本文主要是介绍论文阅读之Enhancing Transformer with Sememe Knowledge(2020),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 论文阅读
- Transformmer-SE
- Transformer-SP
- 实验结果
- 总结
- 参考
论文阅读
文章建议结合两种简单的方法将义原知识整合:
1)基于语言学假设,我们将聚合义原嵌入添加到每个词嵌入中以增强其语义表示;
2)我们使用义原预测作为辅助任务,帮助模型更深入地理解单词语义。
文章验证了我们的方法在与词级和句子级语义密切相关的几个中文 NLP 任务上的有效性。在预训练和微调的一般设置之后,实验表明使用半增强型 Transformer 在所有任务上都有一致的改进。
文章还发现,义原增强模型可以用较少的微调数据实现相同的性能,这是可取的,因为数据注释过程总是耗时且昂贵。
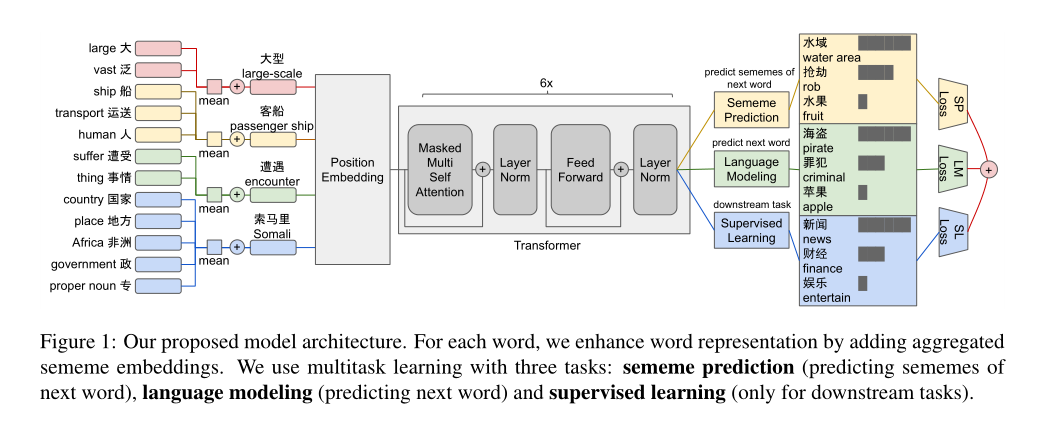
模型的基本架构图如上。
思路简单,使用义原embedding的均值来增强词向量的embedding(二者相加),然后经过原始的transformer对句子进行编码,然后进行多任务的学习:对下一个词的的义原的预测、对下一个词的预测、下游任务的学习。
Transformmer-SE
看看公式:
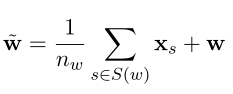
Xs就是义原的embedding,w就是词的embedding,左边的结果就是通过义原增强后的embedding了。
Transformer-SE就是这么简单,在embeding做点手脚即可。
Transformer-SP
义原预测任务旨在预测下一个词的义原,可以表述为多标签分类任务。受多任务学习 (Caruana, 1997; Collobert et al, 2011) 的启发,文章在 Transformer-SP 的语言建模任务之外添加了义原预测任务。
这项任务挑战了模型整合义原知识的能力,并且可以被视为语言建模的补充任务,因为预测下一个单词的义原与理解语义密切相关,而且它通常比直接建模下一句话。
就是说Transformer-SP在训练方式上做了手脚,或者就是说修改了损失函数,让损失考虑到义原的预测,从而使得模型训练获得义原信息从而模型对其他任务的效果。
我们先看一下变量的定义:

(w1,…,wT)表示输入的单词
然后经过embedding层向量化后就表示为H0 = (w1,…,wT)
其中T表示单词的个数,D表示的应该就是d_model(也就是相当于embedding_size)
h1L 表示第1个单词的向量表示
h2L 表示第1、2个单词的向量表示…以此类推
公式如下:
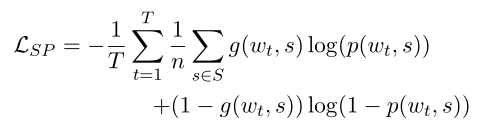

其中的hL 表示的是句子经过transform后的embedding表示。
p(w, s)表示的是下一个词w的义原s的概率。
那么义原预测的损失函数定义如下:
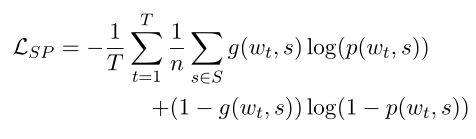

其中S是所有义原的集合。
g(wt,s)表示0,1二值函数,用于表示这个义原是否是下一个词的义原。
因为词的义原并不是唯一的,因此这就是多标签分类的损失函数了。
那么Transformer-SP的损失函数就可以定义如下了:

LSL表示下游任务的损失函数
LLM表示预测下一个词的损失函数
LPRE表示预训练的损失函数
L就表示优化了的下游任务的损失函数,也就是Transformer-SP的改进之处了。
那么transformer-SP就是说,在下游任务损失函数的基础上,加入了LPRE这么一个预训练的损失函数,就是使用预测下一个词和预测下一个词的义原这个任务来帮助词向量的训练,使得词向量融入义原知识,也就是论文标题说的义原知识增强的第二种方式了。
这篇文章代码写的挺正常的,可读性还是蛮强的,我们可以看看代码:
这是模型设置的两种损失函数
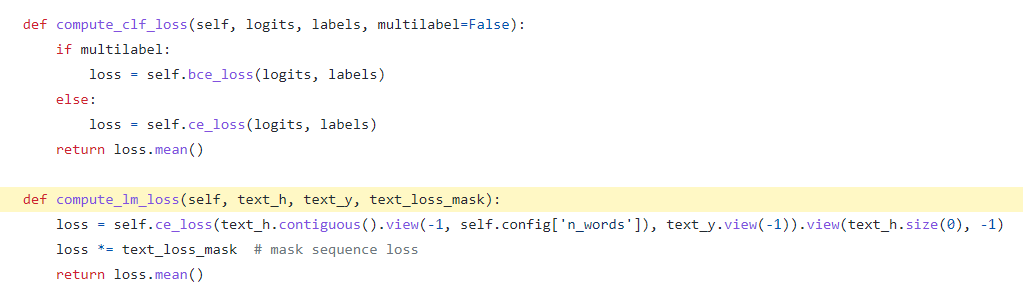
这个就是一个多标签的分类损失函数。
这就是交叉熵损失函数,分类常用的损失函数。
那么看一下模型损失函数调用的那块的代码:

loss_lm就是预测下一个词的损失函数,经典分类问题
loss_sp就是预测下一个词的义原的损失函数,多标签分类问题
实验结果
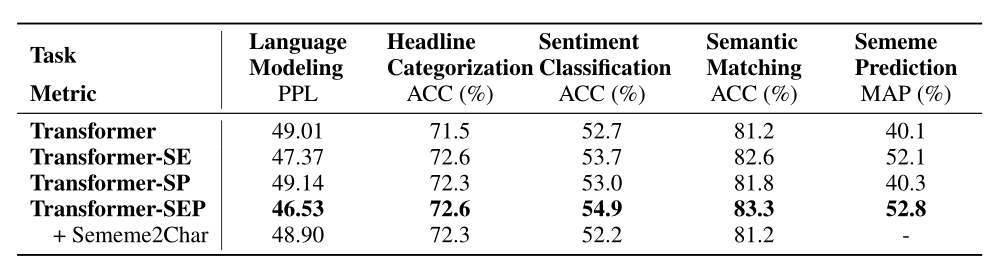
Transformer-SEP就是词进行义原增强,也用改进了的损失函数,即综合了SE和SP两种方法。
从实验结果看得出来,义原确实能够提示效果。
总结
读了这篇文章,大概知道义原的用法了。SE就是直接词向量加入义原embedding,SP是通过损失函数来进行义原融入词向量,SEP则是结合前两者。因此使用义原的精髓应该就是能够考虑义原embedding的训练吧。
参考
Enhancing Transformer with Sememe Knowledge
https://github.com/yuhui-zh15/SememeTransformer
这篇关于论文阅读之Enhancing Transformer with Sememe Knowledge(2020)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)