本文主要是介绍【Linux】利用消息队列实现一个简单的进程间双向通信(两种方式),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在实现利用消息队列的进程间通信之前,先了解一下基本的概念和所需要用到的函数。
消息队列
- 消息队列是Linux内核地址空间中的内部链表,各个进程可以通过它来进行消息传递。
- 进程发送的消息会顺序写入消息队列之中,且每个消息队列都有IPC标识符唯一地进行标识。简单理解就是,每个消息队列都有一个ID号,而这个号用来区分不同的消息队列,从而保证不同消息队列之间不冲突。而每个消息队列内部也维护了一个独立的链表。
消息缓冲区的基本结构
消息缓冲区可以理解成进程通过消息队列在传送或接收消息时的信息容器。
当有人发送信息时则将信息通过消息缓冲区放入队列,有人读取此消息队列时,则从队列中取出信息放入接收方缓冲区(先进先出)。
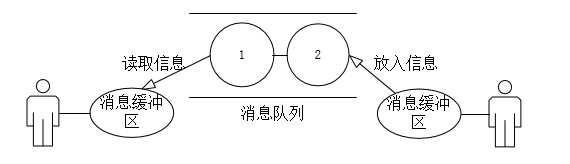
而消息缓冲区的常用结构是msgbuf结构:
struct msgbuf{long mtype;char mtext[1];
}
其中第一个成员mtype表示消息类型,一般用正数来表示,其作用是为某个消息设定一个类型,从而保证自己在消息队列中正确地发送和接收自己的消息;
第二个成员即具体的数据,其大小可以由我们自行重新构建。
消息的大小有一个最大限制,其定义在Linux/msg.h文件中
#define MSGMAX 8192
也就是说,消息结构的总大小不能超过8192字节(包括type的大小)
键值构建ftok()函数
前面说到了,每个消息队列都需要一个唯一的IPC作为标识符。
而ftok()函数即实现将文件路径名和项目的表示符转变成一个系统IPC键值。
它的函数原型描述如下:
# include <sys/types.h>
# include <sys/ipc,.h>
key_t ftok(const char *pathname, int proj_id);
其中的pathname必须是已经存在的目录,而项目的表示符是一个8位,1个字节的值,通常情况下用a,b等字母表示。
获得消息msgget()函数
如果我们想访问消息队列的信息或者向消息队列写入信息,首先便要使用msgget()函数,它会返回一个队列标识符。
它的作用就是创建一个新的消息队列,或者访问一个已经存在的消息队列。
其函数原型如下所示:
# include <sys/types.h>
# include <sys/ipc.h>
# include <sys/msg,h>
int msgget(key_t key, int msgflg);
该函数的第一个参数不难理解,就是刚才ftok()函数生成的唯一ipc键值,它用来定位消息队列。
而第二个参数则是在定位到消息队列之后的一系列权限操作。其取值有IPC_CREAT与IPC_EXCL两种:
- IPC_CREAT:若内核中不存在指定队列就创建它;
- IPC_EXCL:当与IPC_CREAT一起使用时,若队列已存在则出错(函数返回-1)。
实际上,第二个参数还需要与文件权限一起使用,如IPC_CREAT|00666表示若内核中不存在指定队列则创建它,同时进程可以对队列消息进行读写操作。
简单点儿说,就是第一个用来找到队列,第二个则是定义相关的权限及操作。
发送消息msgsnd()函数
当我们通过msgget()函数得到了队列标识符,我们就可以在对应的消息队列上来执行相关的读写操作了,如果我们要发送消息,则需要用到的就是msgsnd()函数,它的原型如下所示:
# include <sys/types.h>
# include <sys/ipc.h>
# include <sys/msg,h>
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);
其实从命名就可以大概看出来,第一个参数是消息队列的id,message queue id,即用来告诉系统向哪个消息队列发送消息;
第二个参数是message pointer,是一个空型指针,这个但从命名似乎看不太出来其意义,但是根据刚刚画的那个小模型,应该需要用到消息缓冲区,其实这个指针就是指向消息缓冲区的;
第三个参数是message size,顾名思义,就是消息的长度,它是以字节为单位的,注意,这里的大小单纯指消息的大小,并不含消息类型的大小;
第四个参数是message flag,它通常取0,也就是忽略它,也可以设置成IPC_NOWAIT,如果设置成后者,也就是不等待,即消息队列满了的话就不等了,今天你爱搭不理,明天我高攀不起,若不指定的话,则会阻塞等待,直到可以写入为止。
接受消息msgrcv()函数
同样的道理,当我们获取了队列标识符后,也可以通过msgrcv()函数来在指定消息队列上接受消息,其函数原型如下:
# include <sys/types.h>
# include <sys/ipc.h>
# include <sys/msg,h>
int msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg);
前三个参数和上述发送函数msgsnd()函数的参数作用相同
最后一个参数作用也是一样的。
而第四个参数则指定要从队列中获取的消息类型,若取0,则不管是什么类型都接收。
利用消息队列实现一个简单的进程间通信
在介绍完上述概念之后,我们可以知道每个消息队列都有一个独特的IPC值,而每个消息队列内,可以有不同类型的消息进行传递。
而进程在收发消息时,都需要借助一个消息缓冲区进行。
故而单向通信只要保证不同进程读写的是同一个消息队列(key值相同),并且收发同一种消息类型即可。
而双向通信则可以通过以下两种基本方式进行:
- 创建两个消息队列来进行通信
根据之前的简单模型,我们可以画出使用这种方式进行双向通信的基本示意图:

也就是说,两个不同的进程需要使用两个对应的key来调用msgget()函数。
这里直接po代码和注释:
上述代码是其中一个文件所使用的,而另一个只需要将收发消息的队列颠倒即可(将key值交换)。#include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/types.h> #include <sys/msg.h> #include <unistd.h> #include <sys/ipc.h>int main(){int ret = -1;int msg_flags, smsg_id ,rmsg_id;/*创建消息队列函数所用的标志位,以及收消息与发消息的队列id*/key_t key1,key2;/*队列的键值*/struct msgmbuf{/*消息的缓冲区结构*/long mtype; // 注意long与int的字长问题char mtext[10];};struct msgmbuf msg_mbuf;/*创建消息缓冲区*/int msg_sflags,msg_rflags;/*收发消息函数所用的标志位*/char *msgpath1 = "/usr/bin";/*消息key1产生所用的路径*/char *msgpath2 = "/usr/bin";/*消息key2产生所用的路径*/key1 = ftok(msgpath1,'b');/*产生key1*/key2 = ftok(msgpath2,'a');/*产生key2*/if(key1 != -1 || key2 != -1)/*产生key成功*/{printf("成功建立KEY\n"); }else/*产生key失败*/{printf("建立KEY失败\n"); }msg_flags = IPC_CREAT;//|IPC_EXCL; /*设置创建消息的标志位*/smsg_id = msgget(key1, msg_flags|0666); /*建立收消息的消息队列*/rmsg_id = msgget(key2, msg_flags|0666); /*建立发消息的消息队列*/if( -1 == smsg_id || -1 == rmsg_id){printf("消息建立失败\n");return 0; } pid_t pid;pid = fork();/*通过fork()创建子进程,主进程进行发消息,子进程进行收消息*/while(1){if(pid != 0){/*主进程*/msg_sflags = IPC_NOWAIT;/*当消息队列满了的时候不等待*/msg_mbuf.mtype = 10;/*设置发送的消息类型*/sleep(1);char *content;content = (char*)malloc(10*sizeof(char));printf("input:\n");scanf("%s",content);/*用户输入内容*/if(strncmp(content,"end",3) == 0)/*如果前三个字符为end,则跳出循环*/break;memcpy(msg_mbuf.mtext,content,10);/*复制字符串*/ret = msgsnd(smsg_id, &msg_mbuf, 10, msg_sflags);/*发送消息*/if( -1 == ret){printf("发送消息失败\n"); }}else{/*子进程*/sleep(1);msg_mbuf.mtype = 10;/*设置收消息的类型*/msg_rflags = IPC_NOWAIT;//|MSG_NOERROR;ret = msgrcv(rmsg_id, &msg_mbuf,10,10,msg_rflags);/*接收消息*/if( -1 == ret){/*可添加出错处理等*/}else{printf("接收消息成功,长度:%d\n",ret); printf("content:%s\n",msg_mbuf.mtext); }}}ret = msgctl(rmsg_id, IPC_RMID,NULL);/*删除收消息的队列*/if(-1 == ret){printf("删除消息失败\n");return 0; }return 0; } - 通过创建不同的消息类型来进行双向通信
这种方式是指在同一个消息队列中,使用不同的消息类型来标识收发信息,基本示意图如下:

图中不同颜色的信息表示不同的消息类型。这就要求在发送信息时将消息缓冲区中的类型值设置好,在收信息时则要在msgrcv()函数中的第四个参数匹配发送方的消息类型。
代码如下:
同样的,这里只是其中一个文件的代码,而另一个将对应的收发信息的类型颠倒即可。#include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/types.h> #include <sys/msg.h> #include <unistd.h> #include <sys/ipc.h>int main(){int ret = -1;int msg_flags, msg_id;/*创建消息队列函数所用的标志位以及消息队列的id号*/key_t key;/*队列的键值*/struct msgmbuf{/*消息的缓冲区结构*/long mtype; // 注意long与int类型的字长问题char mtext[10];};struct msgmbuf msg_mbuf;/*创建消息缓冲区*/int msg_sflags,msg_rflags;/*收发消息函数所用的标志位*/char *msgpath = "/usr/bin/";/*消息key产生所用的路径*/key = ftok(msgpath,'b');/*产生key*/if(key != -1)/*产生key成功*/{printf("成功建立KEY\n"); }else/*产生key失败*/{printf("建立KEY失败\n"); }msg_flags = IPC_CREAT;//|IPC_EXCL; /*设置创建消息的标志位*/msg_id = msgget(key, msg_flags|0666); /*建立消息队列*/if( -1 == msg_id ){printf("消息建立失败\n");return 0; } pid_t pid;pid = fork();/*通过fork()创建子进程,主进程进行发消息,子进程进行收消息*/while(1){if(pid != 0){/*主进程*/msg_sflags = IPC_NOWAIT;msg_mbuf.mtype = 10;/*发送消息的类型为10,另一个进程收消息的类型应为10*/sleep(1);char *content;content = (char*)malloc(10*sizeof(char));printf("input:\n");scanf("%s",content);/*用户输入内容*/if(strncmp(content,"end",3) == 0)/*如果前三个字符为end,则跳出循环*/break;memcpy(msg_mbuf.mtext,content,10);/*复制字符串*/ret = msgsnd(msg_id, &msg_mbuf, 10, msg_sflags);/*发送消息*/if( -1 == ret){printf("发送消息失败\n"); }}else{/*子进程*/sleep(1);msg_mbuf.mtype = 11;/*收消息的类型为11,另一个进程发消息的类型应为11*/msg_rflags = IPC_NOWAIT;//|MSG_NOERROR;ret = msgrcv(msg_id, &msg_mbuf,10,11,msg_rflags);/*接收消息*/if( -1 == ret){/*可添加出错处理等*/}else{printf("接收消息成功,长度:%d\n",ret); printf("content:%s\n",msg_mbuf.mtext); }}}ret = msgctl(msg_id, IPC_RMID,NULL);/*删除消息队列*/if(-1 == ret){printf("删除消息失败\n");return 0; }return 0; }
最终两者实现的效果是相同的:

附
从上面的代码我们可以观察到一个没有提到的函数msgctl()函数,它是用来在消息队列上执行控制操作,如获取队列的基本情况,设置消息队列状态以及删除队列等。
在了解msgctl()函数之前,应该先了解一下消息队列的基本结构,实际上,每个消息队列都有相应的数据结构来记录其信息:
struct msqid_ds {struct ipc_perm msg_perm;struct msg *msg_first; /* first message on queue,unused */struct msg *msg_last; /* last message in queue,unused */__kernel_time_t msg_stime; /* last msgsnd time */__kernel_time_t msg_rtime; /* last msgrcv time */__kernel_time_t msg_ctime; /* last change time */unsigned long msg_lcbytes; /* Reuse junk fields for 32 bit */unsigned long msg_lqbytes; /* ditto */unsigned short msg_cbytes; /* current number of bytes on queue */unsigned short msg_qnum; /* number of messages in queue */unsigned short msg_qbytes; /* max number of bytes on queue */__kernel_ipc_pid_t msg_lspid; /* pid of last msgsnd */__kernel_ipc_pid_t msg_lrpid; /* last receive pid */
};
此定义位于linux源代码的include/uapi/linux/msg.h之中。可以看到它记录了消息队列的许可权限信息,以及消息时间戳,消息数目,当前的消息大小,最大容量以及使用该消息队列进行收发的进程id等。
而结果ipc_perm的定义如下:
struct ipc_perm
{__kernel_key_t key;//函数msgget()使用的键值__kernel_uid_t uid;//用户的uid__kernel_gid_t gid;//用户的gid__kernel_uid_t cuid;//建立者的uid__kernel_gid_t cgid;//建立责的gid__kernel_mode_t mode; //权限unsigned short seq;//序列号
};
它的定义位于linux源代码的include/uapi/linux/ipc.h之中,此文件中还有如上述IPC_START等参数定义。
此时我们再来看msgctl()的函数原型:
# include <sys/types.h>
# include <sys/ipc,h>
# include <sys/msg.h>
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
第一个参数顾名思义,就是message queue id,即操作的消息队列的id,由msgget()函数获得;
第二个参数是控制命令,它的取值如下:
#define IPC_RMID 0 /* remove resource */
#define IPC_SET 1 /* set ipc_perm options */
#define IPC_STAT 2 /* get ipc_perm options */
#define IPC_INFO 3 /* see ipcs */
IPC_STAT即获取队列的msqid_ds中的ipc_perm的设置(这个要看linux内核版本,有的可以用其查看整个结构信息),并把它存放在第三个参数指向的位置。
IPC_RMID即将对应的消息队列从内核中删除
IPC_SET即设置消息队列结构中的ipc_perm的成员的值
IPC_INFO即获取结构信息(这个要看linux内核版本,有的并没有这个值)
而msgctl()函数的第三个参数即指向消息队列数据结构的buf指针。
以上。
这篇关于【Linux】利用消息队列实现一个简单的进程间双向通信(两种方式)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





