本文主要是介绍paddle2.0高层API实现基于seq2seq的对联生成,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
paddle2.0高层API实现基于seq2seq的对联生成
『深度学习7日打卡营·day5』
零基础解锁深度学习神器飞桨框架高层API,七天时间助你掌握CV、NLP领域最火模型及应用。
-
课程地址
传送门:https://aistudio.baidu.com/aistudio/course/introduce/6771 -
目标
- 掌握深度学习常用模型基础知识
- 熟练掌握一种国产开源深度学习框架
- 具备独立完成相关深度学习任务的能力
- 能用所学为AI加一份年味
对联,是汉族传统文化之一,是写在纸、布上或刻在竹子、木头、柱子上的对偶语句。对联对仗工整,平仄协调,是一字一音的汉语独特的艺术形式,是中国传统文化瑰宝。
这里,我们将根据上联,自动写下联。这是一个典型的序列到序列(sequence2sequence, seq2seq)建模的场景,编码器-解码器(Encoder-Decoder)框架是解决seq2seq问题的经典方法,它能够将一个任意长度的源序列转换成另一个任意长度的目标序列:编码阶段将整个源序列编码成一个向量,解码阶段通过最大化预测序列概率,从中解码出整个目标序列。编码和解码的过程通常都使用RNN实现。
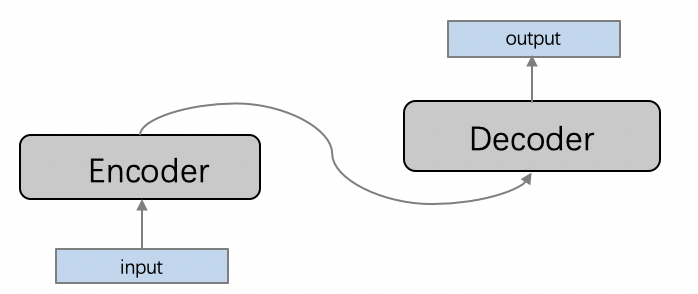
这里的Encoder采用LSTM,Decoder采用带有attention机制的LSTM。
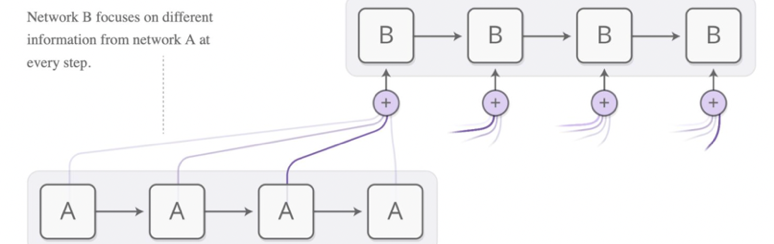
我们将以对联的上联作为Encoder的输出,下联作为Decoder的输入,训练模型。
生成对联部分结果
上联: 芳 草 绿 阳 关 塞 上 春 风 入 户 下联: 小 桥 流 水 人 家 中 喜 气 盈 门上联: 致 富 思 源 跟 党 走 下联: 脱 贫 致 富 为 民 圆上联: 欣 然 入 梦 抱 书 睡 下联: 快 意 临 风 把 酒 眠上联: 诗 赖 境 奇 赢 感 动 下联: 风 流 人 杰 显 精 神上联: 栀 子 牵 牛 犁 熟 地 下联: 莲 花 引 蝶 戏 开 花上联: 廿 载 相 交 成 知 己 下联: 千 秋 不 朽 著 文 章上联: 润 下联: 修上联: 设 帏 遇 芳 辰 百 岁 期 颐 刚 一 半 下联: 被 被 逢 盛 世 千 秋 俎 豆 尚 千 秋上联: 波 光 云 影 满 目 葱 茏 谁 道 人 间 无 胜 地 下联: 鸟 语 花 香 一 帘 幽 梦 我 听 天 下 有 知 音上联: 眸 中 映 月 心 如 镜 下联: 笔 底 生 花 气 若 虹上联: 何 事 营 生 闲 来 写 幅 青 山 卖 下联: 此 时 入 梦 醉 去 吟 诗 碧 水 流上联: 学 海 钩 深 毫 挥 具 见 三 长 足 下联: 书 山 登 绝 顶 摘 来 登 九 重 天上联: 女 子 千 金 一 笑 贵 下联: 男 儿 万 户 百 年 长上联: 柏 叶 为 铭 椒 花 献 瑞 下联: 梅 花 作 伴 凤 凤 鸣 春上联: 家 国 遽 亡 天 涯 有 客 图 恢 复 下联: 江 山 永 在 我 心 无 人 泪 滂 沱上联: 侍 郎 赋 咏 穷 三 峡 下联: 游 子 吟 诗 醉 九 江上联: 反 腐 堵 污 流 杜 渐 防 微 不 教 长 堤 崩 蚁 穴 下联: 倡 廉 增 正 气 阳 光 普 照 长 教 大 道 播 春 风上联: 已 兆 飞 熊 钓 渭 水 下联: 欲 栽 大 木 柱 长 天上联: 建 生 态 文 明 人 与 自 然 协 调 发 展 下联: 创 文 明 发 展 事 同 事 业 发 展 文 明上联: 于 自 不 高 于 他 不 下 下联: 以 人 为 本 为 我 无 为上联: 国 泰 民 安 军 民 人 人 歌 盛 世 下联: 民 安 国 泰 社 会 事 事 颂 和 谐上联: 金 龙 腾 大 地 看 四 野 平 畴 三 农 报 喜 下联: 玉 兔 跃 神 州 喜 九 州 大 地 万 户 迎 春上联: 兴 盛 下联: 平 安上联: 长 安 跑 马 谁 得 意 下联: 广 府 古 城 百 花 芳AI Studio平台后续会默认安装PaddleNLP,在此之前可使用如下命令安装。
!pip install --upgrade paddlenlp>=2.0.0b -i https://mirror.baidu.com/pypi/simple
import paddlenlp
paddlenlp.__version__
'2.0.0rc1'
import io
import osfrom functools import partialimport numpy as npimport paddle
import paddle.nn as nn
import paddle.nn.functional as F
from paddlenlp.data import Vocab, Pad
from paddlenlp.metrics import Perplexity
from paddlenlp.datasets import CoupletDataset
数据部分
数据集介绍
采用开源的对联数据集couplet-clean-dataset,该数据集过滤了
couplet-dataset中的低俗、敏感内容。
这个数据集包含70w多条训练样本,1000条验证样本和1000条测试样本。
下面列出一些训练集中对联样例:
上联:晚风摇树树还挺 下联:晨露润花花更红
上联:愿景天成无墨迹 下联:万方乐奏有于阗
上联:丹枫江冷人初去 下联:绿柳堤新燕复来
上联:闲来野钓人稀处 下联:兴起高歌酒醉中
加载数据集
paddlenlp.datasets中内置了多个常见数据集,包括这里的对联数据集CoupletDataset。
paddlenlp.datasets均继承paddle.io.Dataset,支持paddle.io.Dataset的所有功能:
- 通过
len()函数返回数据集长度,即样本数量。 - 下标索引:通过下标索引[n]获取第n条样本。
- 遍历数据集,获取所有样本。
此外,paddlenlp.datasets,还支持如下操作:
- 调用
get_datasets()函数,传入list或者string,获取相对应的train_dataset、development_dataset、test_dataset等。其中train为训练集,用于模型训练; development为开发集,也称验证集validation_dataset,用于模型参数调优;test为测试集,用于评估算法的性能,但不会根据测试集上的表现再去调整模型或参数。 - 调用
apply()函数,对数据集进行指定操作。
这里的CoupletDataset数据集继承TranslationDataset,继承自paddlenlp.datasets,除以上通用用法外,还有一些个性设计:
- 在
CoupletDataset class中,还定义了transform函数,用于在每个句子的前后加上起始符<s>和结束符</s>,并将原始数据映射成id序列。
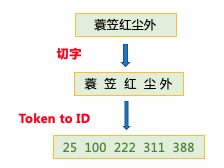
train_ds, dev_ds, test_ds = CoupletDataset.get_datasets(['train', 'dev', 'test'])
100%|██████████| 21421/21421 [00:00<00:00, 26153.43it/s]
来看看数据集有多大,长什么样:
print(len(train_ds), len(test_ds), len(dev_ds))# 加入了起始符和终止符
for i in range(5):print(train_ds[i])print()for i in range(5):print(test_ds[i])
702594 999 1000
([1, 447, 3, 509, 153, 153, 279, 1517, 2], [1, 816, 294, 378, 9, 9, 142, 32, 2])
([1, 594, 185, 10, 71, 18, 158, 912, 2], [1, 14, 105, 107, 835, 20, 268, 3855, 2])
([1, 335, 830, 68, 425, 4, 482, 246, 2], [1, 94, 51, 1115, 23, 141, 761, 17, 2])
([1, 126, 17, 217, 802, 4, 1103, 118, 2], [1, 125, 205, 47, 55, 57, 78, 15, 2])
([1, 1203, 228, 390, 10, 1921, 827, 474, 2], [1, 1699, 89, 426, 317, 314, 43, 374, 2])([1, 6, 201, 350, 54, 1156, 2], [1, 64, 522, 305, 543, 102, 2])
([1, 168, 1402, 61, 270, 11, 195, 253, 2], [1, 435, 782, 1046, 36, 188, 1016, 56, 2])
([1, 744, 185, 744, 6, 18, 452, 16, 1410, 2], [1, 286, 102, 286, 74, 20, 669, 280, 261, 2])
([1, 2577, 496, 1133, 60, 107, 2], [1, 1533, 318, 625, 1401, 172, 2])
([1, 163, 261, 6, 64, 116, 350, 253, 2], [1, 96, 579, 13, 463, 16, 774, 586, 2])
vocab, _ = CoupletDataset.get_vocab()
trg_idx2word = vocab.idx_to_token
vocab_size = len(vocab)pad_id = vocab[CoupletDataset.EOS_TOKEN]
bos_id = vocab[CoupletDataset.BOS_TOKEN]
eos_id = vocab[CoupletDataset.EOS_TOKEN]
print (pad_id, bos_id, eos_id)
2 1 2
构造dataloder
使用paddle.io.DataLoader来创建训练和预测时所需要的DataLoader对象。
paddle.io.DataLoader返回一个迭代器,该迭代器根据batch_sampler指定的顺序迭代返回dataset数据。支持单进程或多进程加载数据,快!
接收如下重要参数:
batch_sampler:批采样器实例,用于在paddle.io.DataLoader中迭代式获取mini-batch的样本下标数组,数组长度与 batch_size 一致。collate_fn:指定如何将样本列表组合为mini-batch数据。传给它参数需要是一个callable对象,需要实现对组建的batch的处理逻辑,并返回每个batch的数据。在这里传入的是prepare_input函数,对产生的数据进行pad操作,并返回实际长度等。
PaddleNLP提供了许多NLP任务中,用于数据处理、组batch数据的相关API。
| API | 简介 |
|---|---|
paddlenlp.data.Stack | 堆叠N个具有相同shape的输入数据来构建一个batch |
paddlenlp.data.Pad | 将长度不同的多个句子padding到统一长度,取N个输入数据中的最大长度 |
paddlenlp.data.Tuple | 将多个batchify函数包装在一起 |
更多数据处理操作详见: https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/data.md
def create_data_loader(dataset):data_loader = paddle.io.DataLoader(dataset,batch_sampler=None,batch_size=batch_size,collate_fn=partial(prepare_input, pad_id=pad_id))return data_loaderdef prepare_input(insts, pad_id):src, src_length = Pad(pad_val=pad_id, ret_length=True)([inst[0] for inst in insts])tgt, tgt_length = Pad(pad_val=pad_id, ret_length=True)([inst[1] for inst in insts])tgt_mask = (tgt[:, :-1] != pad_id).astype(paddle.get_default_dtype())return src,<这篇关于paddle2.0高层API实现基于seq2seq的对联生成的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





