本文主要是介绍联邦学习FL+激励机制+区块链论文阅读4,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
A Contract Theory based Incentive Mechanism for Federated Learning
基于契约理论的联合学习激励机制
存在问题
在这些现有的基于契约的联合学习解决方案中,很少讨论提高模型泛化精度的数据质量,但这其实是模型的基本性能指标。此外,所有这些合同模型只研究逆向选择问题,即FL服务器提供任务和合同供客户根据其类型选择。
本文设计
本文提出一种基于契约理论的FL任务训练模型,以最小化激励预算,前提是客户在每一轮FL培训中都是独立理性的(IR)和激励相容的(IC)。我们通过正式定义两种 客户的私有类型,即数据质量和计算力,设计了一个二维合同模型。为了有效地聚合训练的模型,提出了一种基于契约的聚合器。我们分析了所提出的合同模型的可行和最优合同解决方案。
系统模型

任务请求者向FL服务器发布一个模型任务,服务器为该任务计算一组契约。服务器然后在客户端网络中发布任务,并且客户端可以根据所选择的合同通过注册到任务来选择签署合同。然后,客户端根据其私有数据集努力训练任务模型。在训练合格的本地模型后,客户端可以将模型提交给FL服务器,并且服务器根据相应的合同向客户端付款。最后,服务器根据基于合同的聚合方案聚合提交的模型。
FL客户端在不完整信息下参与FL任务训练,其中FL客户端根据其私有类型私下训练任务模型,FL服务器无法观察客户端的行为或私有类型,但知道私有类型分布。下面,我们首先制定了所提出的契约,然后指定了客户端和服务器的效用函数,最后介绍了基于契约的聚合的设计。
(这个文章的一个前提是基于数据覆盖质量的分类,可以先看一下这个部分,在确定分类后,每一类的契约,训练意愿,奖励,聚合权重是相同的)
基于契约理论的激励方案
契约的提出
假设有I类客户的数据覆盖质量类型按升序排序:θ1≤…≤θi≤…≤θI。对于每一次FL迭代,FL服务器需要提出一个契约集以指定每种客户端类型的客户端奖励和注册费之间的关系,
![]()
其中fi是第i种类型的客户端接受任务的注册费,而Ri(fi)是相应的奖励。fi旨在接收契约之前确保理性客户的加入,如果客户无法执行任务则不会参与。
然后,服务器在客户端之间广播契约,每个客户端根据其类型签署契约。然后,客户根据其本地数据开始训练模型,并最终在时间要求内提交训练后的模型。服务器对提交的模型的泛化精度进行测试。如果模型达到相应的泛化精Mi而通过测试,则客户将获得Rifi奖励,否则无其他奖励。对于未获得奖励的客户,其注册费将不予退还,并作为客户违约金。
数据覆盖质量
d维特征空间D=是一个单位空间,其子空间A∈D, μ(A)表示D中的随机样本被A覆盖的概率。当A=D, μ(A)=1。
具有一定的半径є,由样本![]() 组成的数据集A的覆盖为
组成的数据集A的覆盖为
![]()
B(xi,є)是中心xi半径є的开放球空间。假设空间是欧几里得空间,є∈[0,d]。本地数据集A的数据覆盖质量 由θ(A)用来衡量作为预期覆盖
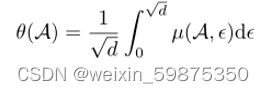
由Θ=![]() 表示数据覆盖质量的具体集合,其中
表示数据覆盖质量的具体集合,其中![]() 属于i类。
属于i类。
训练意愿
客户的训练意愿,由e∈[0,1]表示,是客户在任务训练中付出努力的程度(文中无取值或计算)
客户的培训成本取决于培训意愿(c表示给定任务培训环境中的单位成本)
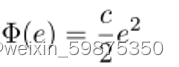
我们将第i种质量类型的客户的培训意愿表示为ei。
客户效用
根据其二维私有信息θi,ei ,第i类客户端的成本为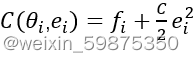
如果训练模型通过泛化测试基准Mi,则客户端将获得Ri(fi)奖励,而通过测试的概率取决于数据覆盖质量和训练意愿。故客户效用为
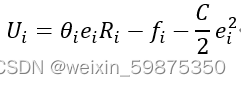
服务器效用
类型i客户上传的本地模型将为FL服务器带来收入G(Mi),满足G'>0,G''>0. 因此,服务器在类型i中注册客户端的效用是
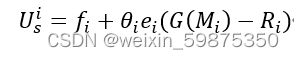
给出客户的类型分布{βi} , i∈{1…I} 以及 , 服务器效用为
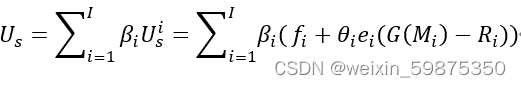
契约优化问题
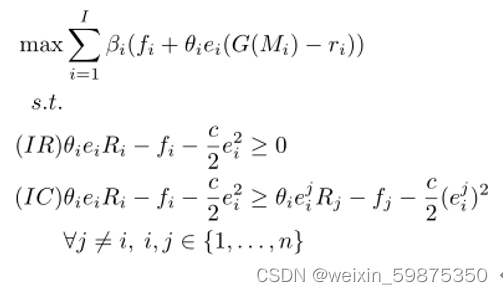
基于契约的模型聚合对于一组提交的模型,服务器应基于其选择的契约聚合模型,以获得更好的模型泛化性能。假设服务器在一轮中支付的总奖励为Rtotal,则根据等式(9)计算为客户端在类型i中训练的模型分配的权重。
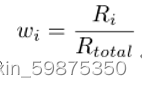
这篇关于联邦学习FL+激励机制+区块链论文阅读4的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








