本文主要是介绍PCT: Point Cloud Transformer论文阅读及理解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
PCT: Point Cloud Transformer
Abstract
点云数据的不规则和无序性是的用神经网络处理变得很困难。PCT是基于Transformer。
为了更好的获得点云局部的联系,采用了最远点采样和最邻近搜索。
Introduction
Transformer是一个编码器-解码器结构,包含了三个主要的模块:输入嵌入、位置编码、自注意。自注意模块是核心模块,用于根据输入的全文信息形成细化后的特征。
Transformer所有的操作都是并行且与顺序无关的。理论上来说,Transformer操作能够替换卷积操作,且有更好的通用性。
PCT关键思想是利用Transformer固有的顺序不变性,无需定义点云数据的顺序,利用注意力机制进行特征学习。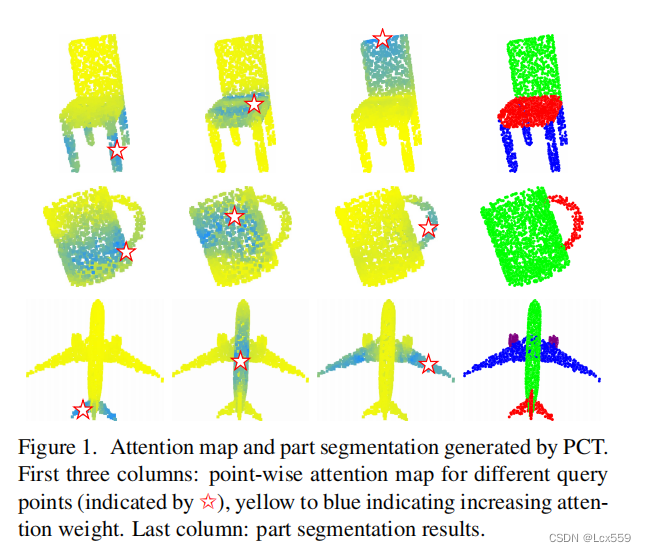
由PCT生成的注意力图和部分分割。前三列表示不同查询点对应的点的注意力映射,有黄色到蓝色注意力权重加深。最后一列表示了分割的结果。
PCT框架做了一些改变:
基于坐标的输入点输入模块:在Transformer对于翻译任务中时,编码器对单词所在的位置进行了编码,获得了位置信息,而点云时无序性的。在PCT框架中,将位置位置编码和输入嵌入融合成一个基于坐标的嵌入模块。
优化的偏移注意模块:对于原有的自我注意的有效升级,通过将原有的注意力特征替换为自我主义模块和注意特征之间的偏移量。
领域嵌入模型:注意力机制可以高效的获取全局特征,但是容易忽略局部的集合特征,这对于点云的学习时很重要的。为了解决这个问题,提出了领域嵌入模型。
贡献:
- 提出了基于Transformer的点云学习框架PCT
- 提出了带有隐式Laplace算子的偏移注意和归一化细化,具有固定的置换不变性。
- 在具有显示局部上下文增强的PCT在形状分类、零件分割和正常估计任务方面取得了先进的性能
Transformer for Point Cloud Representation
Point Cloud Processing with PCT
**Encoder.**PCT的完整结构如下图: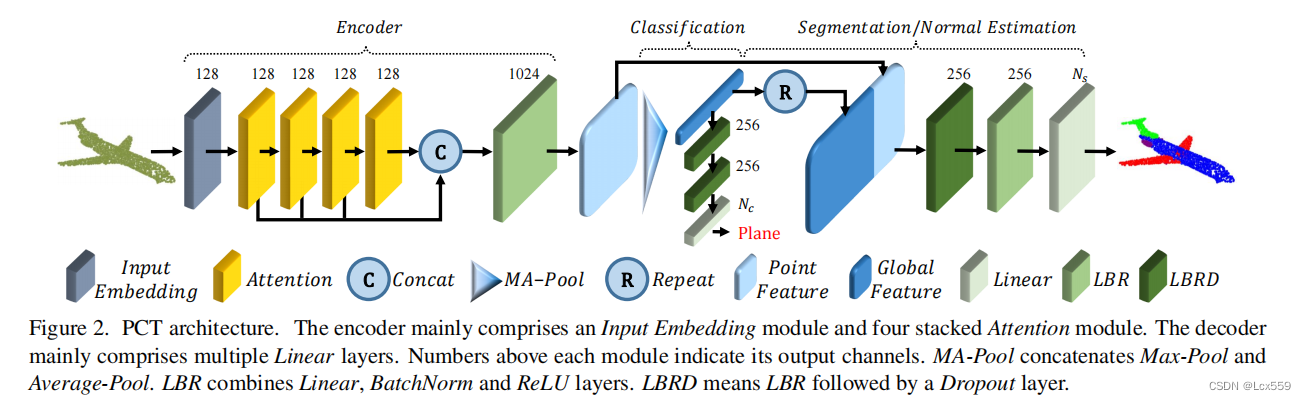
PCT的目标是将输入的点云转化成一个高位的特征向量空间,可以表示为点之间语义的亲和性。PCT首先间输入坐标嵌入于一个新的特征空间中,随后嵌入的特征被输入四个堆叠的注意模块,对每个点的语义丰富和区别的表示进行学习,同故宫一个线形层形成输出特征。
输入一个点云P,具有N个点,每个点有d维特征向量,首先经过输入嵌入模块输出de维的特征向量Fe,再通过特征维度将每个注意层的输出连接起来进行线性变换输出do维的Fo特征向量。: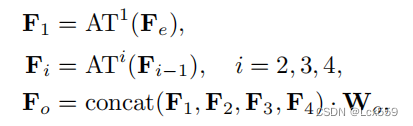
ATi代表了第i个注意层,注意层有着和输入一样的输出,Wo时线性层的权重。
为了提取全局的特征向量Fg,我们将两个池化层的输出连接了起来。
**classification.**将全局特征向量Fg放入分类解码器进行分类,分类解码器包含了两个前馈神经网络LBRs(线形层,batchnorm和ReLU),设置dropout为0.5,以一个线性层去预测最终的得分最为结尾。
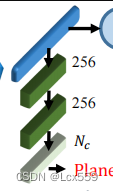
Segmentation:点云分割任务中,首先将全局特征Fg和第一个线性层输出的特征Fo结合起来,为了学习各类目标的通用模型,将目标目录向量编写为64维的独热码特征,把这个特征和全局特征连接起来,遵循绝大多数的其他点云分割网络。
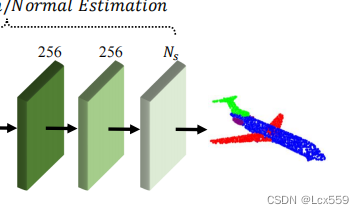
与分类网络基本一致,只在第一层LBR进行dropout。
Na¨ıve PCT‘
首先考虑 naive的点嵌入,点嵌入的目的时将语义上近似的点在嵌入空间更加靠近。 具体来说,首先嵌入一个点云P到de维的空间Fe中,使用一个共享的神经网络,包含类两个LBR层,每层都输出de维的向量。通常设置de=128,通常只是用点的坐标作为输入特征,即输入特征维度dp=3,但是也可以加入法线作为输入特征。
对于实现PCT,采用了自注意机制(SA)作为初始的Transformer,用于计算数据序列中不同项的亲密关系,SA层的结构如下图虚线所示: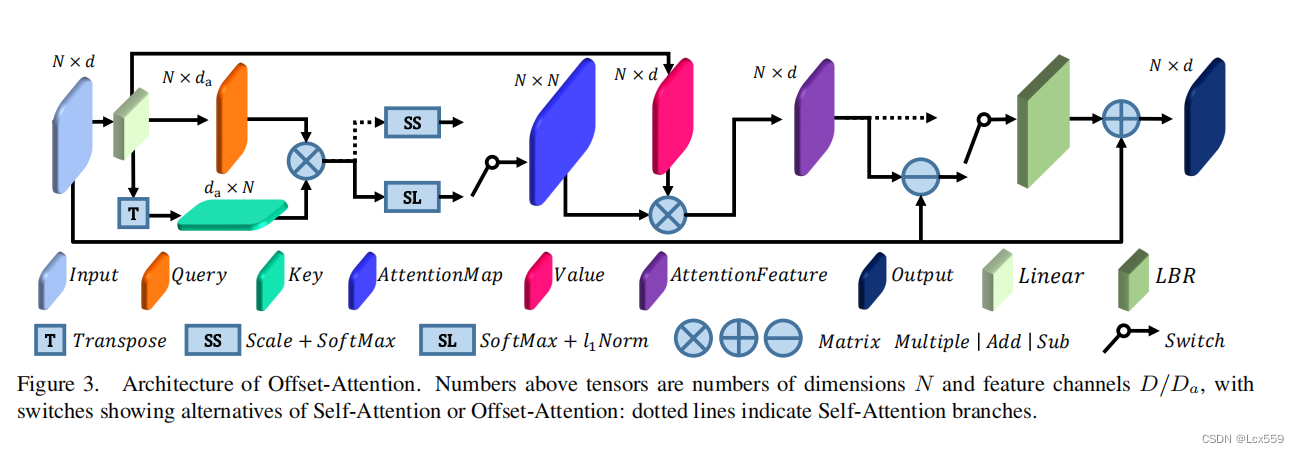
Fin作为de维的输入特征向量,用于得到Q、K、V矩阵,过程如下: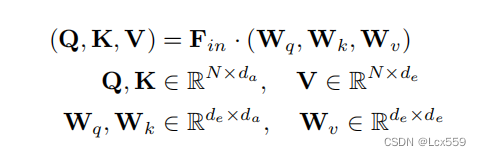
Wq、Wk、Wv时共享的可学习的线性变换,da时Q和K向量的维度,da一般不等于de,在这里设置维da=de/4
首先可以通过Q和K矩阵计算注意力权重: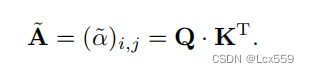
将这些权值进行归一标准化输出(在figure中用SS表示)得到A=(α)i,j: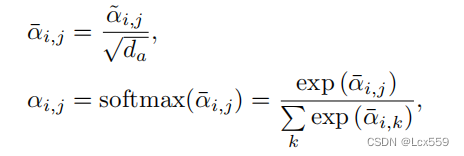
自注意输出的特征Fsa时使用对应注意权重V向量的和:![]()
图中部分:
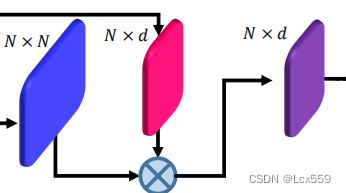
Q、K、V矩阵都时输入Fin矩阵决定,他们都是与顺序无关的。且softmax和加权都是与排序无关的算子。因此整个自注意过程都是与顺序无关的,十分适合点云的特征。
最后Fout由Fsa和Fin经过LBR网络维SA层提供输出特征Fout: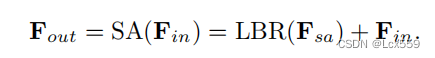
Offset-Attention
在Transformer中将自主意(SA)模块替换为offset-attention(OA)偏移注意模块,用以增强PCT。
在figure3中显示,偏移注意层通过元素相减计算自注意特征和输入特征的偏移。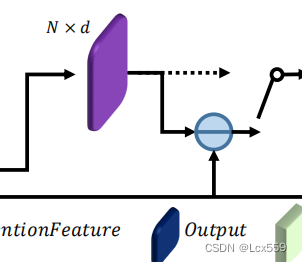
在网络中,使用偏移量Fin-Fsa替代了原有的Fsa,即公式![]()
需要改变为: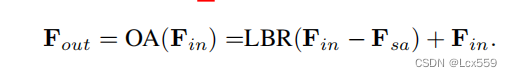
Fin-Fsa的过程类似于拉普拉斯算子,从公式中可以推出: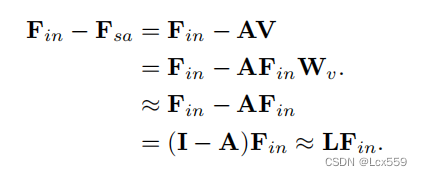
Wi因为时Laplace层的权重矩阵,因此被忽视?(这里有点不懂,评论区有大佬帮忙解释一下吗)
在PCT的增强版本种,softmax层也被改为: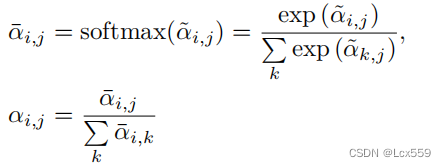
这里使用softmax作为第一层,而1阶范数作为第二维来标准化注意力映射。这样提高了注意力权重,减少了噪音的影响。
Neighbor Embedding for Augmented Local Feature Representation
带有点嵌入的PCT是一种提取全局的特征有效网络,但是忽略了全局的领域信息。利用Pointnet++和DGCNN的思想,设计了一种局部邻域聚合策略,以增强PCT的局部特征提取能力。结构如下: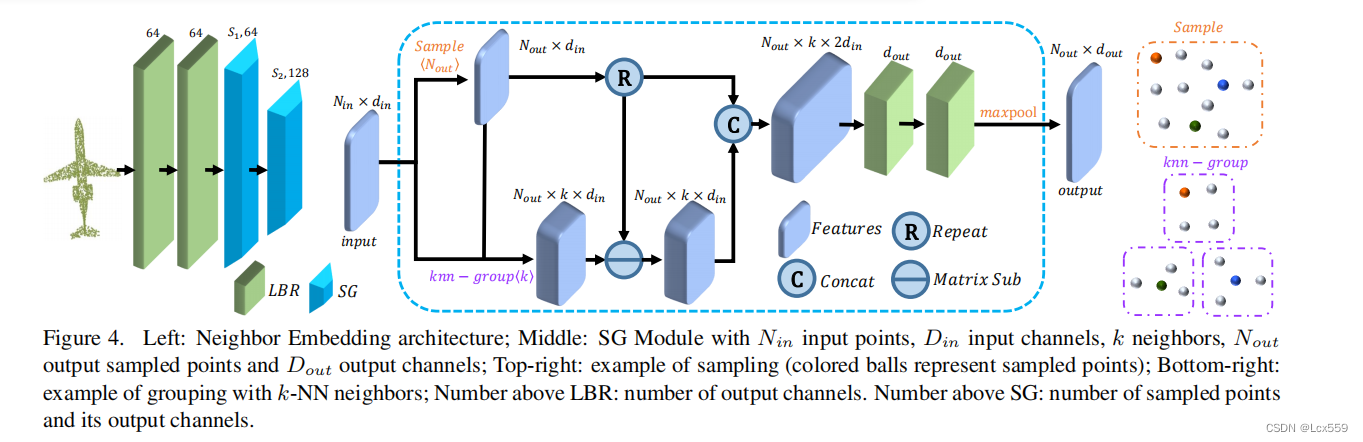
邻域嵌入模块包含了两个LBR层和两个SG层(采样和分组),LBR层作为嵌入的基点,在特征聚集的过程种使用两个SG层来扩大接受域。在采样过程种,SG层利用欧式距离聚合了由k-NN搜索分组的每个点的局部邻域特征。
对于一个具有N个点的点云P,特征向量为F,子采样点云Ps,具有Ns个点,对应的特征向量为Fs。首先使用最远点采样算法采样出Ps。对于每个采样点,令knn(p,P)成为在P种k个最近的邻域。则可以计算出输出特征向量Fs: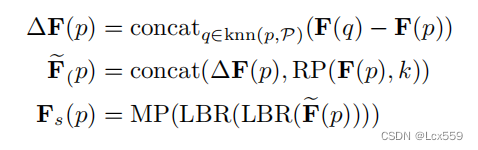
其中,F(p)时输入对点p的特征,Fs(p)时输出采样点的特征,MP时最大池化采样,RP(x,k)重复x向量k次以形成一个矩阵。
这篇关于PCT: Point Cloud Transformer论文阅读及理解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






