本文主要是介绍高中数学学计算机编码部分,写给中学生的算法入门:学代码之前看这篇就够了...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原标题:写给中学生的算法入门:学代码之前看这篇就够了
导读:本文内容主要源自德语大学中发起的科普活动,初衷是让高中生领会算法和计算机科学的奇妙与魅力。阅读本文不需要任何关于算法和计算的预备知识。我们希望不仅学生,而且包括希望了解迷人的算法世界的成年人都能从本书中得到启发与乐趣。
作者:Thomas Seidl, Jost Enderle, Wolfgang P. Kowalk, Berthold Vöcking
本文摘编自《无处不在的算法》,如需转载请联系我们

00 算法的应用
最近几十年来许多技术创新和成果都依赖于算法思想,这些成果广泛应用于科学、医药、生产、物流、交通、通信、娱乐等领域。高效的算法使得你的个人电脑得以运行新一代的游戏,这些复杂的游戏在几年前可能都难以想象。
更重要的是这些算法为一些重大科学突破提供了基础。例如,人类基因组图谱解码得以实现与新算法的发明是分不开的,这些算法能将计算速度提高几个数量级。
算法告诉计算机如何处理信息,如何执行任务。算法组织数据,使得我们能有效地搜索。如果没有聪明的算法,我们一定会迷失在互联网这个巨大的数据丛林中。
同样,如果没有天才的编码和加密算法,我们也不可能在网络上安全地通信。天气预报与气候变化分析也依靠高效模拟算法。
工厂生产线和物流系统有大量复杂的优化问题,只有奇巧的算法能帮助我们解决。甚至当你利用GPS寻找附近的餐厅或咖啡馆时,也要靠有效的最短路计算才能获得满意的结果。
并非像很多人认为的,只有计算机中才需要算法。在工业机器人、汽车、飞机以及几乎所有家用电器中都包含许多微处理器,它们也都依赖算法才能发挥作用。例如,你的音乐播放器中使用聪明的压缩算法,否则小小的播放器会因为存储量不足而无法使用。
现在的汽车和飞机中有成百上千的微处理器,算法能帮助控制引擎,减少能耗,降低污染。它们还能控制制动器和方向盘,提高稳定性与安全性。不久的将来,微处理器可能完全替代人,实现汽车的全自动驾驶。目前的飞机已经能做到在从起飞到降落的全过程中无须人工干预。
算法领域最大的进步都来自美好的思想,它指引我们更有效地解决计算问题。我们面对的问题绝不局限于狭义的算术计算,还有很多表面上不是那么“数学化”的问题。例如:
如何走出迷宫?
如何分割一张藏宝图让不同的人分别保存,但只有重新拼合才可能找到宝藏?
如何规划路径,用最小成本访问多个地方?
这些问题极具挑战,需要逻辑推理、几何与组合想象力,还需要创造力才能解决。这些就是设计算法所需要的主要能力。

01 二分搜索
我新买的Nelly的唱片哪儿去啦?我那专横的妹妹Linda有整洁癖,肯定是她将唱片又插进唱片架上了。我告诉她新买的唱片别插上去。这下我得在架子上的500张唱片中一张一张地找了,这该找到什么时候啊!
不过,走运的话也可能并不需要查看所有唱片就碰到了。但最坏的情况是Linda又把唱片借给朋友了,那得查完所有唱片才知道不在这里了,然后只好去听广播啦。
找找看吧!Aaliyah,AC/DC,Alicia Keys……嗯,Linda好像按字母顺序给唱片排过序了。这样的话我找Nelly的唱片就容易多了。
我先在中间试试。Kelly Family,这太偏左了,必须往右边找。Rachmaninov,这又太偏右了,再往左一点儿……Lionel Hampton,右了点儿,但不远了。Nancy Sinatra……Nelly,找到啦!
这倒很快!因为唱片已经排了序,我只要来回跳几次就找到目标了!即使我要的唱片不在架子上,我也能很快发现。不过如果唱片很多,比如说10 000张,那可能得来回跳上几百次吧。我很想知道如何计算次数。图1-1给出了不同搜索方法的示意。
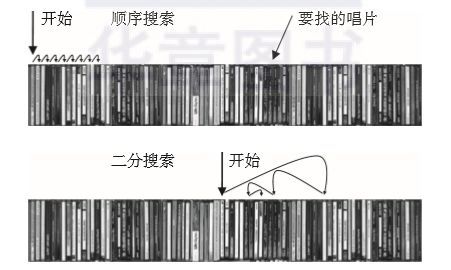
▲图1-1 顺序搜索与二分搜索图示
1. 顺序搜索
Linda从去年开始学习计算机科学;她应该有些书能告诉我答案。我看看,“搜索算法”可能有用。这里说了如何在一个给定集合(这里是唱片)中按照关键字(这里用艺术家的名字)找一个对象。我刚才的做法应该是“顺序搜索”,又叫“线性搜索”。
就像我想的一样,为了找一个关键字,平均得检查一半的唱片。搜索的步数和唱片数成正比,换句话说,唱片数增加一倍,搜索时间也就增加一倍。
2. 二分搜索
我用的第二种技术好像有个特别的名字,叫“二分搜索”。给定要找的关键字以及排好次序的对象列表,搜索从中间那个对象开始,和关键字进行比较。如何中间那个对象就是要找的,搜索就结束了。
否则,按照要找的关键字是小于还是大于当前检查的对象决定该向左还是该向右继续搜索。接下来就是重复上面的过程。
如果找到了搜寻的对象,或者当前可能搜索的区间已经不能再切分了(也就是说如果表中有要找的对象,当前位置就该是目标应该在的位置),搜索就终止。我妹妹的书中有相应的程序代码。
在这段代码中,A表示一个“数组”,也就是由带编号的对象(我们称其为数组的元素)构成的数据列表,编号就像唱片在架子上的位置。例如,数组中第5个元素写为A[5]。
如果我们的架子上放了500张唱片,我们要找的关键字是"Nelly",那就得调用BINARYSEARCH(rack, "Nelly", 1, 500)搜索要找的唱片所在位置。程序执行时,开始的left值为251,right值为375,以此类推。

3. 递归实现
在Linda的书中还有另外一个二分搜索算法。同样的功能为什么需要不同算法呢?书上说第二种算法采用“递归方法”,那又是什么呢?
我再仔细看看……“递归函数是一种利用自身来定义或者调用自己的函数。”求和函数sum就是个例子。函数sum的定义如下:
sum (n) = 1 + 2 + … + n
也就是前n个自然数相加,所以,当n = 4,可得:
sum (4) = 1 + 2 + 3 + 4 = 10
如果我们想计算对于某个n的sum函数值,而且已经知道对于n-1的函数值,那只要再加上n就可以了:
sum (n) = sum (n-1) + n
这样的定义式就称为“递归步”。当要计算对于某个n的sum函数值时,我们还需要一个最小的n对应的函数值,这称为奠基:
sum (1) = 1
按照递归定义,我们现在计算sum函数值的过程如下:
sum (4) = sum (3) + 4
= (sum (2) + 3) + 4
= ((sum (1) + 2) + 3) + 4
= ((1 + 2) + 3) + 4
= 10
二分搜索的递归定义是一样的:函数在函数体中调用自己,而不是反复执行一组操作(那称为循环实现)。

和前面一样,A是要搜索的数组,key是要找的关键字,left和right分别是搜索区域的左右边界。如果我们要在包含500个元素的数组rack中找Nelly,我们采用类似的函数调用BINSEARCHRECURSIVE(rack,"Nelly",1,500)。但这里不再通过程序循环使得搜索区域左右边界逐步靠近,而是直接修改边界值执行递归调用。实际执行的递归调用序列如下:
BINSEARCHRECURSIVE (rack, “Nelly”, 1, 500)
BINSEARCHRECURSIVE (rack, “Nelly”, 251, 500)
BINSEARCHRECURSIVE (rack, “Nelly”, 251, 374)
BINSEARCHRECURSIVE (rack, “Nelly”, 313, 374)
BINSEARCHRECURSIVE (rack, “Nelly”, 344, 374)
...
4. 搜索的步数
至此,我们仍然不知道要找到所需的对象究竟该执行多少搜索步。如果运气好,一步就能找到。反之,如果要找的对象不存在,我们必须来回跳动直至对象应该处于的位置。
这样就需要考虑究竟数组能够被切为两半多少次,或者反过来说,当执行了一定数量的比较操作后,究竟多少元素可以被确定是或者不是目标对象。
假设要找的对象确实在表中,一次比较可以确定2个元素,两次比较可以确定4个元素,三次比较就能确定8个元素。因此执行k次比较操作能够确定2·2·…·2(k次)= 2k个元素。由此可知10次比较可以确定1024个元素,20次比较能确定的元素超过100万个,而30次比较能确定的元素多达10亿个以上。
如果目标对象不在数组中,则需要多比较一次。为了能根据元素个数确定比较次数,我们需要逆运算,也就是2的乘幂的反函数,即“以2为底的对数”,记作log2。一般地说:
假设a = bx,则x = logba
对于以2为底的对数,b = 2:
20 = 1,log2 1 = 0
21 = 2,log2 2 = 1
22 = 4,log2 4 = 2
23 = 8,log2 8 = 3
.
.
..
.
.
210 = 1 024,log2 1 024 = 10
.
.
..
.
.
213 = 8 192,log2 8 192 = 13
214 = 16 384,log2 16 384 = 14
.
.
..
.
.
220 = 1 048 576,log2 1 048 576 = 20
因此,若k次比较操作能确定N(= 2k)个元素,那么对于含N个元素的数组,二分搜索需要执行log2 N = k次比较操作。如果我们的架子上放了10 000张唱片,我们需要比较log2 10 000≈13.29次。因为不可能比较“半次”,需要的次数为14。
要想进一步减少二分搜索需要的步数,可以在搜索过程中不是简单地选择中间元素进行比较,而是尝试在搜索区域内更准确地“猜测”可能的位置。
假设在已排序的唱片中搜索的对象名按字母顺序更靠近区域开始处,例如找Eminem,显然选择前部的某个位置进行比较更好些。反之,要找“Roy Black”,从靠后的地方开始更合理。
若要更好地改进,就得考虑每个字母可能出现的频率,例如首字母是D或S的艺术家通常比首字母是X或Y的更常见。
5. 猜数游戏
今晚我要考考Linda,让她猜1到1000之间的某个数。只要上课没睡觉,她就应该能最多通过10个“是/否”的问题得到结果。(图1-2显示如何只问4个问题就猜出1到16之间的某个数。)
为了避免反复问那些“是小于某个数吗?”或者“是大于某个数吗?”那样乏味的问题,我们可以选择问“是奇数吗?”或“是偶数吗?”。因为一个回答就可以让我们排除一半的可能性。
类似的问题包括“十(百)位数是奇(偶)数吗?”,像这样的问题同样可以使搜索空间(大致)缩小一半。不过要确认考虑了所有可能的数,我们还得回到通常采用的减半方法(那些已经被排除的数实际上已考虑在内)。
如果采用二进制表示数,这个过程甚至会更简单。十进制系统是用“10的乘幂的和”的形式表示数,例如:
107 = 1·102 + 0·101 + 7·100
= 1·100 + 0·10 + 7·1
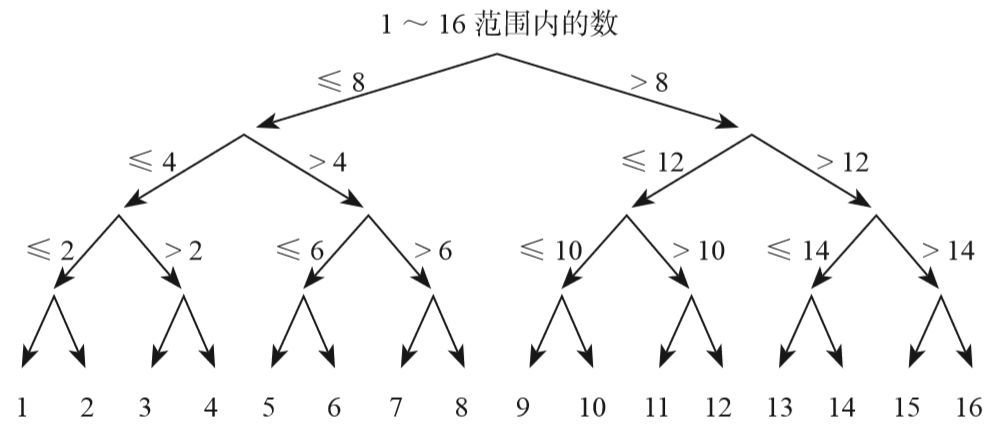
▲图1-2 在1~16范围内猜出某个数的图示
而在二进制系统中数是用“2的乘幂的和”的形式表示的:
107 = 1·26 + 1·25 + 0·24 + 1·23 + 0·22 + 1·21 + 1·20
= 1·64 + 1·32 + 0·16 + 1·8 + 0·4 + 1·2 + 1·1
因此107的二进制表示为1101011。要猜出一个二进制表示的数只要知道它最多多少位就足够了。位数用以2为底的对数很容易计算。如果猜一个1到1000之间的数,可以计算如下:
log2 1000≈9.97(向上取整)
也就是说共有10位。因此问10个问题足够了:“第1位数是1吗?”“第2位数是1吗?”“第3位数是1吗?”等等。最后所有位都知道了还必须转换为十进制数,用一个掌上的计算器就能解决了。
02 插入排序
我们要把书架上所有的书按照书名排序,这样需要哪本书时很快就能找到。
如何快速地实现排序呢?我们可以有几种不同的想法。例如我们可以依次查看每本书,一旦发现两本紧挨着的书的次序不对就交换一下位置。这种想法能行,因为最终任何两本书的先后都不会错,但这平均要花费太长的时间。
另一种想法是先找出书名最“小”的那本书放在第一个位置,然后在剩下的书中再找出最“小”的放在紧挨着的后面位置,以此类推直到所有书都放在了正确的地方。这种想法也能行;但是由于大量有用的线索没有利用,多花费了许多时间。下面我们试试其他的想法。
下面的想法似乎比上面讨论的更加自然。第一本书自然是排好的。接下来我们拿第一本书的书名与第二本书的书名做比较,如果次序不对就交换两本书的位置。然后我们看下一本书在前面已经排好序的部分中应该放在什么位置。
这可以反复进行直到为所有的书安排了正确的位置。因为前面的书排序时提供的信息可供后面使用,这个方法应该效率高一些。
现在把这个算法再细细看一下。第一本书单独考虑可以看作排好了序。我们假设当前考虑的书是第i本书,而它左边所有的书都已排好序了。要将第i本书加入序列中,我们首先查找它正确的位置,随后将书插入即可;为此要将在正确位置右边的所有书向右移动一个位置。
接下来对第i + 1本书重复以上过程,以此类推直到所有的书放到了正确位置。这个方法能快速产生正确结果,特别是如果我们采用第1章介绍的二分搜索寻找正确插入位置则效果更明显。
我们现在来看看对任意数量的书,这个直观的方法如何实现。为了描述起来简单一些,我们用数字代替书名。
图2-1中左边的5本书(1,6,7,9,11)已经排好序,而书名为5的书位置不正确。为了将5放入正确位置,首先与11交换位置,再与9交换位置,以此类推直到5到达正确位置。然后我们再处理书名为3的书,同样通过与左侧的书交换来到达正确位置。显然最终所有的书都会放到正确的地方(见图2-2)。
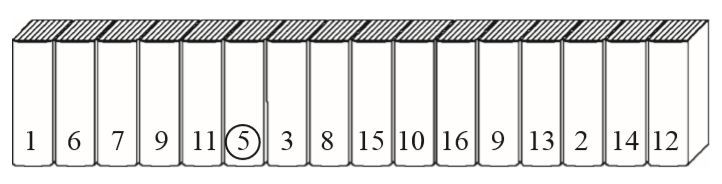
▲图2-1 前5本书已排好序

▲图2-2 书名为“5”的书移动到正确位置
以下是算法的代码。这里使用数组A,其元素标号为1,2,3,…。A[i]表示数组中第i个元素的值。给n本书排序使用长度为n的数组,元素A[1],A[2],A[3],…,A[n-1],A[n]存放所有的书名。

现在考虑算法执行花费的时间。我们考虑最坏的情况,所有书放置的位置正好与期望的次序相反,即书名最小的在最后的位置上,而书名最大的却在最前面的位置上。
我们的算法让第1本书与第2本书交换位置,第3本书要和前两本书中每一本交换位置,第4本书则要和前面3本书中每一本交换位置,以此类推,最后的一本书得和前面n-1本书中的每一本交换位置。交换的总次数是:
1+2+3+...+(n-1)=n(n-1)/2
利用图2-3很容易推导出上述公式。整个矩形中含n·(n-1)个单元格,其中一半用于比较与交换。图中显示的是绝对的最坏情况。考虑平均情况,我们可以假设只需要一半的比较与交换。
如果开始时书就几乎是排好序的,需要的工作量会少很多;最好的情况是开始时所有的书都在正确的位置上,那只需要进行n-1次比较即可。
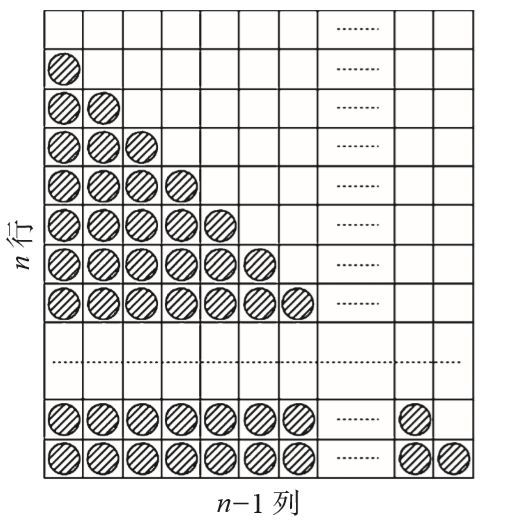
▲图2-3 计算交换次数
你也许会看出算法还可以更简洁些。不用交换相邻的两本书,而是将多本书向右移动,使得需要的插入位置空出来。如果2-4所示。
原来的k次两两置换操作,现在可以用k + 1次移动一本书的操作替代。算法修改如下:


▲图2-4 计算交换次数
尽管在串行的计算机上此算法排序效率不高,但它的实现非常简单,所以当需要排序的对象数量不太大,或者可以假设多数对象次序不错的情况下还是会经常使用插入排序算法。要对大量对象进行排序就会使用其他算法,如mergeSort和quickSort。那些算法理解起来会难一些,实现也更复杂。
关于作者:本书共有66位作者,主要来自德国、瑞士。由贝特霍尔德·弗金(Berthold Vöcking)、赫尔穆特·阿尔特(Helmut Alt)、马丁·迪茨费尔宾格(Martin Dietzfelbinger)、吕迪格·赖舒科(Rüdiger Reischuk)、克里斯蒂安·沙伊德勒(Christian Scheideler)、黑里贝特·沃尔默(Heribert Vollmer)、多萝西娅·瓦格纳(Dorothea Wagner)领衔编著。
本文摘编自《无处不在的算法》,经出版方授权发布。
延伸阅读《无处不在的算法》
点击上图了解及购买
转载请联系微信:togo-maruko
推荐语:杰出计算机教育家南京大学陈道蓄教授翻译并推荐,启蒙学生对计算机科学兴趣、提升计算思维素养的入门读本。
▼
Q:这些技能你都掌握了吗?
转载 / 投稿请联系:baiyu@hzbook.com返回搜狐,查看更多
责任编辑:
这篇关于高中数学学计算机编码部分,写给中学生的算法入门:学代码之前看这篇就够了...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





