本文主要是介绍Python通过natcap.invest库调用InVEST模型批处理数据(Carbon Storage and Sequestration模块),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
InVEST(Integrated Valuation of Ecosystem Servicesand Tradeoffs)生态系统服务和权衡的综合评估模型,旨在通过模拟不同土地覆被情景下生态系统物质量和价值量的变化。它提供了多种生态系统服务功能评估,包括了淡水生态系统评估、海洋生态系统评估和陆地生态系统评估三大板块。其中陆地生态系统评估包括了生物多样性、碳储量、授粉等多种模型。
文章目录
- ——0——说在前面——
- ——1——配置环境——
- ——2——编写脚本——
——0——说在前面——
InVEST模型有专门的处理软件,可以在官网直接下载——https://naturalcapitalproject.stanford.edu/software/invest
不过,当要处理的数据量有些大时,用软件处理就十分低效不便了。这时可以用Python来批量处理。官网有相应的包下载及版本配置要求——https://invest.readthedocs.io/en/latest/scripting.html
在下载相应的包以及配置python环境的的过程可能会遇到一些报错问题,这里,我将我成功配置好的处理环境做个记录,供参考。
——1——配置环境——
- 使用Anaconda创建一个Python3.8 的环境,
conda create -n invest[虚拟环境名称] python=3.8- 安装运行 Invest 所需的软件包。下面是官网上给出的指定版本要求的依赖包,
复制下来,找一个文件目录新建一个文本文档rqment.txt,粘贴上去。这里注意,GDAL下载时可能会出现失败的情况,因此注释掉,另外通过.whl的方式离线安装。
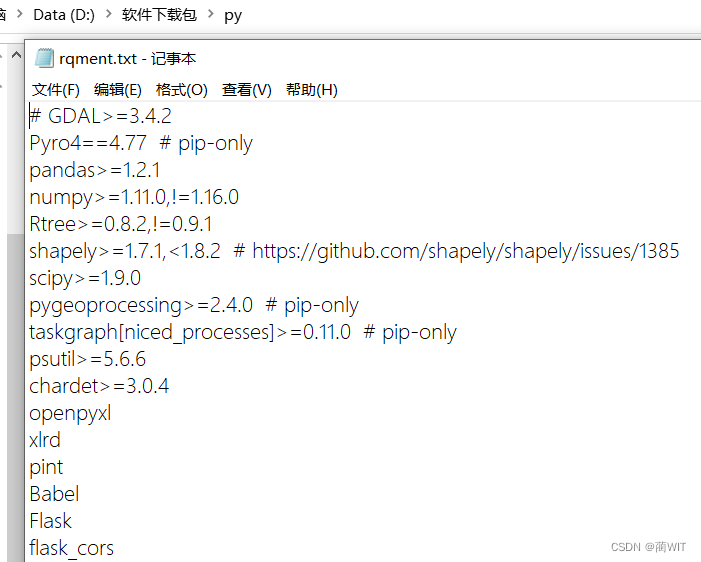
# GDAL>=3.4.2
Pyro4==4.77 # pip-only
pandas>=1.2.1
numpy>=1.11.0,!=1.16.0
Rtree>=0.8.2,!=0.9.1
shapely>=1.7.1,<1.8.2 # https://github.com/shapely/shapely/issues/1385
scipy>=1.9.0
pygeoprocessing>=2.4.0 # pip-only
taskgraph[niced_processes]>=0.11.0 # pip-only
psutil>=5.6.6
chardet>=3.0.4
openpyxl
xlrd
pint
Babel
Flask
flask_cors
-
在命令行中进入rqment.txt文件所在目录,再进入执行
activate invest创建好的python3.8的环境,然后通过镜像批量下载文本里的所有依赖包 -
pip install -r rqment.txt -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn -
下载GDAL包,在下载python包的网站上——https://www.lfd.uci.edu/~gohlke/pythonlibs/#gdal找到python3.8对应的GDAL的 whl下载包,注意,版本仍要满足GDAL>=3.4.2。这里我下载的是
GDAL‑3.4.3‑cp38‑cp38‑win_amd64.whl -
将下载好的 whl文件复制到python3.8环境的下载第三方包的目录下,一般在如下路径中
D:\anaconda3\envs\invest(定义的环境名)\Lib\site-packages,在命令行中进入该环境,执行下载命令 -
pip install GDAL‑3.4.3‑cp38‑cp38‑win_amd64.whl
🆗
依赖包都安装好了之后,通过pip install natcap.invest就可以安装InVEST Python Package了。
如果安装失败,可以在https://pypi.org/project/natcap.invest/#files里下载对应版本的 whl下载包,和GDAL包一样通过本地离线方式安装。
这里我下载的是natcap.invest-3.13.0-cp38-cp38-win_amd64.whl
🆗
把natcap.invest及其依赖包都安装好了后,就可以写python脚本去调用InVEST模型批处理数据了。
——2——编写脚本——
natcap.invest 包的使用很简单,代码也很简洁——传输数据参数,执行功能计算模块🆗
官网API参考文档——https://invest.readthedocs.io/en/latest/api.html
InVEST模型快速入门(参数说明)——https://invest.readthedocs.io/en/latest/models.html
使用示例:
调用Carbon Storage and Sequestration固碳模块计算碳储量
固碳模块的介绍:https://storage.googleapis.com/releases.naturalcapitalproject.org/invest-userguide/latest/zh/carbonstorage.html#id4
InVEST模型 | 软件安装与固碳模块的使用
这里只输入下面这四个参数来计算
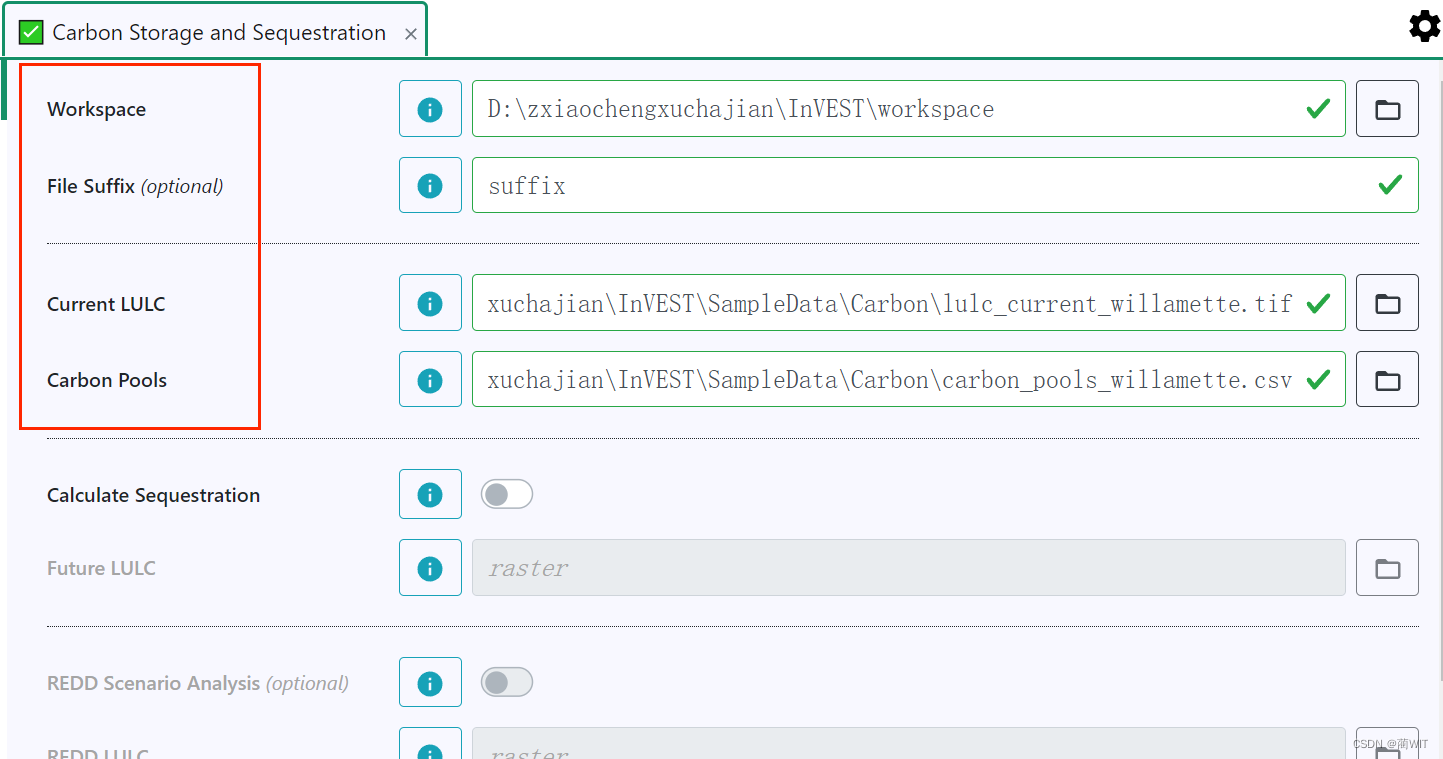
import natcap.invest.carbonargs = {'workspace_dir': 'D:\\InVEST\\workspace\\my_py', # 目录的路径,该目录将在计算过程中写入输出和其他临时文件。'results_suffix': "results_suffix", # 附加到任何输出文件名'lulc_cur_path': "D:\\InVEST\\SampleData\\Carbon\\lulc_current_willamette.tif", # 目前的碳储量# 'calc_sequestration': True,# 'lulc_fut_path': "",# 'do_redd': True,# 'lulc_redd_path': "",'carbon_pools_path': "D:\\InVEST\\SampleData\\Carbon\\carbon_pools_willamette.csv", # CSV 或索引碳的路径 存储到LULC代码# 'lulc_cur_year': "",# 'lulc_fut_year': "",# 'do_valuation': "",# 'price_per_metric_ton_of_c':"",# 'discount_rate': "",# 'rate_change': 1.0,
}
natcap.invest.carbon.execute(args)
上面代码只能处理指定路径下的一条碳储量数据,当指定路径下有上百条数据时,我们可以结合 os库 读取所有文件再批量输入参数、批量输出结果。

import os
import natcap.invest.carbonpath = "D:\\CCI-LC文件夹"
fileList = os.listdir(path)
for name in fileList:# print(name)# 创建与数据同名文件夹dirName = os.path.splitext(name)[0]if not os.path.exists(dirName):os.mkdir("D:\\workspace输出工作空间"+'./'+dirName)luPath = "D:\\CCI-LC文件夹\\"+namewDir = 'D:\\\workspace\\'+dirNameargs = {'workspace_dir': wDir,'results_suffix': dirName,'lulc_cur_path': luPath,'carbon_pools_path': "D:\\carbon_pools.csv",}natcap.invest.carbon.execute(args)print(dirName) # 输出计算完成了的数据文件名,方便在控制台查看执行进程
输出结果(其一)目录结构:

OK!
其他功能模块的计算也类似,参考官网文档学习使用就OK!
这篇关于Python通过natcap.invest库调用InVEST模型批处理数据(Carbon Storage and Sequestration模块)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





