本文主要是介绍TSG(The Spectral Geologist)软件操作--导入外部光谱数据(SWIR/TIR数据)/照片数据/点数据(深度、地化数据等),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
TSG(The Spectral Geologist)软件操作–导入外部光谱数据(SWIR/TIR数据)/照片数据/点数据(深度、地化数据等)
一、从外部打开或者导入数据
1.点击file打开或者导入数据
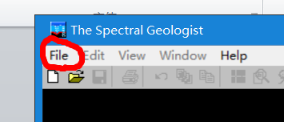
2.导入原始数据时,点击new新建工程文件
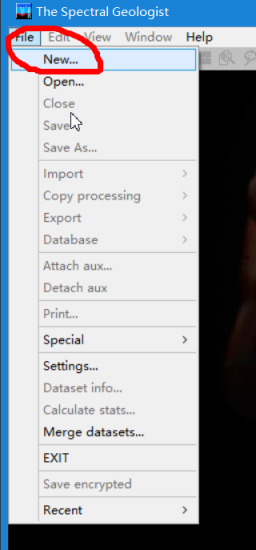
3.点击format菜单选择要导入的数据文件类型(可以在这选择导入txt文件数据、ASD数据、Excel、csv数据、ENVI波谱库数据、Hylogging数据等不同类型)

4.选择type中波谱数据的格式类型

5.点击选择文件夹导入数据或者逐条数据导入

6.选择数据单位(对于项目数据为aglient,点击勾选后面convert将波长单位由波数转化为波长nm);
之后,选择输入数据的波长范围;

7.从电脑或者硬盘选择保存文件夹,导入波谱数据

(二)数据界面介绍:
主界面为summary界面,上部条形窗口一般显示软件自动识别的矿物类型及总体含量占比;下部条形窗口一般显示在钻孔不同深度的矿物及其占比,以百分比形式显示。

第二个界面为log界面,以条形柱状图的方式显示不同要素的统计数据,其纵轴一般为钻孔深度,横轴一般为不同的统计要素变量,要素可以根据需要进行数量和内容选择;
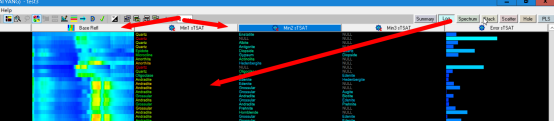
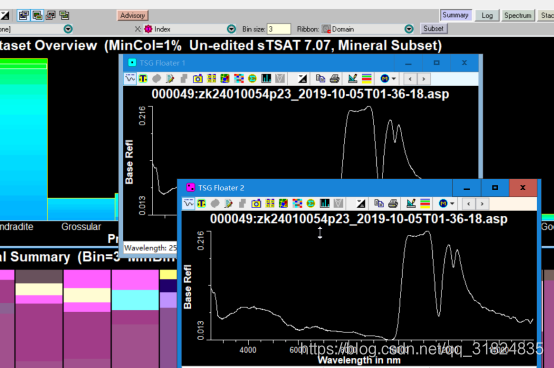
第三个界面为spectral界面,显示导入数据的波谱图像,在左上侧可以点击打开软件已有的波谱数据库;

第四个界面为stack界面,在这个界面叠加显示了导入的所有或者部分波谱数据,纵轴为钻孔深度,横轴为波长;

第五个界面为scroll界面,在这个界面以统计图的方式显示不同要素的统计数据,统计图的数量可以在上方改变,统计图内容可以通过改变x;y轴的定义来选择显示不同的数据;其中,双击每一个小图标可以将图标放大显示,之后进行内容编辑。
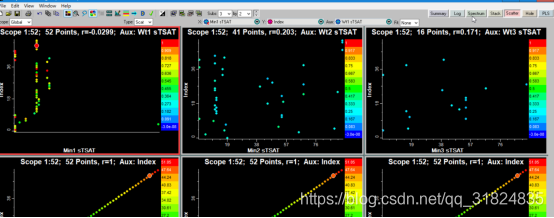
第六个界面为hole界面,这个界面以柱状图的方式直观显示钻孔深度和不同要素的变化关系,条形图数量和内容可以根据需要进行选择;

(三)窗口按钮功能介绍,其中四个窗格形式的按钮可以在不同位置同时显示不同的内容;黑白三角形式的按钮可以改变窗口背景图的颜色;
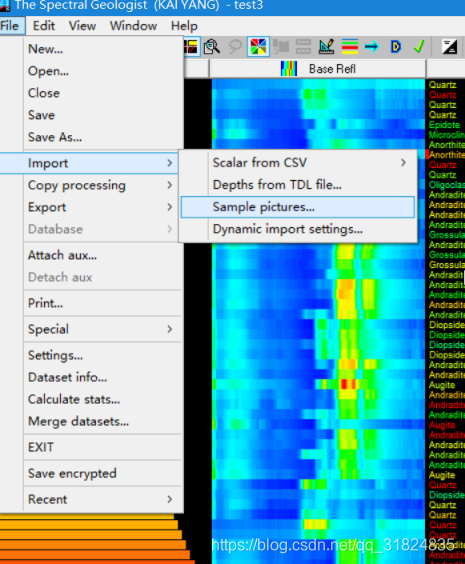
二、导入栅格格式的照片数据;
点击file》》》import》》》》sample picture进行照片导入照片排序按照波谱数据排序即可,为防止排序错误,一般要求将照片数据命名为波谱数据相同名称。
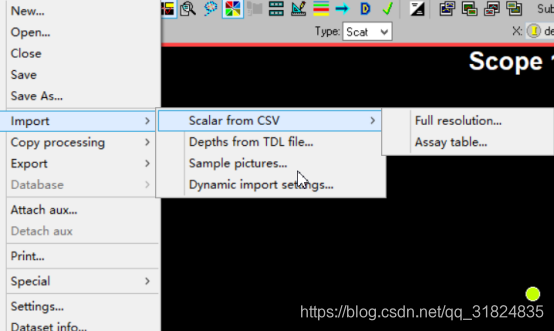
三、导入钻孔深度:
1.首先建立CSV格式的文件(可在excel中另存为CSV格式);
钻孔数据需要两列第一列一般为光谱数据同名数据或者按顺序编码数据(此时要求数据排列和数据量都和光谱数据相同);
两列数据要求有表头,表头尽量为数字构成,方便后续软件识别导入;
第二列深度数据为每条光谱数据对应的钻孔深度数据;
2.之后点击file》import》scalar from CSV》assay table导入钻孔数据
方法可以选择IMPORT或者ASSAY方法,进行数据的导入;(后面参数设置)
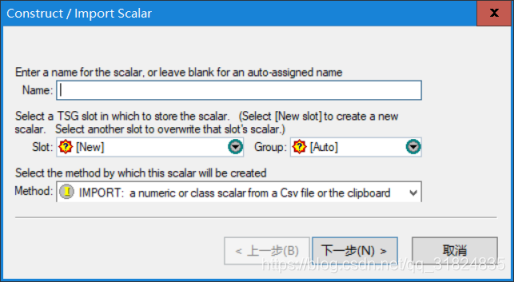

在CSV column to import中,选择钻孔深度数据,在style中选择num格式;
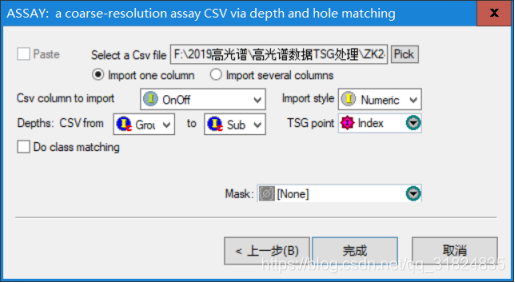
四、合并数据库数据
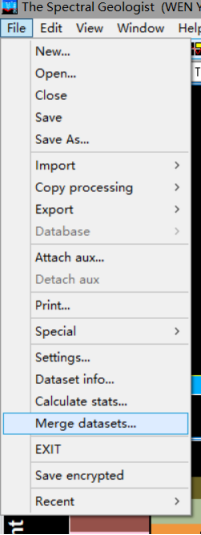

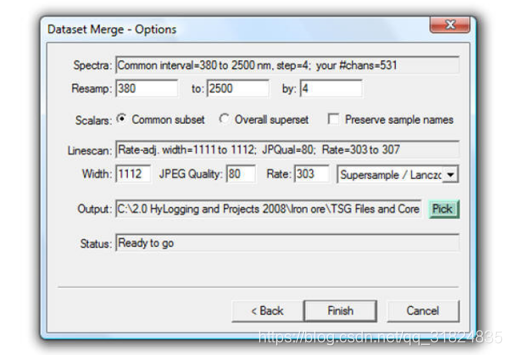
这篇关于TSG(The Spectral Geologist)软件操作--导入外部光谱数据(SWIR/TIR数据)/照片数据/点数据(深度、地化数据等)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






