本文主要是介绍超算“猛将”英伟达,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在谈英伟达的大战略之前,明确两个重要事件:
英伟达NVIDIA在2019年3月公开以69亿美元现金收购Mellanox,该项交易最终在2020年4月尘埃落定。
英伟达NVIDIA在2020年9月宣布以400亿美元现金加股票的方式,对软银旗下芯片设计公司、全球重要芯片架构提供商Arm进行收购。
这两件事情的成功,为英伟达在芯片领域的发展带来了更深入、更广泛的发展前景,以及更为利好的影响。从资本市场的表现就可见一斑,按周一美东时间11月16日16:00收盘时的价格计算,英伟达的总市值为3335.56亿美元,几乎快超过某友商市值的两倍。友商名字不方便公布,大家可以猜猜看。
前些天业内朋友感叹,这一年,过得太快了。其实,我更想感叹,英伟达的市值飙升得太快了。
但这市值增长的背后,却暗藏着英伟达的更大图谋:超算大战略。
根据最新的TOP500榜单排名显示,英伟达全面领先,无论是针对超算领域的计算、网络还是HPC。

事实上,NVIDIA GPU和网络正在越来越多地用于加速世界上最快的超级计算机。
一是,基于NVIDIA技术构建的超算系统占比绝对领先,包括8个TOP10超算系统在内,近70%进入TOP500榜单的超算系统都基于NVIDIA技术构建。
二是,NVIDIA Selene超级计算机(HPC)在全球超级计算机速度排行中位列第五。该超级计算机基于NVIDIA DGX A100 640GB系统和NVIDIA Mellanox InfiniBand网络构建。
三是,在衡量系统能源效率的Green500榜单中,NVIDIA DGX SuperPOD系统位居榜首,得到业界一致肯定。
从SC20(Supercomputing Conference)超算大会公布的最新TOP500榜单可以看出,英伟达的超算大战略势在必得,将在强化现有技术能力部署的前提下,明确了下一步战略的“三驾马车”:GPU更强、HPC更快、网络更优。面向超算领域,英伟达的战略很明确,一点儿都不用含糊,更强更快更优,也将会是其长期屹立超算领域的制胜法宝。
更强:GPU一路高歌猛进
在超算行业,强中自有强中手。作为超算领域最佳加持者,英伟达在GPU这条发展路上,可谓一路高歌猛进。
AI算力的强大,再一次彰显了英伟达整体超算战略的英明。似乎,这也是英伟达命中注定的好趋势,谁叫AI行业化,行业AI化的智能化时代来得如此之快呢。
针对数据中心GPU需求来看,英伟达以A100、A40、V100、T4、RTX 6000、RTX 8000多款业界知名的产品系列既已覆盖。
然而术业有专攻。针对大流量数据工作负载方面,AI算力的需求特别突出,但是随着NVIDIA A100 80GB GPU的出现,非常有助于各种训练、推理和超级计算应用等方面的发展,在速度和性能上得以前所未有的满足。
作为英伟达创始人、现任CEO黄仁勋亲手推出的GPU力作,A100第一代产品是在几个月前的英伟达GTC 2020大会上首次亮相的。
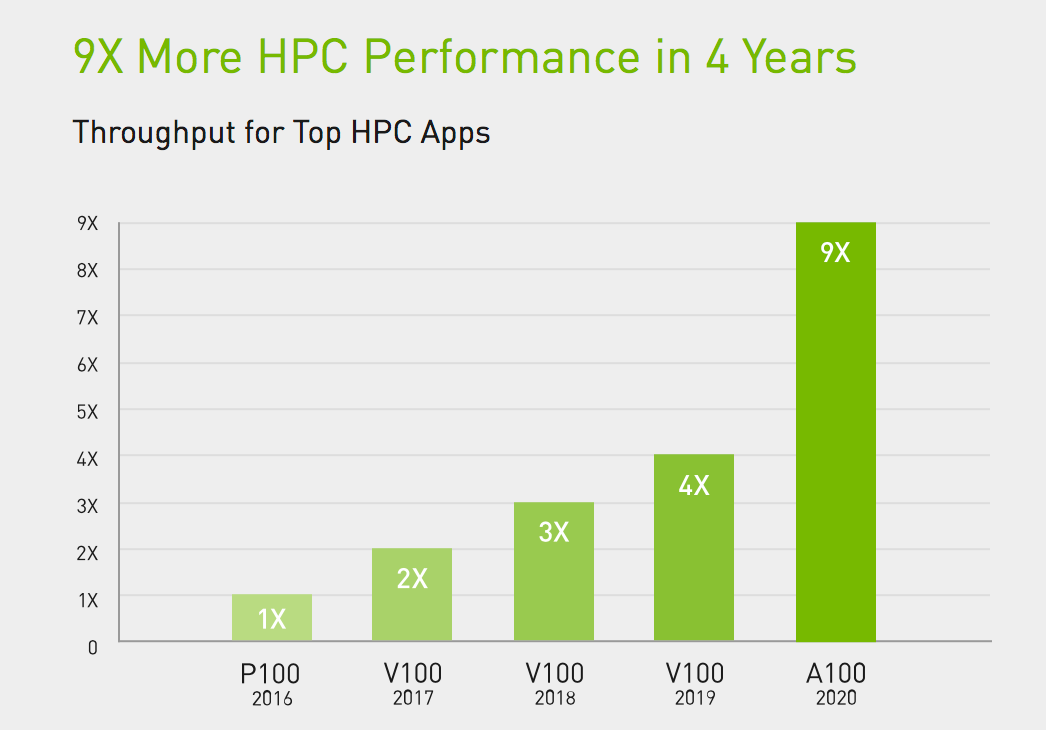
因为是基于英伟达安培(Ampere)架构的首款图形处理器,所以备受业界关注。当时A100引入了有着里程碑式意义的Tensor Cores双精度计算技术。要知道以前在NVIDIA V100 Tensor Core GPU上需要10个小时的双精度模拟作业,在A100上4小时即可完成。
NVIDIA A100 Tensor Core GPU针对AI、数据分析和高性能计算 (HPC)等应用上,实现了更强的加速,针对极其严峻的计算挑战上有了更大作为。A100高效扩展性也很突出,数千个A100 GPU在同一个系统中成功实现集成,也可以利用NVIDIA多实例 GPU (MIG) 技术将每个A100 划分割为七个独立的GPU实例,获得对各种规模工作负载的加速。
- 需要注意的是,这里针对HPC性能的对比中,仅限于NVIDIA V100 GPU第一代产品。
A100的出现,对数据中心大规模的计算带来了更强的优化效果,不仅统一了人工智能训练和推理,同时将灵活、弹性加速的实现可能性向前又推进一步。
作为A100 GPU系列中的最新力作,A100 80GB GPU在继承了第一代A100 GPU的优势基础上,内存比第一代A100 GPU提升一倍,也支持NVIDIA HGX AI超级计算平台。
大内存容量和高带宽,对于AI与HPC实际应用的好处有目共睹,毕竟在这个领域中一切都要以速度决胜负。全新A100采用HBM2e技术,可将A100 40GB GPU的高带宽内存增加一倍至80GB,提供每秒超过2TB的内存带宽。这使得数据可以快速传输到全球最快的数据中心GPU A100上,使研究人员能够更快地加速其应用,处理最大规模的模型和数据集。
由此,我们可以很容易看到全新一代的增强A100 80GB GPU在HPC领域的表现更为突出,相比最早一代2016年代表之作P100 GPU,A100 80GB GPU实现了HPC应用性能的11倍提升。
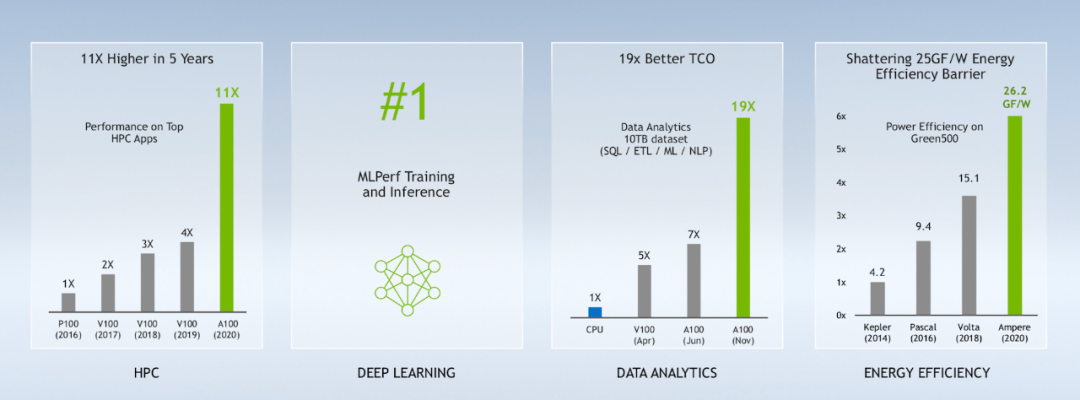
不仅如此,在深度学习、数据分析、能效方面都获得了前所未有的优化。
对于如RNN-T等自动语言识别模型的AI推理,单个A100 80GB MIG实例可处理更大规模的批量数据,将生产中的推理吞吐量提高1.25倍。
在TB级零售大数据分析基准上,A100 80GB将其性能提高了2倍,使其成为可对最大规模数据集进行快速分析的理想平台。随着数据的动态更新,企业可以实时做出关键决策。
对于科学应用,A100 80GB可为天气预报和量子化学等领域提供巨大的加速。材料模拟软件Quantum Espresso采用单节点A100 80GB实现了近2倍的吞吐量提升。

从这几个比较典型的需要大量数据存储空间的应用来看,A100 80GB GPU在应用性能上确实成为新一代GPU的亮点。由此在架构特性上可以总结为几点:
一是,采用第三代Tensor Core核心。通过全新TF32,将上一代Volta架构的AI吞吐量提高多达20倍。通过FP64,将HPC性能提高多达2.5倍。通过 INT8,将AI推理性能提高多达20倍,并且支持BF16数据格式。
二是,采用更大、更快的HBM2e GPU内存。从而使内存容量增加一倍,在业内率先实现2TB/s以上的内存带宽。
三是,采用MIG技术,将单个独立实例的内存增加一倍,可最多提供七个MIG,每个实例具备10GB内存。
四是,采用结构化稀疏技术,将推理稀疏模型的速度提高两倍。
五是,第三代NVLink和NVSwitch,相较于上一代互连技术,可使GPU之间的带宽增加至原来的两倍,将数据密集型工作负载的GPU数据传输速度提高至每秒600 gigabytes。
AI能力的强大,表现在GPU产品的推陈出新,以及GPU为行业应用带来革命性的改变。这就是英伟达的过人之处,好技术带来行业改变和产业格局变化。
更智即更强。由此而言,对于超算行业的发展来说,更智能也就自然表现得更为强大了。
更快:HPC没有最快只有更快
超算的核心在于快,竞争的价值在于更快。在超算领域只有在超算系统上实现更快的速度,才能实现超算系统整体能力的更强。
作为强化AI算力的全球领先厂商,英伟达新一代DGX Station A100和DGX A100 640GB移动数据中心引起了我特别的注意,这也是在 SC20超级计算大会上与A100 80GB GPU同期发布的重量级产品。

DGX Station A100的AI性能可以达到2.5 petaflops,通过NVIDIA NVLink完全互连,实现四个全新NVIDIA A100 80GB GPU融合在一起的工作组服务器,同时GPU内存高达320GB。更为特别是DGX Station A100也是唯一支持NVIDIA多实例GPU技术(MIG)的工作组服务器。借助MIG,单一DGX Station A100最多可提供28个独立GPU实例以运行并行任务,并可在不影响系统性能的前提下支持多用户应用。
这也是全球唯一的千万亿级工作组服务器,如此性能超快的DGX Station A100,被业内称之为一体式AI数据中心,也就是说,用户借助一台DGX Station A100,就可以在任何地方部署AI超算中心了。
如此说来,作为服务器级的系统,DGX Station A100无需配备数据中心级电源或散热系统,却具有与NVIDIA DGX A100数据中心系统相同的远程管理功能。当数据科学家和研究人员在家中或实验室办公时,系统管理员可轻松地通过远程连接,执行任何管理任务。
作为一台随处可得的AI超级计算机,性能上的突出表现尤为吸引人。为支持诸如BERT Large推理等复杂的对话式AI模型,DGX Station A100比上一代DGX Station提速4倍以上。对于BERT Large AI训练,其性能提高近3倍。

此外,全新DGX A100 640GB系统也将集成到企业版NVIDIA DGX SuperPOD解决方案,使机构能基于以20 个DGX A100系统为单位的一站式AI超级计算机,实现大规模AI模型的构建、训练和部署。

配备A100 80GB GPU的NVIDIA DGX SuperPOD系统将率先安装于英国的Cambridge-1超级计算机,以加速推进医疗健康领域研究,以及佛罗里达大学的全新HiPerGator AI超级计算机,该超级计算机将赋力这一“阳光之州”开展AI赋能的科学发现。
由此可见,新一代DGX Station A100和DGX A100 640GB移动数据中心的出现,将给AI超级计算机的行业格局带来一次新的震动。全球云观察分析,这有望将超算从传统超算时代推向真正的智能超算时代,那么英伟达必定就是其中举足轻重的使能者之一。同时AI超算上的创新也将因为NVIDIA A100 80GB GPU而再次迎来新的发展,对AI超算的行业应用普及带来了更大的发展潜力与空间。
更优:高效网络性能空前
任何超算系统,离开了高效的网络,基本上谈不上超算。可见网络对于超算系统整体价值的贡献缺一不可。
为此,英伟达并购Mellanox后,对于InfiniBand高效网络的性能发挥得到了空前的提升。
400G InfiniBand系统在之前听说过业内传闻,没有想到英伟达如今很快变成了现实。“NVIDIA Mellanox 400G InfiniBand的海量吞吐量和智能加速引擎使HPC、AI和超大规模云基础设施能够以更低的成本和复杂性,实现了全球最具挑战性的网络互连性能。”
为了支撑更强更快的AI超算的需要,Mellanox 400G InfiniBand带来的加速能力也是值得一看。Mellanox NDR 400G InfiniBand交换机,可提供3倍的端口密度和32倍的AI加速能力。并且将框式交换机系统的聚合双向吞吐量提高了5倍,达到1.64 petabits/s,减少交换机使用量获得更大工作负载的支撑,必然对用户整体应用成本带来更良好的回报。

当然,好的产品,特别是在行业领域有着技术创新领先性的产品,往往赢得市场的认同更为广泛。
从一组财报数据来看,英伟达截至2020年7月26日的第二季度财报,营收为38.7亿美元,创历史新高,较去年同期的25.8亿美元增长50%,较上一季度的30.8亿美元增长26%。
其中有一个关键信息就是该季度数据中心方面业务收入出奇高增长,财报期内为17.5亿美元,为2019年同期收入6.55亿美元的两倍多。这也是数据中心领域带来的收入首次出现超越英伟达成立以来的主营视频游戏领域业务,财报期内视频游戏业务为16.5亿美元。
就此来说,英伟达在数据中心取得高速增长成绩,与收购Mellanox有着密切相关。
可见,英伟达Mellanox在高效网络方面的性能表现,已经赢得了用户的心声,特别是在超算领域,英伟达Mellanox的InfiniBand技术一直备受瞩目。
小结:AI超算的未来已来
英伟达的超算大战略,必然就是将AI加入到HPC中,并扩展至传统超级计算中心之外的平台,从而引发了全球AI超算大趋势。

与此同时,创新效率超高的英伟达,在加速计算领域、HPC、网络三大领域分别发布了新一代A100 80GB GPU处理器、新一代DGX StationA100和DGX A100 640GB移动数据中心、Mellanox 400G InfiniBand系统多款重磅新品,可谓三驾马车并驾齐驱,以应对全球爆发式增长的数据处理需求和日益凸显的机器学习需要。这对全球超算整体格局的变化,带来非常积极的推动作用。
更强的GPU,更快的AI超算,更优的高效网络,也将成为英伟达持续向前发展的重要三部曲。
(by Aming)
- END-
你
怎
么
看
?
欢迎文末评论补充!
文章来源:Aming,全球云观察,著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。本文和作者回复仅代表个人观点,不构成任何投资建议。
都看到这里了,加个关注吧!
【阿明】:科技评论专栏作者、科技媒体从业22年、新闻评论年产出上百万字,用数据说话,带你看懂科技上市公司
这篇关于超算“猛将”英伟达的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!