本文主要是介绍恶心的3DMAD数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本来是申请到了数据集,也花钱下载下来了,身边没有linux、Mac os系统,不想转换想找人花钱买得了,私信多家大神均无建树,凑巧别的实验室的苹果一体机遗留在宿舍,实在喜出望外、感激涕零。抱着大mac放回宿舍,开启恶心的3DMAD之旅。
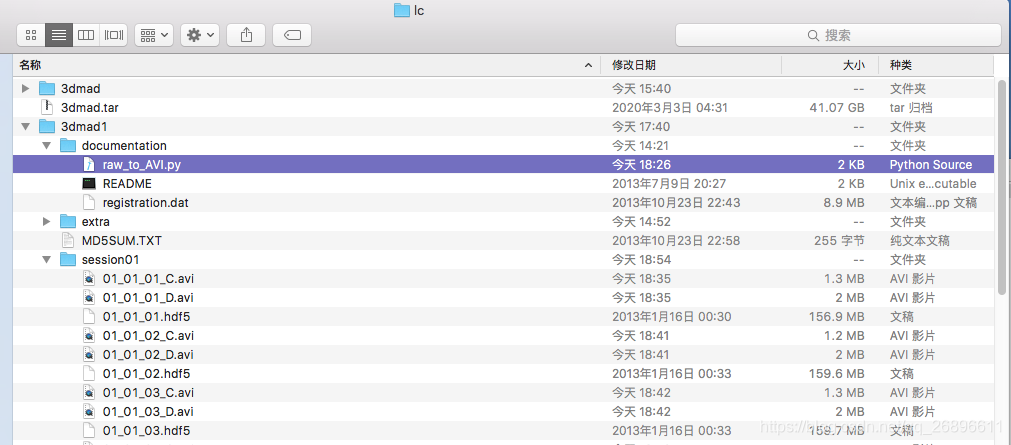
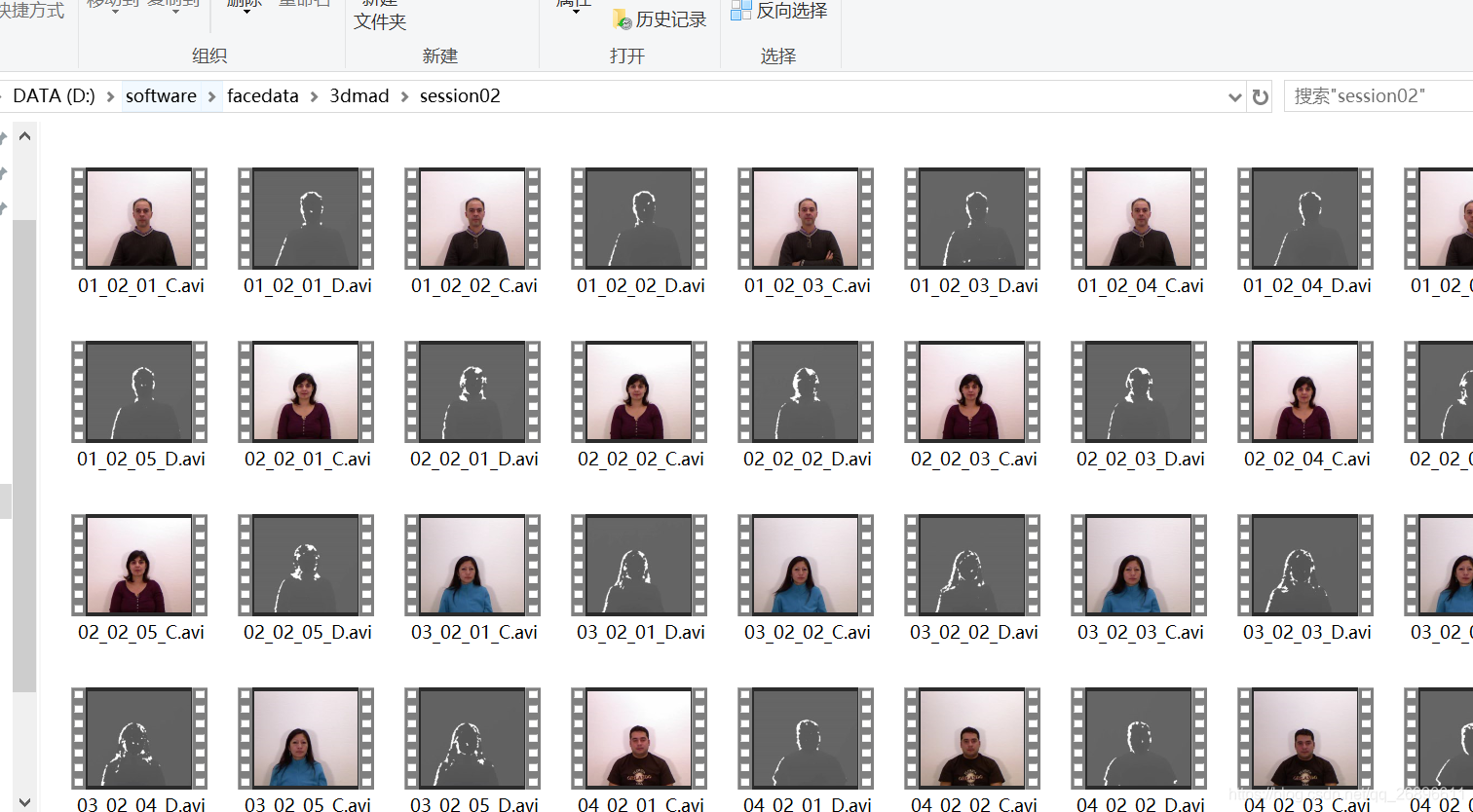
先说一下:共三个session文件夹,session01,session02,session03,只有session03是面具的假人。每个session里面有85个hdf5文件,17个人的5种变化,转换后变成两个avi文件,每个文件就是170个视频共170x3=510个视频,每秒30帧。
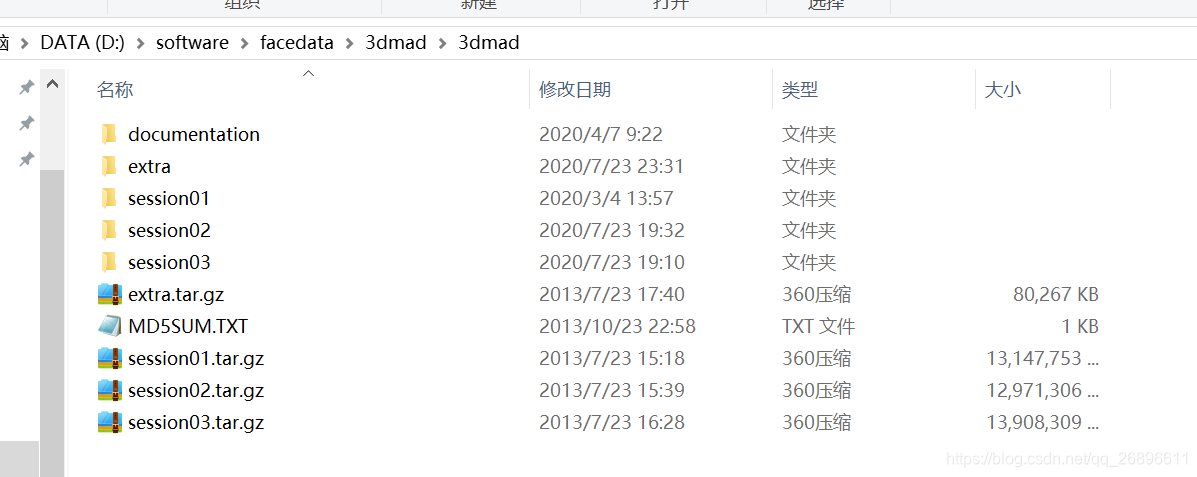
不会使用mac系统啊,各种不适应,不说了
1.第一步还是下载好miniconda吧,安装说明说4.4以上,我下的是这个版本。放到用户文件下就行。
2.安装miniconda
我是参考了这两篇文章
这篇教怎么添加环境变量
vim 是创建并打开一个文件 按i进入编辑模式,编辑好后按esc退出到命令模式,在最下方输入:wq 保存并退出才实现文件的更改
之后关闭终端再重启发现conda -V 就能执行了;
这一篇比较详细
并按他的方法更改了下载路径,编辑模式也是刚刚那样按i进入编辑模式
3.配置bob环境
这一步就是要参考官网给的安装方法了
按官网给出的第二步骤就是检查是否是可以使用conda命令,和版本要求,这一步可以不执行,前面按要求下载了miniconda4.4以上和可以使用conda命令即可

接下来第三步是创建bob环境并下载相应的包
这里不建议完全按这个命令执行,因为我这样试了之后发现要安装很多包,中间还容易因为网络不好导致都没装上,连bob环境也没创建
在这里建议分步骤进行。
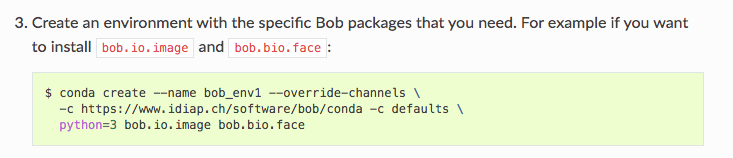
(1)可以先创建一个python3的bob环境
conda create -n bob python=3.6 -y
(2)然后我按这个第四步添加了下载路径
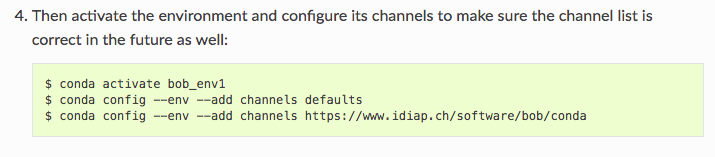
(3)到了下载相应的包了
这边参考这篇文章
不看官网说明了,直接按这篇文章下载相应的安装包分别是
conda install bob.extension bob.blitz bob.core bob.io.base bob.io.image
安装上面这条命令时没有出现较难下载的文件,一切正常
但安装下面这条指令时,安装bob.io.video文件时里面需要ffmpeg文件,下载了好几次往往都在99%出错,实在没办法只能离线安装
离线安装参考这篇文章
conda install bob.ip.draw bob.io.video
这是所有bob包涉及的下载文件地址,里面找到ffmpeg文件
下载需要的是.conda的22m文件。(如果网络正常下载顺利这条步骤可以忽略)

将下载好的.conda ffmpeg文件放置在miniconda3/pkgs 目录下
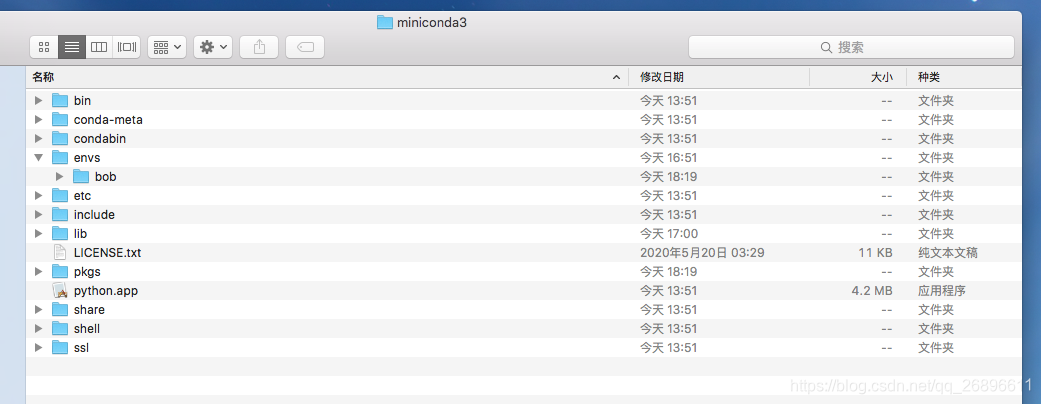
文件夹是后面重新下载生成的,之后需要把这个文件的下载路径添加到pkgs目录下的urls.txt文本下,下载路径在网络出错的时候会提示


我这边的是这种情况

当这一切弄好后,再回到这一步,可以分开安装更安全
再次执行下面这个video命令,发现仍然没有跳过这个安装包,依然很慢的下载,但是最后居然成功了,而且这个video包就只需要这个ffmpeg文件就好了,完成之后,执行下面的draw包就可以完成代码需要的安装包了。
conda install bob.io.video
conda install bob.ip.draw
4.修改raw_to_AVI.py文件的代码
完整代码如下
#!/usr/bin/env python
import os, sys
import numpy
#import bob
import bob.io.base
import bob.ip.draw
import bob.io.videoimport argparseparser = argparse.ArgumentParser(description='Convert HDF5 files to videos for visualization purposes.')
parser.add_argument('path', metavar='path', type=str, help='path to the HDF5 file to be converted')
parser.add_argument('-e', '--eyes', action='store_true', help='mark eye positions in the RGB video')
args = parser.parse_args(sys.argv[1:])try:f = bob.io.base.HDF5File(args.path)Depth = f.read('Depth_Data')Color = f.read('Color_Data')if args.eyes:pos = f.read('Eye_Pos')for i in range(0,Color.shape[0]):bob.ip.draw.cross(Color[i,:,:,:], int(pos[i,0]), int(pos[i,1]), 10, (255,0,0))bob.ip.draw.cross(Color[i,:,:,:], int(pos[i,2]), int(pos[i,3]), 10, (255,0,0))head, tail = os.path.split(args.path)depth_file = head+'/'+tail.split('.')[0]+'_D.avi'color_file = head+'/'+tail.split('.')[0]+'_C.avi'depth_video = bob.io.video.writer(depth_file, Color.shape[-2], Color.shape[-1], 30)color_video = bob.io.video.writer(color_file, Color.shape[-2], Color.shape[-1], 30)D = numpy.right_shift(Depth,3).astype(numpy.uint8)depth_video.append(numpy.concatenate((D,D,D),1))depth_video.close()if Color.shape[1]<3:color_video.append(numpy.concatenate((Color,Color,Color),1))else:color_video.append(Color)color_video.close()print ("Depth video is saved in %s." %depth_file)print ("Color video is saved in %s." %color_file)del f
except IOError:print ("The given file cannot be read.")
5.在bob环境下执行命令即可
命令:python raw_to_AVI.py的路径 需要转换视频的原路径
最后与原视频.hdf5文件保存在一起,得到两个avi文件,一次成功,但我这边85x3共255个文件,要执行255次
看到可以全部转换的教程,看着不清楚不想去弄了,希望以后有人具体点弄了告诉我。
(bob) lch-iMac:3dmad1 lch$ python /Users/lch/lc/3dmad1/documentation/raw_to_AVI.py /Users/lch/lc/3dmad1/session01/01_01_01.hdf5

拜拜了您嘞3dmad
这篇关于恶心的3DMAD数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





