本文主要是介绍使用bert复现spo抽取的一些随笔(仅作自己总结使用),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
开始下定决心以后慢慢总结,最近发现学习的时候需要总结思路,这样会更加清晰明了,提高学习效率。
随笔1
内容:bug,但是有正确代码对比
方向:基于bert的多标签任务,baiduRE.py
BUG说明: tensorflow.python.framework.errors_impl.InvalidArgumentError: Key label_ids Can't parse serialized Example.
解决方式:1.找到在自己代码中错误的最后代码行数
2.说明问题在此行代码值之前
3.找到key:"label_ids"出现的位置,依次打上断点,对features进行观察
4.发现在file_based_input_fn_builder()函数之前,features格式都为一致
5.找到BUG发生地点,tf.FixedLenFeature([], tf.int64), 第一个参数没有添加label_length
思考:因为是基于有正确代码的对比,所以过程还不算艰辛,倘若是自己没头脑的调试,可能要花很长时间。这次想要总结一下的原因事发现自己有什么错误都喜欢直接复制BUG内容到网上查找,其实可以通过以往的经验以及些许英语水平思考得出结果。这样才能慢慢积累经验以及使得思路清晰。
随笔2
class FixedLenFeature(collections.namedtuple("FixedLenFeature", ["shape", "dtype", "default_value"])):#用于解析一个固定长度的feature输入学习编程是一个需要动手实践的过程,需要在实践中不断积累,代码中的一些API就是像 1+1=2 基础知识一样,只有弄清楚且记住才能继续进行,不然步步维艰。
随笔3
多读代码,并且代码里面不懂函数可以直接看源码里的注释和示例,不一定需要上网百度。
学习编程是一个积累的过程,简单来说只有花费时间,让代码在自己的脑袋里面跑(读代码和写代码才有这个效果)。
随笔4
今天还是在bert的基础上改代码,一直在考虑如何复现一个损失函数,弄了半天,还是不对,式子到最后还有一部分没有弄清楚。可以说今天基本上算是一无所获,除了几个tf.cast之类的函数调用的更加熟练之外。效率之低令人发指。
这是我今天感觉到的一点问题
- 没有思考为什么就动手写代码,还自作聪明地省去了损失函数的后一部分,最后loss下降的很快,但是精度一丝丝都没有,看了模型给数据的预估值,发现每一个都是非常接近1。仔细思考后明白,当预测值取的非常大的时候,损失值可以达到非常小,所以说这个损失函数写的是完全失败的。其中的原因:粗心,没有深入思考。
- 在复现我的半吊子函数时,还出现了两个问题:一个表达式中少乘了一个式子,在浪费接近一个小时之后,发现并补上,之后又出现损失值一直飘向于负无穷;之后又发现最后的loss表达式少添加了一个符号,添加之后loss一直减小。原因:粗心,没有严格按照别人的来做。
- 在这个过程中,又发现了自己对tensorflow的基础知识严重不足,比如如何在bert中打印张量,到最后也没有找到解决方法,诸如一类session.run()和t.eval()全都试过,没有用处。思考:不要太过于坚持,如果坚持请不要一味百度搜索,自己从源码分析。再有不知道如何计算acc等评估参数,以至于不知道自己的模型到底有没有训练的价值,浪费了很长时间。思考:不要自己盲目地探索,要找到有效的方式。
最后
不要自己想当然!相信大牛!相信导师!相信自己!
今天心态很爆炸。
随笔5
今天继续阅读源码,看到eval模式下如何计算acc的问题:
source code:
predictions = tf.argmax(logits, axis=-1, output_type=tf.int32)
accuracy = tf.metrics.accuracy(labels=label_ids, predictions=predictions, weights=is_real_example)进入accuracy:嗯,看不太懂,简单来说就是输入预测值和真实值,进行比较,拿 比较的个数(count)/比较后正确的个数(total) 之后,便得到其准确率。
上google找一个例子来看看吧:
logits = [[0.1, 0.5, 0.4],[0.8, 0.1, 0.1],[0.6, 0.3, 0.2]]
labels = [[0, 1, 0],[1, 0, 0],[0, 0, 1]]acc, acc_op = tf.metrics.accuracy(labels=tf.argmax(labels, 1), predictions=tf.argmax(logits,1))print(sess.run([acc, acc_op]))
print(sess.run([acc]))
# Output
#[0.0, 0.66666669]
#[0.66666669]看起来很显而易见,但是为什么acc一开始为0.0?
继续下面的解释:
#初始化一些变量
logits = tf.placeholder(tf.int64, [2,3])
labels = tf.Variable([[0, 1, 0], [1, 0, 1]])acc, acc_op = tf.metrics.accuracy(labels=tf.argmax(labels, 1), predictions=tf.argmax(logits,1))sess = tf.Session()sess.run(tf.local_variables_initializer())
sess.run(tf.global_variables_initializer())stream_vars = [i for i in tf.local_variables()]
print(stream_vars)#total,count 是两个accuracy函数在本地初始化的viriables
#访问acc,可以看到acc和[total,count]都没有变化
print('acc:',sess.run(acc, {logits:[[0,1,0],[1,0,1]]}))
#acc: 0.0
print('[total, count]:',sess.run(stream_vars))
#[total, count]: [0.0, 0.0]#访问acc_op,可以看到acc_op和total,count,acc都更新了
print('ops:', sess.run(acc_op, {logits:[[0,1,0],[1,0,1]]}))
#ops: 1.0print('[total, count]:',sess.run(stream_vars))
#[total, count]: [2.0, 2.0]print('acc:', sess.run(acc,{logits:[[1,0,0],[0,1,0]]}))
#acc: 1.0#再次访问,准确率立即更新
print('op:',sess.run(acc_op,{logits:[[0,1,0],[0,1,0]]}))
#op: 0.75
print('[total, count]:',sess.run(stream_vars))
#[total, count]: [3.0, 4.0]所以我把acc简单的理解为一个缓冲区,在访问acc_op之前,把所有要进行acc计算的内容都存储起来,访问acc_op时,以先进先出的原则,拿出一个logits进行操作。
参考链接:https://stackoverflow.com/questions/46409626/how-to-properly-use-tf-metrics-accuracy
随笔6
事件:运行关系预测的代码模型
结果: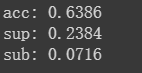
发现:正确答案中有一个关系出现多次,比如演员这个关系在一个text中多次出现—》关系完全正确的概率 是63.86%,在预测结果和正确结果之外加set的正确概率是75.5%左右,后面依次如图。虽然是sup的比例很大,但是观察数据发现,有部分预测出来的正确关系数据集并未标注。考虑如果实际应用其实这23%都可以加上。
思考(一个关系多次出现的解决方案):数据集原本按照是01打上标签,显然在关系多次出现的情况下特征损失。考虑按照按照关系出现的次数标注,等于一个label的输出可能对应多个(原本只是01,现在可能0123...)暂未实验,后续动手实践改进。
随笔7
事件:洗澡
内容:突然想到关于上文的想法是错误的。所需要研究的任务是一个管道式抽取,关系预测部分预测的结果虽然会有一个关系多次出现的情况,但是输入到后续的实体识别的模块,并无影响。比如输入的关系是演员,那么所有和演员关系相关的实体都被激活,他们的激活与否通过概率矩阵体现。
思考:如果不是洗澡时候突然脑袋一闪,可能明早又要浪费一早上去直接实现了。所以说,多加思考!(洗澡的时候好像确实脑袋更好使哈)
随笔8
bert运行的主要流程
- 处理好数据,输入bert。
- bert进行随机编码,可以任意切分输出的个数。
- 将每个输出的张量(predication)和对应的标签(target)传入loss_function进行计算再得到total_loss
- total_loss传入优化器,优化器根据loss的大小进行收敛,使得每个输出的张量和tartget越来越相似
- 得到训练好的模型
之前刚刚用squad脚本时,一直不明白create_model的输出为何一定符合期望,其实等于是给定model人类所期望的答案模式,然后让它去学习。
这篇关于使用bert复现spo抽取的一些随笔(仅作自己总结使用)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




