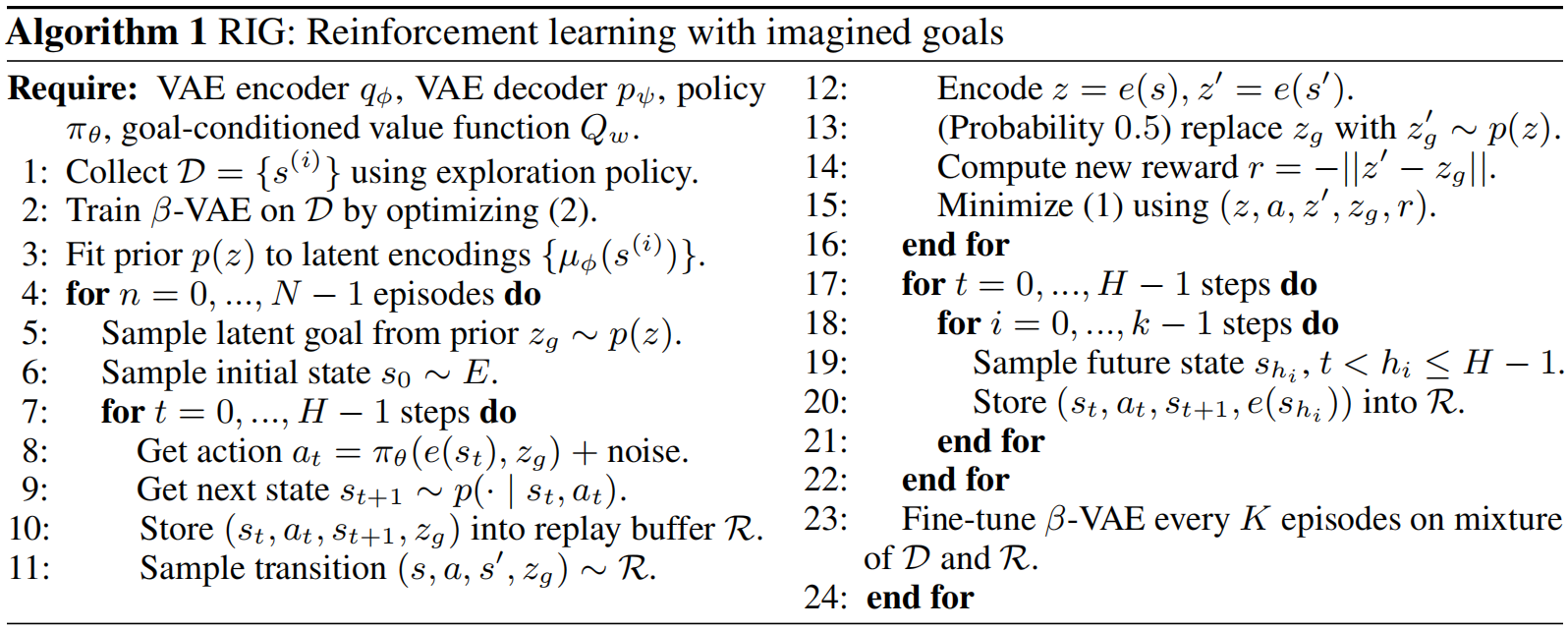
首先 看左边的 data,它只包含了状态 s s s ,这个可以在初始化之前用随机策略随便跑一下就能得到,然后将这些状态放入 VAE 进行训练,就可以得到状态的隐层表示 z = e ( s ) z = e(s) z=e(s)。训练 VAE 时,目标是最大化下式:
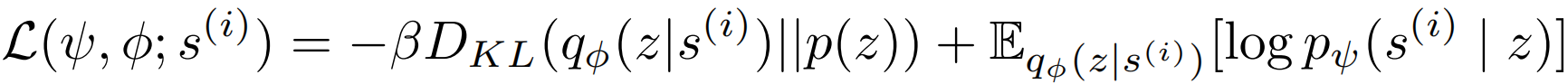
其中, β \beta β 是超参数,故这个也叫 β \beta β-VAE; 符号 q ϕ , p ψ , p ( z ) q_\phi, p_\psi,p(z) qϕ,pψ,p(z) 分别表示编码器,解码器和先验。
然后 开始训练 Agent:用 VAE 将观测到的状态 s t s_t st表示成 z = e ( s t ) z=e(s_t) z=e(st),然后从先验 p ( z ) p(z) p(z) 中采样一个目标 z g z_g zg,则 Agent 的目标就是学习如何从初始的 z z z 转到目标 z g z_g zg。在训练过程中, goal-conditioned RL 最小化下式 Bellman error(下式的 s , s ′ , g s,s',g s,s′,g 分别改为 z , z ′ , z g z,z',z_g z,z′,zg 才能对应本文):
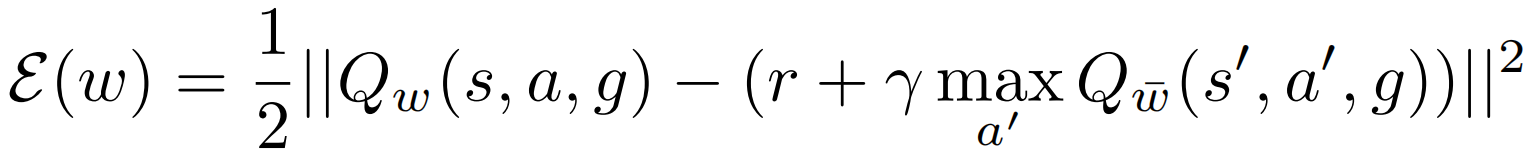
该式与一般的 RL bellman error 相比就是多了一个 goal 参数。然后再训练策略 π θ ( z , z g ) \pi_\theta(z,z_g) πθ(z,zg),论文中用的是 TD3 框架训练的。从策略和 Q-function 的形式 π θ ( z , z g ) , Q w ( z , a , z g ) \pi_\theta(z,z_g),Q_w(z,a,z_g) πθ(z,zg),Qw(z,a,zg) 来看,Agent 接触到的信息都是状态或目标的隐层表示 z , z g z,z_g z,zg,而不是直接接受状态和目标的原型 s , s g s,s_g s,sg。
最后 是测试阶段,训练 Agent 的时候,算法是自己产生 goal 的 (直接在先验中采样一个 z g z_g zg),而在测试的时候,是由用户指定 goal 的 (用户指定的是一张图片,所以标题是"Imagined Goals"),然后经过 VAE 表示成 z g = e ( s g ) z_g = e(s_g) zg=e(sg),再输入到策略网络中,执行训练好的策略,到达 goal 指定状态。
一些技巧
- 奖励函数的设定
我们知道 goal-conditioned RL 的目的是,让 agent 学会从某个状态 s s s 到达给定的目标状态 s g s_g sg。则将这两个状态 s s s 和 s g s_g sg 之间的距离作为奖励值,是一种合理的奖励设计方案。但由于本论文的状态是图像,而图像像素点的距离并不能很好地反应两个状态的距离 (人眼觉得基本没有区别的两个状态/两幅图,用像素点的距离计算的话,距离值依旧很大)。
因此,这里的方法是,先将状态 s s s 和目标 s g s_g sg 转成隐层表示 z , z g z,z_g z,zg,然后再计算他们之间的距离 (式中 A A A 为权重向量,不同的元素可以用不同的权重,但文中直接用单位阵 I I I):
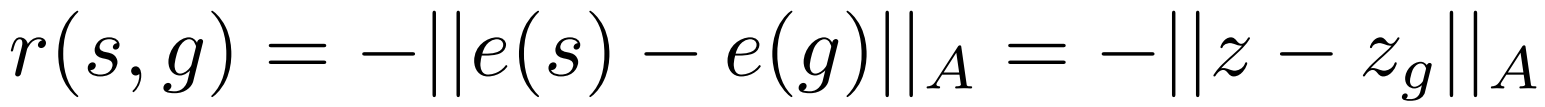
- 隐层目标 z g z_g zg 的重新设定
重新设定目标,本质上算是一种数据增强方法。即运用一定的方法,无需与环境互动,从现有的样本中再生成一些新的样本。所以,这个技巧能够提升样本效率。
例如,我们现有一个原始样本 ( s , a , s ′ , s g , r ) (s,a,s',s_g,r) (s,a,s′,sg,r) 经过 VAE 后得到隐层表示 ( z , a , z ′ , z g , r ) (z,a,z',z_g,r) (z,a,z′,zg,r),其中 ( s , a , s ′ ) (s,a,s') (s,a,s′) 是环境的属性决定的,隐含有环境的动态信息,所以其对应的隐层表示 ( z , a , z ′ ) (z,a,z') (z,a,z′) 也具有环境的动态信息,是不能更改的。因此,我们只能从目标 z g z_g zg 和奖励 r r r 上下手。
可以从先验 p ( z ) p(z) p(z) 中采样目标 z g z_g zg,然后再根据奖励的计算式计算对应的奖励 r r r。这样,只要我们从环境中采样得到一个样本的状态转移关系 ( z , a , z ′ ) (z,a,z') (z,a,z′),我们就能基于此生成任意多的样本 ( z , a , z ′ , z g 1 , r 1 ) (z,a,z',z_{g1},r_1) (z,a,z′,zg1,r1), ( z , a , z ′ , z g 2 , r 2 ) (z,a,z',z_{g2},r_2) (z,a,z′,zg2,r2),… , ( z , a , z ′ , z g n , r n ) (z,a,z',z_{gn},r_n) (z,a,z′,zgn,rn)。
附上伪代码
这篇关于Visual Reinforcement Learning with Imagined Goals的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





![[VC] Visual Studio中读写权限冲突](/front/images/it_default.jpg)

