本文主要是介绍python亲和度_Python数据挖掘 亲和性分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文学习资源来自《Python数据挖掘入门与实践》中国工信出版集团 人民邮电出版社
亲和度
亲和度是用来表示一个实体与其他实体之间的亲和程度。
假设有两个实体E1和E2,如果他们从来没有被相同的活动使用,则他们的亲和度E(E1,E2)=0;如果他们总是同时被每一个活动所使用,则他们的亲和度E(E1,E2)=1。如果仅被某些活动一起使用,则其亲和度E(E1,E2)在(0,1)的区间内。
——百度百科
典型的应用场景:
购买一种商品的顾客可能要购买另一些商品
为网站用户提供服务推荐或定向广告
根据基因寻找有亲缘关系的人
亲和性有多种测量方法,如:
统计两件端口一起出售的频率,或者统计顾客购买了商品1后再买商品2的比率。
示例
运行环境:IPython notebook
数据 affinity_dataset.txt
数据示例
0 0 1 1 1
1 1 0 1 0
1 0 1 1 0
0 0 1 1 1
0 1 0 0 1
0 1 0 0 0
加载数据
import numpy as np
dataset_filename = "affinity_dataset.txt"
X = np.loadtxt(dataset_filename)
n_samples, n_features = X.shape
print("This dataset has {0} samples and {1} features".format(n_samples, n_features))
输出:
This dataset has 100 samples and 5 features。
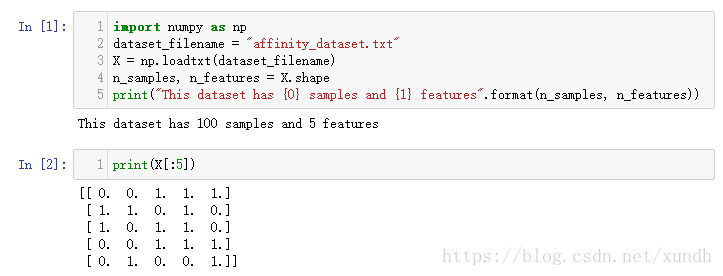
数据涵义:
每列代表一种商品,分别为:面包、牛奶、奶酪、苹果、香蕉
输出为前5次交易中顾客都买了什么,第一条数据 0 0 1 1 1表示第一条交易中顾客购买了奶酪、苹果、香蕉。
1表示购买了,0表示未购买。
实现简单的排序规则
我们要找出“如果顾客购买了商品X,那么他们可能愿意购买商品Y”的规则。简单粗暴的做法是,找出数据集中所有同时购买的两件商品。找出规则后,还需要判断其优劣,我们挑好的规则用。
规则的优劣有多种衡量方法,常用的是支持度(support)和置信度(confidence)。
支持度
指数据集中规则应验的次数,统计起来很简单。有时候,还需要对支持度进行规范化,即再除以规则有效前提下的总数量。这里只是简单统计规则应验的次数。
支持度衡量的是给定规则应验的比例,而置信度衡量的则是规则准确率如何,即符合给定条件(即规则的“如果”语句所表示的前提条件)的所有规则里,跟当前规则结论一致的比例有多大。计算方法为首先统计当前规则的出现次数,再用它来除以条件(“如果”语句)相同的规则数量。
示例代码:
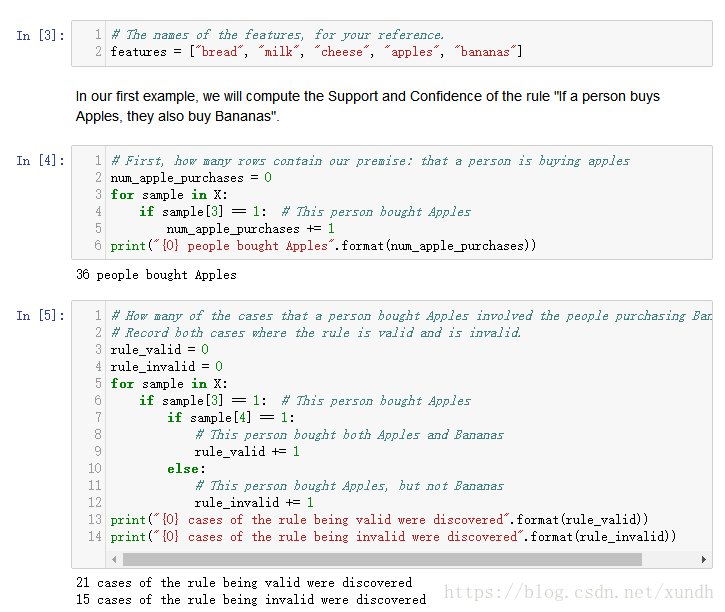
# The names of the features, for your reference.
features = ["bread", "milk", "cheese", "apples", "bananas"]
# First, how many rows contain our premise: that a person is buying apples
num_apple_purchases = 0
for sample in X:
if sample[3] == 1: # This person bought Apples
num_apple_purchases += 1
print("{0} people bought Apples".format(num_apple_purchases))
该代码计算确定购买苹果的顾客数量。
创建几个词典用来存放计算结果,使用defaultdict,需要统计的量有规则应验、规则无效及条件相同的规则数量。

其中置信度的计算方法:
confidence = defaultdict(float)
for premise, conclusion in valid_rules.keys():
confidence[(premise, conclusion)] = valid_rules[(premise, conclusion)] / num_occurences[premise]
定义打印规则:
def print_rule(premise, conclusion, support, confidence, features):
premise_name = features[premise]
conclusion_name = features[conclusion]
print("Rule: If a person buys {0} they will also buy {1}".format(premise_name, conclusion_name))
print(" - Confidence: {0:.3f}".format(confidence[(premise, conclusion)]))
print(" - Support: {0}".format(support[(premise, conclusion)]))
print("")
测试代码:
premise = 1
conclusion = 3
print_rule(premise, conclusion, support, confidence, features)
输出:

排序找出最佳规则

该代码输出支持度最高的前5条规则 ,
如果要按置信度排序:

我们可以看到结果,“顾客买苹果,也会买奶酪”和“顾客买奶酪,也会买香蕉”,这两条规则的支持度和置信度都很高。
这篇关于python亲和度_Python数据挖掘 亲和性分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




