本文主要是介绍TJU自然语言处理(5):词义消岐,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
TJU自然语言处理(5):词义消岐
- 定义
- 预备知识
- 有监督学习
- 无监督学习
- 现实情况
- 伪词
- 算法的上界和下界
- 基于贝叶斯分类的词义消歧
- 基于互信息的WSD方法
- flip-flop算法
- 贝叶斯和互信息算法的比较
- 基于词典的消岐
- 基于义类词典的消岐
- 语义消岐的两个约束
- 有监督词义消岐小结
定义
语义歧义:很多词语具有几个意思或语义,如果将这样的词从上下文中独立出来,就会产生语义歧义。就是必须通过其语境来确定其含义的词汇。
比如:生意清淡和口味清淡。
语义消岐(WSD):确定一个歧义词的哪一种语义在一个特殊的使用环境中被调用。
WSD需要解决的三个问题:
- 如何判断一个词是不是多义词
- 对每个需要进行义项标注处理的多义词,预先得有关于它的各个不同义项的清晰的区分标准,也即如何表示一个多义词的不同意思
- 对出现在具体语境中的每个多义词,给它确定一个合适的义项
我们通过一个词周围的搭配词,即上下文语境来了解意义。
预备知识
有监督和无监督学习
算法性能的上界和下界
有监督学习
- 训练数据已知(语义标注)
- 分类任务
- 函数拟合(function-fitting):基于一些数据点推断出函数的形态
无监督学习
- 训练数据的分类未知
- 聚类任务(clustering task)
现实情况
- 从未标注数据中学习
- 使用多种知识源
- 建立种子集→从未标注数据中学习→扩大种子集→获取大规模标注语料
伪词
在测试数据难以获得的情况下,可方便地产生一些人工数据,用来比较和提高算法性能。在语义消歧的情况下,这些人工数据称为伪词。
- 例如,合并两个或多个自然词汇,
创建伪词banana-door,代替语料库中出现的所有banana和door
这样做的意义在于:既回避了手工标注的困难,又可以为消歧问题轻松创建大规模的训练和测试数据。即带有伪词的文本作为歧义文本,最初的文本作为消歧后的文本。
算法的上界和下界
上界通常指人工效能。
下界通常指可能的最简单算法的效能。
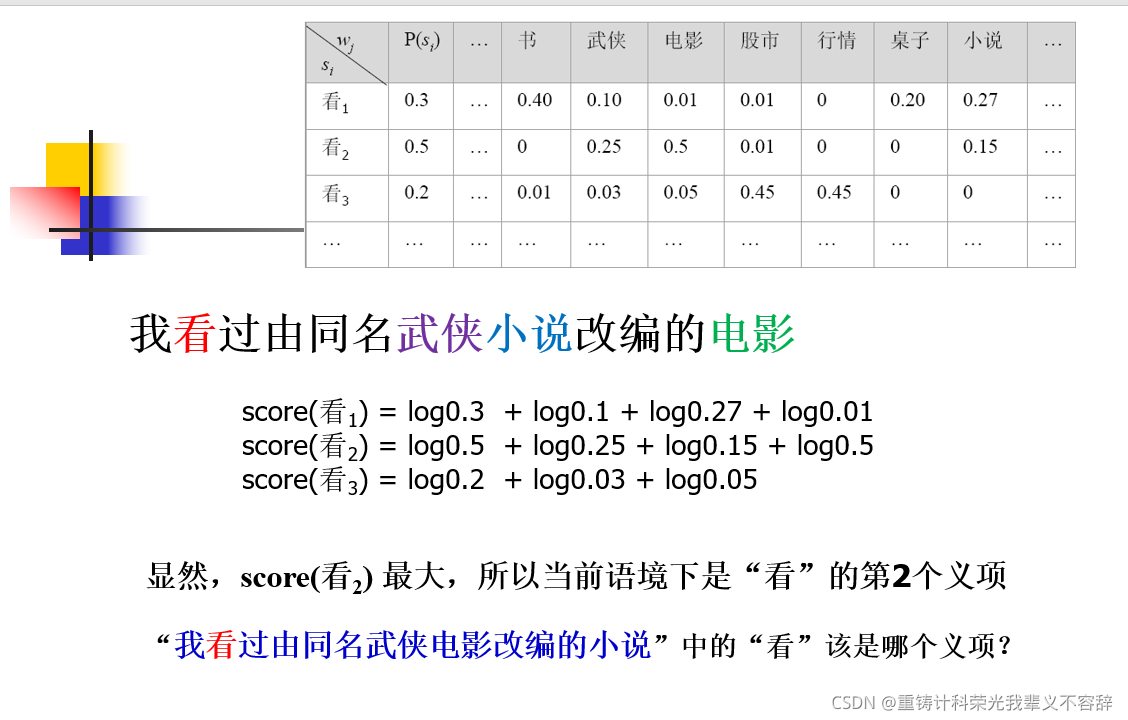
基于贝叶斯分类的词义消歧
基本思想:

基于互信息的WSD方法
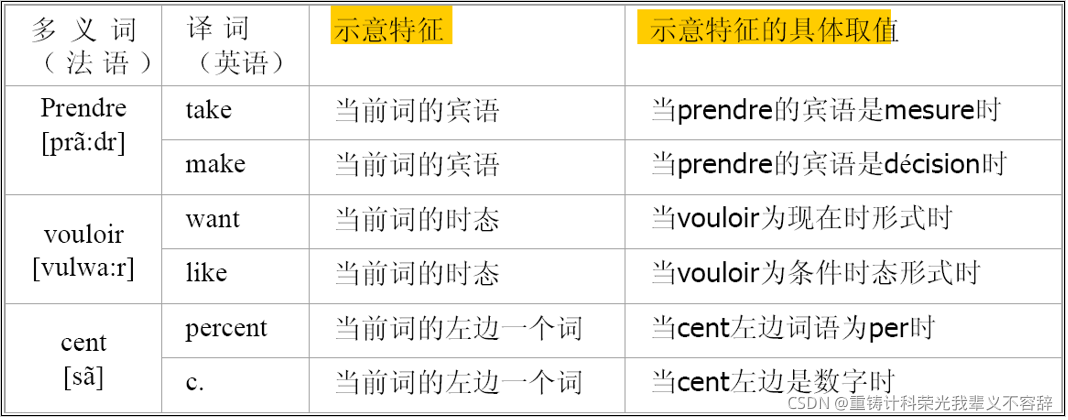
要判断多义词在具体语境下的意义,关键是找到能够指示该多义词意义的示意特征(indicator)。
例如:
flip-flop算法




贝叶斯和互信息算法的比较
- 相同之处:都需要事先进行义项标注的语料库进行训练。
- 不同之处1:对语境的理解不同,贝叶斯是大语境下,而互信息是小语境
- 不同之处2:对训练语料库的要求不同,贝叶斯不需要标注结构信息,而根据训练目标,需要标注更多信息。
基于词典的消岐
算法描述:
简单的说就是一个多义词中都多个释义,每个释义都会有一个解释。而特征词也会有释义,就比较一下,特征词释义解释和多义词释义解释中相同的多少来找出得分最大的就是义项了。下面是一个典型的例子。
方法总结:
用词典资源进行词义排歧,是利用词典中对多义词的各个义项的描写,而这些描写是在语言学家观察了多义词的不同使用情况后概括归纳,抽象总结的结果。只不过跟实际语料不同的是,它是以一种概括的方式在描写词义,而语料库是以具体可感知的大量重复的实例本身在描写词义。
由于词典释义的概括性,这种方法应用于实际语料中多义词的排歧,效果不理想。
基于义类词典的消岐
原理:上下文中词汇的语义范畴大体上确定了此上下文的语义范畴,且上下文的语义范畴可以反过来确定词汇的哪一个语义被使用。
英语词“crane”有两个意思,一是指“吊车”,一是指“鹤”。前者属于“工具/机械”这个义类;后者属于“动物”这个义类。如果能够确定“crane”出现在具体语境中时属于哪个义类,实际上也就知道了“crane”的义项。
- 收集数据:对Roget词典中每个义类(共1041个类)中所有的词,收集包含这些词的上下文C(每个词的上下文长度为前后100个词)作为训练数据。


总结:是对一个多义词所处语境的“主题领域”的猜测,假定如果当前主题领域猜对了,该多义词的义项也能判定正确
对训练语料库不需要事先标注
对义项区别依赖大语境的多义词效果较好(比如名词);对那些不依靠大语境提示词义的多义词效果较差(比如动词和形容词)
语义消岐的两个约束
- 每篇文本一个语义:在任意给定的文本中目标词语义有很强的一致性。可以抵消信息不足和误导信息带来的影响。
- 每个搭配一个语义:根据和目标词之间的相对距离、次序和句法关系,相邻词提供了可用于判断目标词语义的很多线索信息。
有监督词义消岐小结


这篇关于TJU自然语言处理(5):词义消岐的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




