本文主要是介绍数据挖掘系列笔记(1)——亲和性分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
亲和性分析是根据样本个体(物体)之间的相似度,确定它们关系的亲疏。在数据挖掘中有大量的应用场景,比如顾客更愿意同时购买哪些物品。
亲和性有多种测量方法。例如,统计两件商品一起出售的频率,或者统计顾客购买了商品1 后再买商品2的比率。最常用的用来进行亲和性分析的两个重要概念是:支持度(support)和置信度(confidence)。举个例子:我们说在全班同学的样本中间,地理90分以上的同学历史也考90以上,那么他的支持度就是所有两门90分的人在样本中的占比,而置信度就是在地理90分的样本中,历史90分的人的占比。
接下来是一个利用计算支持度和置信度实现规则判断的一个例子(来自书籍《Python数据挖掘入门与实践》):商品推荐,任务目标,发现超市顾客对于商品购买的连带情况,找出更愿意一起购买的货物,然后重新布置货架。为了简化代码,方便讲解,我们只考虑一次购买两种商品的情况。例如,人们去超市既买了 面包,又买了牛奶。作为数据挖据入门性质的例子,我们希望得到下面这样的规则:如果一个人买了商品X,那么他很有可能购买商品Y。
数据的矩阵话计算需要库:NumPy,NumPy是Python中处理二位数据最常用的依赖方法,后边还有更多的使用。可以吧NumPy理解为一个矩阵控制器的对象,导入之后就直接创建了这个manager的Object
import numpy as np
dataset_filename = "affinity_dataset.txt"
X = np.loadtxt(dataset_filename) 这样就得到了相关性分析数据库的数组实体。(数组来自随书材料,是[N:5]的二维数组,数据为0或者1,每行表示每个顾客当次购物是否购买5类产品)。因此我们挖掘目标就是,找到支持度性和置信度最高的顾客愿意一起购买的物品的规则。

我们可以通过统计每个事件发生的频率作为计算的基础,比如:所有购买苹果的顾客的数量:

因此对于某个样本的支持度计算即为:

可以通过循环一次性计算所有的规则的发生次数和应验次数:
发生次数记为Occurance,应验记为Valid,为了方便统计,不应验记为invalid:
from collections import defaultdictvalid_rules = defaultdict(int)
invalid_rules = defaultdict(int)
num_occurances = defaultdict(int) for sample in X:for premise in range(4):if sample[premise] == 0:continueelse:num_occurances[premise] += 1for conclusion in range(4):if premise == conclusion:continueelse:if sample[conclusion] == 1:valid_rules[(premise, conclusion)] += 1else:invalid_rules[(premise, conclusion)] += 1 support = valid_rules
confidence = defaultdict(float)
for premise, conclusion in valid_rules.keys():rule = (premise, conclusion)confidence[rule] = valid_rules[rule] / num_occurances[premise]这里的原理就是:遍历X中的每一个样本,然后针对每个样本再做2层遍历,把所有发生的可能性找一遍,记录每个场景发生的次数(支持度)以及应验的次数(即购买了A的样本中购买B的数量,置信度)
接下来构建打印函数从数据中获取结果:
from operator import itemgetter #类似迭代器的东西
features = ["bread", "milk", "cheese", "apples", "bananas"] #商品字典#规则排序
sorted_support = sorted(support.items(), key=itemgetter(1), reverse=True)
sorted_confidence = sorted(confidence.items(), key = itemgetter(1), reverse = True)#打印规则表的规则(通过依赖的商品id)
def print_rule(premise, conclusion, support, confidence, features):premise_name = features[premise]conclusion_name = features[conclusion]print("Rule: if a person buys {0} they will also buy {1}".format(premise_name, conclusion_name))print("--SUPPORT: {0}".format(support[(premise, conclusion)]))print("--CONCLUSION: {0:.3f}".format(confidence[(premise, conclusion)]))#打印前5条支持度
for index in range(5):print("Rule #{0}".format(index + 1))(premise, conclusion) = sorted_support[index][0]print_rule(premise, conclusion, support, confidence, features)#打印前5条置信度
for index in range(5):print("Rule #{0}".format(index + 1))(premise, conclusion) = sorted_confidence[index][0]print_rule(premise, conclusion, support, confidence, features)得到的结果如下:
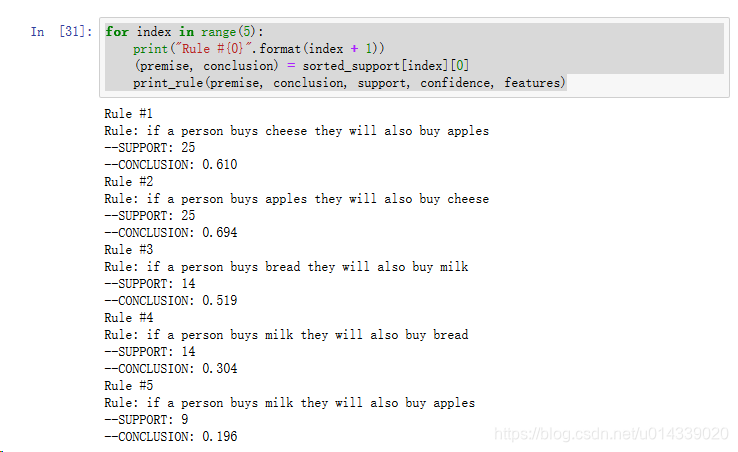
这篇关于数据挖掘系列笔记(1)——亲和性分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






