本文主要是介绍老杨说运维 | 历时180天,跟复旦大学共研的运维大模型终于来了!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

写在前面
Q1:到处都在说的AI大模型到底是什么? ? ?
A1:AI大模型是“人工智能预训练大模型"的简称,它包含了"预训练“和”大模型“两层含义,二者结合产生了一种新的人工智能模式即模型在大规模数据集上完成了预训练后无需或仅需要少量数据的微调,就能直接支撑各类应用。
AI大模型具备通用、可规模化复制等诸多优势,是实现AGI(通用人工智能) 的重要方向。
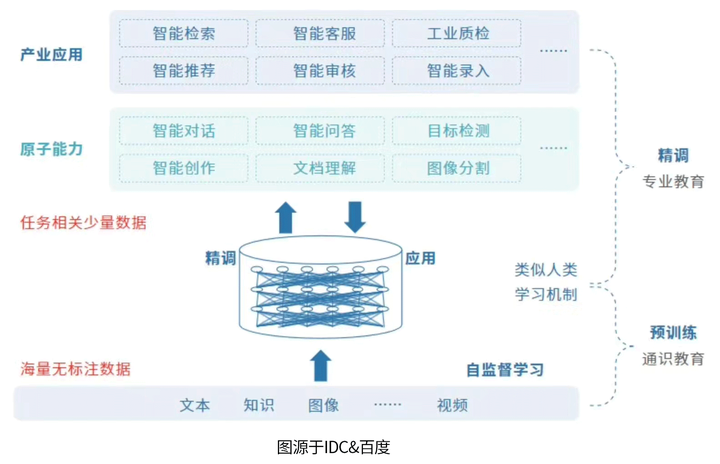
Q2:当前的AI大模型包含了哪些内容?
A2:当前AI大模型包含自然语言处理(NLP)、计算机视觉 (CV),多模态大模型等。
例如,ChatGPT就是自然语言处理领域突破性的创新,懂“人话”,说“人话”。超越了以往的自然语言处理模型,可以应对各种自然语言处理任务,包括机器翻译、问答、文本生成等。
简单来看,我们可以将大模型看作一个巨大的知识库,里面存储了大量的信息和知识,可以帮助计算机更好地理解和处理输入的数据。大模型中的每个神经元和参数,共同构成了一个强大的网络,可以对输入的数据,进行高效的处理和转换。

一、大模型与AIOps结合
伴随2023第六届双态IT乌镇用户大会的圆满完成,擎创科技“一体化数智管理和大模型应用”主题研讨会也正式落下了帷幕。
云原生转型正成为很多行业未来发展战略,伴随国家对信创数字化要求的深入推进,面对敏稳共存这一近年出现的新难题,企业IT运维的建设升级迎来了更为综合性的挑战。
大模型与AIOps结合究竟有什么能力?如何能更好的在实际中进行应用?——复旦大学计算机学院教授 & 擎创科技首席数据家 王鹏与您分享大模型在智能运维中的实践探索经验。

复旦大学计算机学院教授 & 擎创科技首席数据家 王鹏
二、大语言模型与运维相关的能力
经过近一年的不断探索,我们认为目前的大语言模型能够通过六点来有效帮助智能运维提升相关能力。未来若能够更好地将二者融合,或许将实现真正的运维数智化。
这些能力包括:
-
自然语言处理能力
-
运维领域知识
-
持续学习和改进能力
-
推理能力
-
自然语言生成能力
-
代码能力
三、运维大模型的原则
大模型的能力虽然看似很强,但实际上如果想要在智能运维的私域范围内得到很好地应用仍有很多困难。诸如:缺乏特定的告警知识、无法深入分析告警之间的关联性、问答过程有长度限制、模型回答不稳定等。
想要更好地使二者结合,我们认为要保证以下四点原则:
1.本地化部署
本地化部署能够保证私域数据安全,同时利用开源大模型对私域大模型进行训练和微调
2.集成现有工具
使LLM与现有的算法、工具、知识库链接,形成一体化管控;
3.不能为了LLM而LLM
以优先提升运维效率为主,尽量补足现有运维方法的不足,解决现有运维过程中的痛点;
4.充分发挥LLM的长处
即语言生成能力、对话能力和一定的推理能力。
四、擎智运维大模型
在本次双态乌镇大会上,擎创正式发布了自己的运维大模型产品——擎智运维大模型。
该模型通过对开源大模型的参数进行微调,结合私域数据构建企业的运维知识库,再通过检索增强等方式,丰富大模型的运维知识,结合大模型的语言生成能力,使得大模型能更好地理解日志/告警/事件等。
1.擎智大模型能力
-
在日志、告警解析时不再需要设置固定参数并能快速解析单条日志
-
提升日志、告警的可读性并自动生成处理方案
-
为日志、告警、事件等提供灵活的多类型数据探查能力
-
在面对告警风暴时快速准确地数据探查和根因定位
-
自动化、智能化地自动生成故障报告,有效辅助历史复盘
-
其他更多
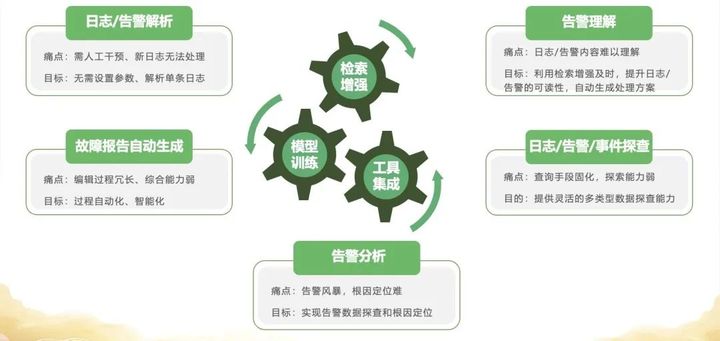
举例:基于知识增强的告警理解
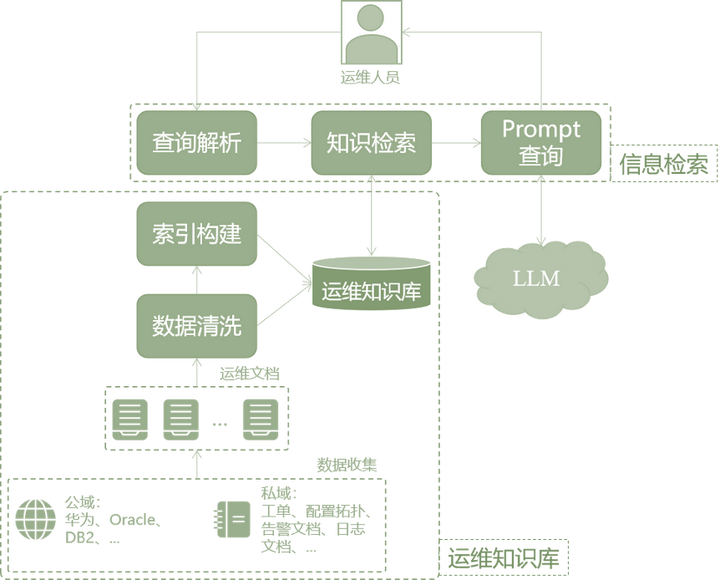
为了应对多样的运维需求,基于各类公域与私域的运维知识库大模型的检索增强是一种符合运维实际的方法。
![]()
(后续实践内容在此不加叙述,请点击视频进行了解~)
运维大模型实践分享

擎创科技,Gartner连续推荐的AIOps领域标杆供应商。公司专注于通过提升企业客户对运维数据的洞见能力,为运维降本增效,充分体现科技运维对业务运营的影响力。
行业龙头客户的共同选择

了解更多运维干货与行业前沿动态
可以右上角一键关注
我们是深耕智能运维领域近十年的
连续多年获Gartner推荐的AIOps标杆供应商
下期我们不见不散~
这篇关于老杨说运维 | 历时180天,跟复旦大学共研的运维大模型终于来了!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







