本文主要是介绍Python爬虫-使用Scrapy框架爬取某网站热点新闻排行并保存数据库,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【背景】
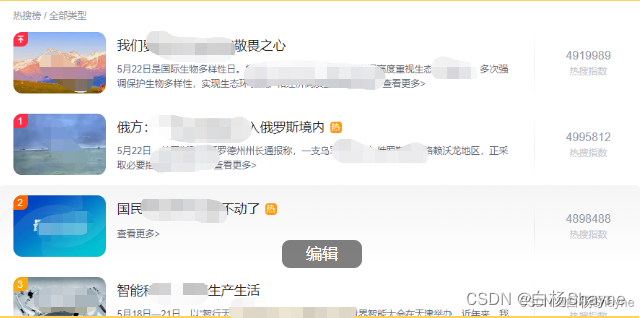
今天使用Scrapy来爬取某网站热点新闻,因可能的版权原因,里面的数据和网址都做了脱敏处理。
页面如下:
爬下来的数据如下所示:
数据分别是:序号、热点标题、热点内容、热点URL链接、热点排行、热度值
图片和数据对应不上的原因是,热点新闻的截图是我写博客的时候才截图的,数据是前几天爬取的。
在这之前我们先了解一下什么是Scrapy
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便
Scrapy 使用了 Twisted’twɪstɪd异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求
一、安装Scrapy
执行pip命令安装
pip install scrapy二、生成爬虫框架
执行以下命令
scrapy startproject baidu_spider生成的框架如下所示:
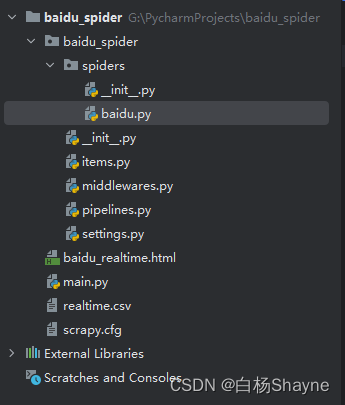
各文件功能分别是:
- scrapy.cfg:配置文件
- spiders:存放你Spider文件,也就是你爬取的py文件
- items.py:相当于一个容器,和字典较像
- middlewares.py:定义Downloader Middlewares(下载器中间件)和Spider Middlewares(蜘蛛中间件)的实现
- pipelines.py:定义Item Pipeline的实现,实现数据的清洗,储存,验证。
- settings.py:全局配置
三、生成爬虫
scrapy genspider baidu baidu.com结果如下

四、补全代码
在settings.py中增加如下配置项
ITEM_PIPELINES = {"baidu_spider.pipelines.BaiduSpiderPipeline": 300,"baidu_spider.pipelines.BaiduSpiderPrintPipeline": 200
}MYSQL_HOST='localhost'
MYSQL_USER='xxxx'
MYSQL_PWD='xxxx'
MYSQL_DB='xxxx'
MYSQL_CHARSET='utf8'pipelines对应的是两个解析后的网页数据输出管道,后面有交代
baidu.py中的代码补全后如下:
import scrapy
from baidu_spider.items import BaiduSpiderItemclass BaiduSpider(scrapy.Spider):name = "baidu"allowed_domains = ["www.baidu.com"]start_urls = ["https://top.xxxx.com/board?tab=realtime"]def parse(self, response):filename = "baidu_realtime.html"# open(filename, 'wb+').write(response.body)items = []for each in response.xpath('//*[@id="sanRoot"]/main/div[2]/div/div[2]/div'):item = BaiduSpiderItem()title = each.xpath('div[2]/a/div[1]/text()').extract()content = each.xpath('(div[2]/div[1]/text())[1]').extract()url = each.xpath('div[2]/a/@href').extract()hot = each.xpath('div[1]/div[2]/text()').extract()rank = each.xpath('a/div[1]/text()').extract()# print("title::::::::$title")# print("content::::::::$content")# print("url::::::::$url")# print("rank::::::::$rank")item['title'] = titleitem['content'] = contentitem['url'] = urlitem['rank'] = rankitem['hot'] = hotyield item# items.append(item)# return items
其中start_urls就是要爬取的网页
parse(self, response)函数就是对网页内容进行解析
items.py补全后的代码如下:
import scrapyclass BaiduSpiderItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# passtitle = scrapy.Field()url = scrapy.Field()content = scrapy.Field()rank = scrapy.Field()hot = scrapy.Field()这里定义了热点新闻解析后,需要获取的指标
管道pipelines.py中的代码如下:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interfacefrom itemadapter import ItemAdapter
import pymysql
from baidu_spider.settings import *class BaiduSpiderPrintPipeline:def process_item(self, item, spider):print(item['title'],item['content'],item['url'],item['rank'],item['hot'])return itemclass BaiduSpiderPipeline:def open_spider(self, spider):self.db = pymysql.connect(host=MYSQL_HOST,user=MYSQL_USER,password=MYSQL_PWD,database=MYSQL_DB,charset=MYSQL_CHARSET)self.cursor = self.db.cursor()def process_item(self, item, spider):insert_sql = "insert into spider_baidu_news(title, content, url, rank, hot) values (%s, %s, %s, %s, %s)"insert_parms = [item['title'],item['content'],item['url'],item['rank'],item['hot']]self.cursor.execute(insert_sql, insert_parms)self.db.commit()return itemdef close_spider(self, spider):self.cursor.close()self.db.close()print('执行了close_spider方法,项目已经关闭')
主要是定义了两个输出管道类,BaiduSpiderPrintPipeline和BaiduSpiderPipeline
每个管道里面可以重写以下三个方法:
- def open_spider(self, spider): 处理数据前执行,只执行一次,用于连接数据库之类的操作,避免每次写数据之前都要连接数据库;
- def process_item(self, item, spider): 处理数据,没条数据都会调用一次;
- def close_spider(self, spider): 处理数据后执行,只执行一次,用于释放数据库连接、关闭文件之类的操作;
五、运行代码
运行命令如下
scrapy crawl baidu -o realtime.csv-o:是把管道数据输出到文件
也可以在工程跟目录下生成一个main.py,免的每次在命令行执行
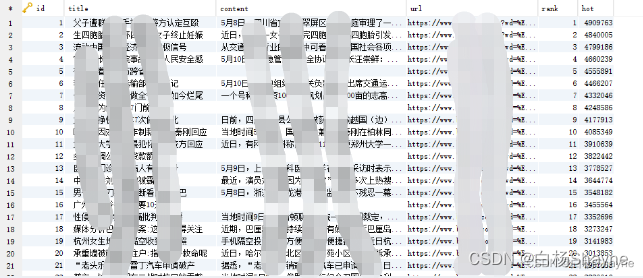
from scrapy import cmdlinecmdline.execute('scrapy crawl baidu -o realtime.csv'.split())执行后数据库中已经可以看到数据:
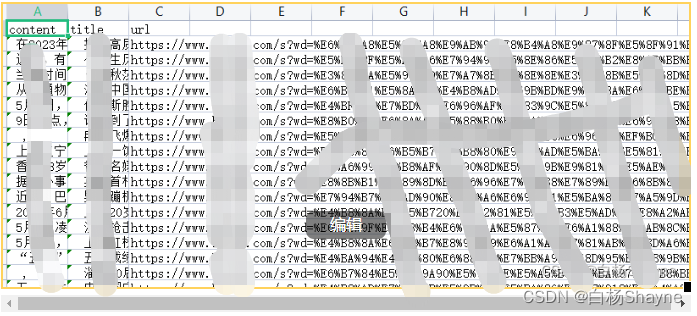
csv文件中数据如下:
五、总结
可以看到,整个代码框架还是非常简洁清晰的,很多Python初学者,都是把所有的逻辑写在一个文件里面,这样会导致代码非常凌乱,找起代码来非常困难,有了Scrapy后,就没有这个烦恼了,Scrapy已经把整个框架规划好了,我们只要补全业务代码就可以了。
这篇关于Python爬虫-使用Scrapy框架爬取某网站热点新闻排行并保存数据库的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


