本文主要是介绍[深度学习从入门到女装]High-Resolution Representations for Labeling Pixels and Regions,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文地址:High-Resolution Representations for Labeling Pixels and Regions
一篇使用HRNet进行语义分割和目标检测论文
HRNet=high resolution Net
low resolution net就是用于分类的网络,通过stride逐步减少resolution,获取语义信息,最终得到分类
但是这种low-resolution net对于目标检测或者语义分割来说是不可兼容的,因此语义分割最终需要的结果是high-resolution的,也就是每个pixel的class
因此,目前获得high-resolution的网络有两种方式
1、第一种是类似于encoder-decoder的网络,如U-net,SegNet等,就是先使用down-sampling降低resolution获取语义信息,再通过upsample增加resolution获得空间信息
2、第二种是整个网络都保持high-resolution,并且使用平行线路来得到low-resolution,如GrideNet
HRNet就是使用第二种思路,使用平行的low-resolution和high-resolution进行concate得到high-resolution的表示
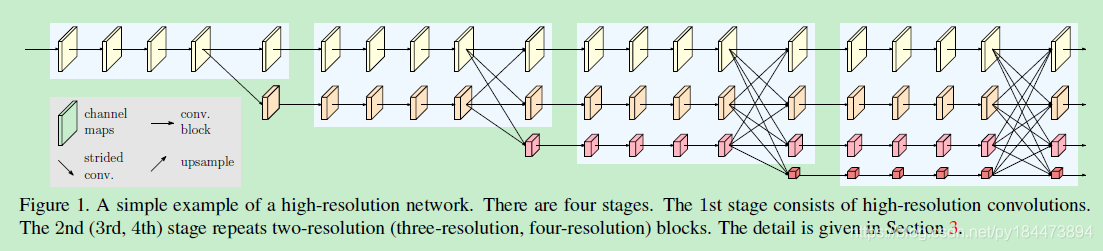
网络结构如下图所示
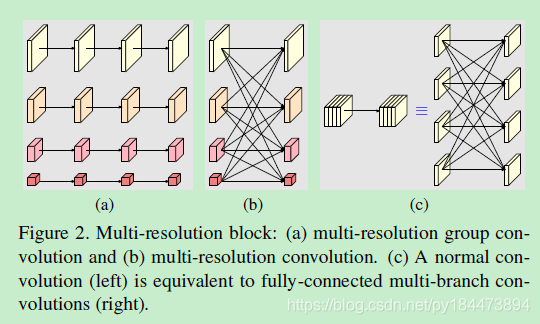
上图中的a为multi-resolution group conv,也就是简单的对于group conv的拓展,将input channels分为多个subset然后进行常规conv
上图中的b为multi-resolution conv
上图中的c为常规conv,可以看到常规conv可以将input channels和outputs channels都分为不同的subsets,然后进行一个全连接,每个连接是一个常规的conv

上图中的a为HRNetV1的多resolution融合的模块,可以看到,多个resolution的feature map作为输入,最终只得到了一个high-resolution,不可避免的丢失了一些low-resolution的信息
上图中的b为用于语义分割的block,将多个resolution进行concate得到一个最终的输出
上图中的c为用于目标检测的block,因为目标检测需要多个resolution的feature map,因此对于融合后的feature map再进行dowmsampling
语义分割网络结构
1、首先使用两个stride=2 的33conv对原图进行处理,将分辨率降为1/4
2、使用图1中的网络进行多个resolution的平行conv,channels数分别为C,2C,4C,8C
3、最终使用11的卷积对多个resolution进行融合得到15C的channels
4、最终的feature map进行4次bilinear upsampling得到最终结果
这篇关于[深度学习从入门到女装]High-Resolution Representations for Labeling Pixels and Regions的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






