本文主要是介绍sqlserver 数据迁移之bcp,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
BCP(Bulk Copy Program)是 SQL Server 中用于大量数据导入和导出的工具。在进行数据迁移时,我们可以使用 BCP 来提高数据迁移的效率和性能。以下是一些优化 BCP 的常见方法:
1.使用合适的数据类型:
在导出和导入数据时,确保使用正确的数据类型。使用较小的数据类型可以减少数据传输的大小,从而提高迁移速度。
2.指定合适的字符集:
在导出和导入数据时,指定适当的字符集可以避免字符转换和编码问题。使用正确的字符集可以提高数据迁移的准确性和效率。
3.分批处理数据:
如果数据量较大,可以将数据分成多个批次进行迁移。这样可以减少一次性加载的数据量,降低内存消耗,并提高迁移速度。
使用并行迁移:
4.BCP 支持并行迁移,可以同时将数据导入到多个目标表中。通过设置合适的并行度,可以提高数据迁移的速度
调整缓冲区大小:
5.BCP 使用缓冲区来存储要导入或导出的数据。适当调整缓冲区的大小可以提高数据迁移的效率。较大的缓冲区可以减少磁盘 I/O 操作的次数,从而提高迁移速度。
6.禁用错误检查:
在导入和导出数据时,可以禁用错误检查以提高迁移速度。但是请注意,禁用错误检查可能会导致数据完整性问题,因此请谨慎使用。
7.使用压缩选项:
BCP 支持压缩选项,可以在导入和导出数据时压缩数据。压缩可以减少数据传输的大小,从而提高迁移速度。
8.监控和优化性能:
在进行数据迁移时,可以使用性能监视工具来监控 BCP 的性能指标,如传输速度、内存使用等。根据监控结果,可以进一步优化 BCP 的配置和参数,以提高迁移性能。
下面提供操作示例
方法一:cmd-bcp语句
1、 win+r运行cmd
2、导出数据
格式:bcp “sql语句” queryout “文件路径” -c -E -k -S IP地址 -U “用户名” -P “密码”
语句:
bcp "select 查询的字段名 from 表名 where 条件" queryout "D:\文件保存路径.txt" -c -E -k -S 数据库地址 -U "用户名" -P "密码"
执行成功:
这里的速度还是挺快的,一秒能从亿级数据中迁移十二万左右
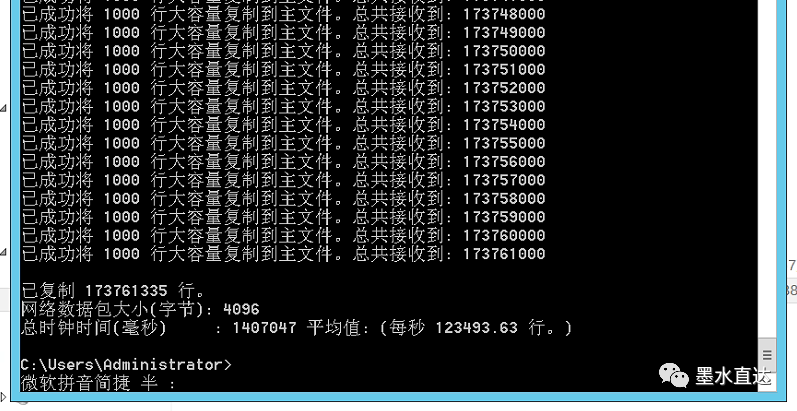
3、导入数据
格式:bcp 模式名.表名 in “文件路径” -c -E -k -S IP地址 -d 数据库名 -U “用户名” -P “密码”
语句示例:
bcp 导入的表名 in "D:\存储的路径.txt" -c -E -k -S 数据库地址 -d 数据库名 -U "用户名" -P "密码"4、迁移思路迁移老表数据drop原表新表改名成老表名方法二:C#调用cmd
优点:可以改成定时任务定期执行,执行比较方便,日志可自定义,比较详细
#region 使用bcp迁移数据/// <summary>/// bcp迁移数据/// </summary>public void BcpDataMigration(string qid){try{string allrowsql = "select count(*) from 表名";DataTable allrowdata = DBHelper.QueryToDataTable(allrowsql);int allrow = Convert.ToInt32(allrowdata.Rows[0][0]);
//导出表数据string exprotanswersql = "bcp \" select 字段名 from 表名 where 条件 \" queryout \"D:\\存储路径.txt\" -c -E -k -S 数据库地址 -U \"用户名\" -P \"密码\"";cmdrun(exprotanswersql);//将数据导入新表string importanswersql = "bcp 表名 in \"D:\\存储路径.txt\" -c -E -k -S 数据库地址 -d 数据库名 -U \"用户名\" -P \"密码\"";cmdrun(importanswersql);//这里采用分页的方式删除数据,每次删一千万,使用set rowcount不记录日志int deleterow = 10000000;var delcount = Math.Ceiling(Convert.ToDecimal(Convert.ToDecimal(allrow) / deleterow));for (int i = 0; i < delcount; i++){string upsql = "set rowcount " + deleterow + " delete from 表名 where 条件";Logger.Info("【数据迁移】:删除语句:" + upsql + "");DBHelper.NoQuery(upsql);Logger.Info("【数据迁移】:其他日志信息");} }catch (Exception){
throw;}
}
public void cmdrun(string cmd) {
//string str = Console.ReadLine();
System.Diagnostics.Process p = new System.Diagnostics.Process();p.StartInfo.FileName = "cmd.exe";p.StartInfo.UseShellExecute = false; //是否使用操作系统shell启动p.StartInfo.RedirectStandardInput = true;//接受来自调用程序的输入信息p.StartInfo.RedirectStandardOutput = true;//由调用程序获取输出信息p.StartInfo.RedirectStandardError = true;//重定向标准错误输出p.StartInfo.CreateNoWindow = true;//不显示程序窗口p.Start();//启动程序
//向cmd窗口发送输入信息p.StandardInput.WriteLine(cmd + "&exit");
p.StandardInput.AutoFlush = true;//p.StandardInput.WriteLine("exit");//向标准输入写入要执行的命令。这里使用&是批处理命令的符号,表示前面一个命令不管是否执行成功都执行后面(exit)命令,如果不执行exit命令,后面调用ReadToEnd()方法会假死//同类的符号还有&&和||前者表示必须前一个命令执行成功才会执行后面的命令,后者表示必须前一个命令执行失败才会执行后面的命令//获取cmd窗口的输出信息string output = p.StandardOutput.ReadToEnd();p.WaitForExit();//等待程序执行完退出进程p.Close(); Console.WriteLine(output);}#endregion这篇关于sqlserver 数据迁移之bcp的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




