本文主要是介绍项目实战----河豚快充宝,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一. 项目介绍
本项目是采用SpringBoot、MongoDB、Redis等核心组件开发的共享充电宝微信小程序。
实现了模拟手机绑定、支付押金、身份验证、搜索附近充电宝等功能
二.用到的关键技术
数据库采用:MongoDB(可对地理位置进行索引2Dsphere索引,用于存储和查找球面上的点)
MongoDB是一个基于分布式文件存储的数据库。具有高性能、易部署、易使用,存储数据非常方便等特点。它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
与SpringBoot整合时,通过已经封装好的dao MongoTemplate 来Query 实现增删改查等功能,不需要在写dao层和sql语句
删除:Query query = new Query(Criteria.where("id").is(id)); mongoTemplate.remove(query, User.class);
增加:mongoTemplate.save(user);
修改:Query query = new Query(Criteria.where("id").is(user.getId()));
Update update = new Update().set("userName", user.getUserName()).set("password", user.getPassword());
mongoTemplate.updateFirst(query, update, User.class);
查询:Query query = new Query(Criteria.where("userName").is(userName));
return mongoTemplate.findOne(query, User.class);
缓存功能采用:Redis
redis是一个非关系型的数据库(not-only-sql即nosql),以键值对的方式存储数据,将数据存放在内存中,存取速度快,但是对持久化的支持不够好,所以redis一般配合关系型数据库使用,redis可以做分布式缓存,用在数据量大,高并发的情况下.redis通过很多命令进行操作,而且redis不适合保存内容大的数据。
本项目中使用redis作为短信验证码的缓存,当用户点击获取验证码时,后台自动生成一个4位随机数作为验证码
(int)((Math.random()*9+1)*1000)+"";Math.random()为double类型0.0到1.0的随机数。之后将验证码通过腾讯云的短信API发送给相应的手机号(这里由于需要小程序上线才能使用,因此模拟一下),发送成功后将手机号作为key,验证码作为value存储到redis中,SpringBoot有已经写好的dao层直接调用即可
stringRedisTemplate.opsForValue().set(phoneNum, code,300,TimeUnit.SECONDS);并设置过期时间
注意redis的key过期淘汰策略:
- 被动删除:当读/写一个已经过期的key时,会触发惰性删除策略,直接删除掉这个过期key
- 主动删除:由于惰性删除策略无法保证冷数据被及时删掉,所以Redis会定期主动淘汰一批已过期的key
- 当前已用内存超过maxmemory限定时,触发主动清理策略
项目的后端框架采用:SpringBoot:是 Spring 开源组织下的子项目,是 Spring 组件一站式解决方案,主要是简化了使用 Spring 的难度,简省了繁重的配置,提供了各种启动器,开发者能快速上手
使用 Spring Boot 有什么好处
回顾我们之前的 SSM 项目,搭建过程还是比较繁琐的,需要:
- 1)配置 web.xml,加载 spring 和 spring mvc
- 2)配置数据库连接、配置日志文件
- 3)配置加载配置文件的读取,开启注解
- 4)配置mapper文件
- .....
而使用 Spring Boot 来开发项目则只需要非常少的几个配置就可以搭建起来一个 Web 项目,并且利用 IDEA 可以自动生成生成,这简直是太爽了...
- 划重点:简单、快速、方便地搭建项目;对主流开发框架的无配置集成;极大提高了开发、部署效率。
三.难点创新点
(1)查找附近500米的充电宝位置,并且随着中心点的位置移动,自动显示500米内充电宝位置。
解决方法:基于MongoDB 2dSphere索引查找最近的点。MongoDB的地理空间索引。
地理空间索引采用的时geohash 算法:用一个字符串(数字和字母组成的)表示经度和纬度两个坐标。geohash 表示的并不是一个点,而是一个矩形区域,表示坐标位置附近的区域。

Geohash的最简单的解释就是:将一个经纬度信息,转换成一个可以排序,可以比较的字符串编码
(1)纬度转换:39.92324转为1011 1000 1100 0111 1001。
首先将纬度范围(-90, 90)平分成两个区间(-90,0)、(0, 90),如果目标纬度位于前一个区间,则编码为0,否则编码为1。
由于39.92324属于(0, 90),所以取编码为1。
然后再将(0, 90)分成 (0, 45), (45, 90)两个区间,而39.92324位于(0, 45),所以编码为0。
以此类推,直到精度符合要求为止,得到纬度编码为1011 1000 1100 0111 1001。
| 纬度范围 | 划分区间0 | 划分区间1 | 39.92324所属区间 |
| (-90, 90) | (-90, 0.0) | (0.0, 90) | 1 |
| (0.0, 90) | (0.0, 45.0) | (45.0, 90) | 0 |
| (0.0, 45.0) | (0.0, 22.5) | (22.5, 45.0) | 1 |
| (22.5, 45.0) | (22.5, 33.75) | (33.75, 45.0) | 1 |
| (33.75, 45.0) | (33.75, 39.375) | (39.375, 45.0) | 1 |
| (39.375, 45.0) | (39.375, 42.1875) | (42.1875, 45.0) | 0 |
| (39.375, 42.1875) | (39.375, 40.7812) | (40.7812, 42.1875) | 0 |
| (39.375, 40.7812) | (39.375, 40.0781) | (40.0781, 40.7812) | 0 |
| (39.375, 40.0781) | (39.375, 39.7265) | (39.7265, 40.0781) | 1 |
| (39.7265, 40.0781) | (39.7265, 39.9023) | (39.9023, 40.0781) | 1 |
| (39.9023, 40.0781) | (39.9023, 39.9902) | (39.9902, 40.0781) | 0 |
| (39.9023, 39.9902) | (39.9023, 39.9462) | (39.9462, 39.9902) | 0 |
| (39.9023, 39.9462) | (39.9023, 39.9243) | (39.9243, 39.9462) | 0 |
| (39.9023, 39.9243) | (39.9023, 39.9133) | (39.9133, 39.9243) | 1 |
| (39.9133, 39.9243) | (39.9133, 39.9188) | (39.9188, 39.9243) | 1 |
| (39.9188, 39.9243) | (39.9188, 39.9215) | (39.9215, 39.9243) | 1 |
(2)
经度也用同样的算法,对(-180, 180)依次细分,得到116.3906的编码为1101 0010 1100 0100 0100。
| 经度范围 | 划分区间0 | 划分区间1 | 116.3906所属区间 |
| (-180, 180) | (-180, 0.0) | (0.0, 180) | 1 |
| (0.0, 180) | (0.0, 90.0) | (90.0, 180) | 1 |
| (90.0, 180) | (90.0, 135.0) | (135.0, 180) | 0 |
| (90.0, 135.0) | (90.0, 112.5) | (112.5, 135.0) | 1 |
| (112.5, 135.0) | (112.5, 123.75) | (123.75, 135.0) | 0 |
| (112.5, 123.75) | (112.5, 118.125) | (118.125, 123.75) | 0 |
| (112.5, 118.125) | (112.5, 115.312) | (115.312, 118.125) | 1 |
| (115.312, 118.125) | (115.312, 116.718) | (116.718, 118.125) | 0 |
| (115.312, 116.718) | (115.312, 116.015) | (116.015, 116.718) | 1 |
| (116.015, 116.718) | (116.015, 116.367) | (116.367, 116.718) | 1 |
| (116.367, 116.718) | (116.367, 116.542) | (116.542, 116.718) | 0 |
| (116.367, 116.542) | (116.367, 116.455) | (116.455, 116.542) | 0 |
| (116.367, 116.455) | (116.367, 116.411) | (116.411, 116.455) | 0 |
| (116.367, 116.411) | (116.367, 116.389) | (116.389, 116.411) | 1 |
| (116.389, 116.411) | (116.389, 116.400) | (116.400, 116.411) | 0 |
| (116.389, 116.400) | (116.389, 116.394) | (116.394, 116.400) | 0 |
接下来将经度和纬度的编码合并,奇数位是纬度,偶数位是经度,得到编码 11100 11101 00100 01111 00000 01101 01011 00001。
最后,用0-9、b-z(去掉a, i, l, o)这32个字母进行base32编码,得到(39.92324, 116.3906)的编码为wx4g0ec1。
| 十进制 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| base32 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | b | c | d | e | f | g |
| 十进制 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| base32 | h | j | k | m | n | p | q | r | s | t | u | v | w | x | y | z |
注意:由于编码方式形成的是"Z"字形曲线,这样就会存在拐点,说明编码越接近不一定地理位置越近,地理位置越近,编发不一定越近。因此不能完全根据编码决定是否接近。

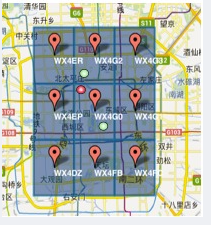
这样就会存在以下的特点,假如所在位置为红色节点,绿色节点为充电宝的位置,由于上面绿色的与所在位置不在一个区域里,而下面绿色节点与红色节点在一个区域里,这样如果完全按照区域找的话,就会找到更远处的节点。
解决办法是:除了将本地区域的节点查找到,还要将区域周围的8个区域进行查询,具体实现步骤如下:
- 坐标值转化为GeoHash编码值
- 根据当前区域的GeoHash,推算出周围8个方位区域块的的GeoHash值。
- 将这8个区域块中所有节点进行储存,并且一一计算它们到当前坐标的距离,并且计算出最短距离的点。
- 考虑存储结构,以及算法实现。
NearQuery nearQuery = NearQuery.near(longitude, latitude).maxDistance(0.2, Metrics.KILOMETERS) .query(new Query(Criteria.where("status").is(0)).limit(20));
GeoResults<Kcb> geoResults=mongoTemplate.geoNear(nearQuery, Kcb.class);geoResults.getContent();
这篇关于项目实战----河豚快充宝的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






