本文主要是介绍A16Z: 为什么美国企业在数据基建上的投入持续飙升?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天,小编与大家分享一篇来自美国知名科技企业风投机构 A16Z 的文章。这篇文章基于对美国市场中领先的技术公司 Databricks,Imply (Druid商业公司),Looker,Snowflake 等从业人士的调查,介绍了美国企业在数据平台发展的整体趋势。
中美企业在数据基建上的发展有很多相似之处,相信这篇文章对于中国的企业的数据基建也具有借鉴意义。今后我们也将不定期与大家分享海内外的行业洞察。
美国数据基建市场蓬勃增长
数据基建市场仍在蓬勃增长,根据Gartner报道,2019年数据基建方面的采购费用飙升到 660亿美元,占据基础架构类软件费用的24%。
头部的30家数据基建创业公司在过去5年已收获80亿的风险融资,根据Pitchbook报道。

2015年到2020年间部分数据基建创业公司收获的风险融资情况
招聘市场也反馈了这一热度,数据分析师,数据工程师和机器学习工程师成为2019年领英网站上增长最快的职位。60%的财富1000强招聘了首席数据官,而这个数字在2012年仅为12%。而这些企业在持续的超越其同僚的表现。
数据在逐渐为业务产出做贡献,这不仅发生在硅谷科技公司也出现在很多传统行业。

各大数据驱动公司利用数据驱动业务的使用场景和产出
A16Z经过调查相关业内人士得出一个结论:一个统一的现代化的数据基建需要三类架构来实践三种不同的应用场景。
- 现代化 BI 架构
- 多模式数据处理架构
- 人工智能和机器学习架构
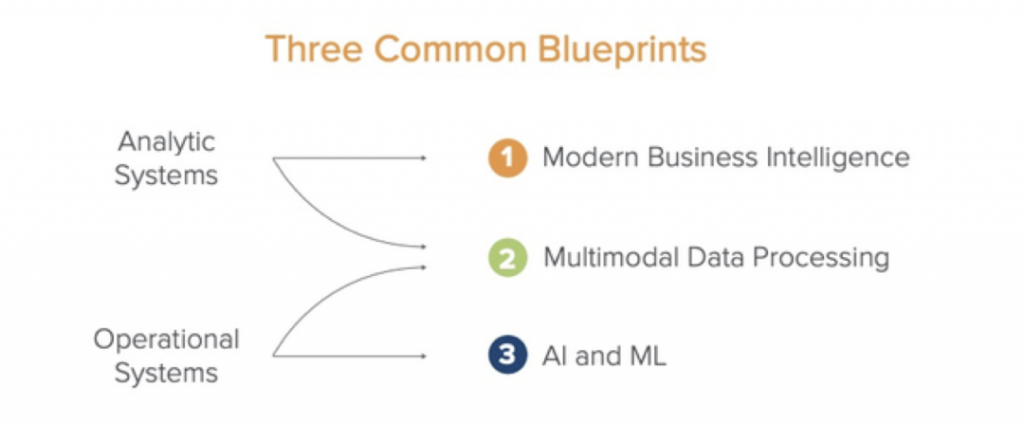
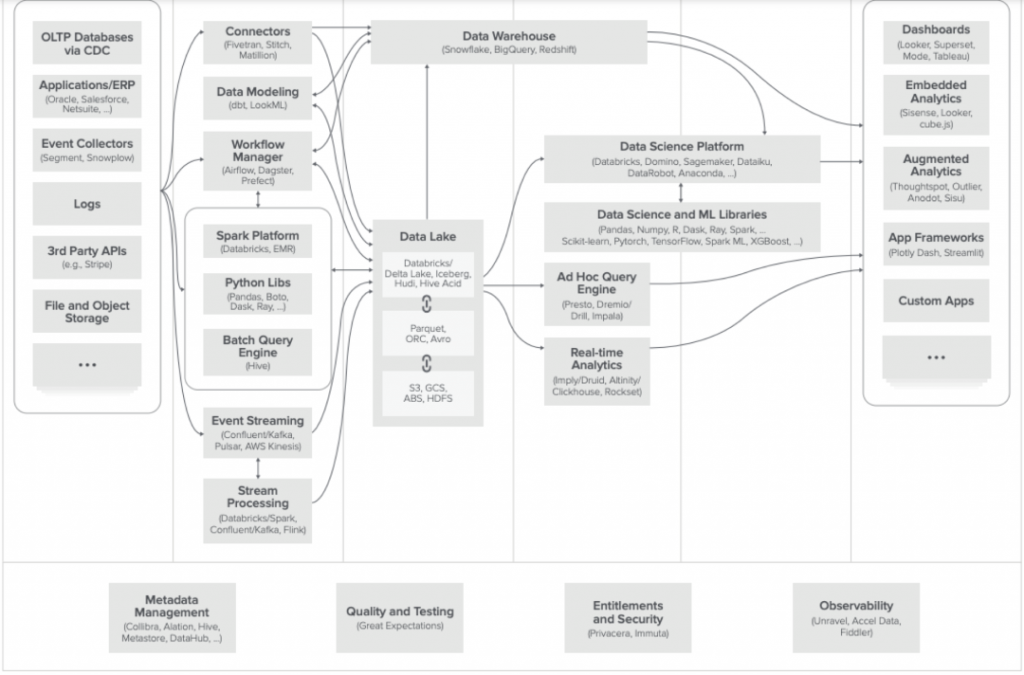
同时,A16Z总结出一套通用的技术架构服务以下三种场景。
数据基建架构全景
1.现代化 BI 架构
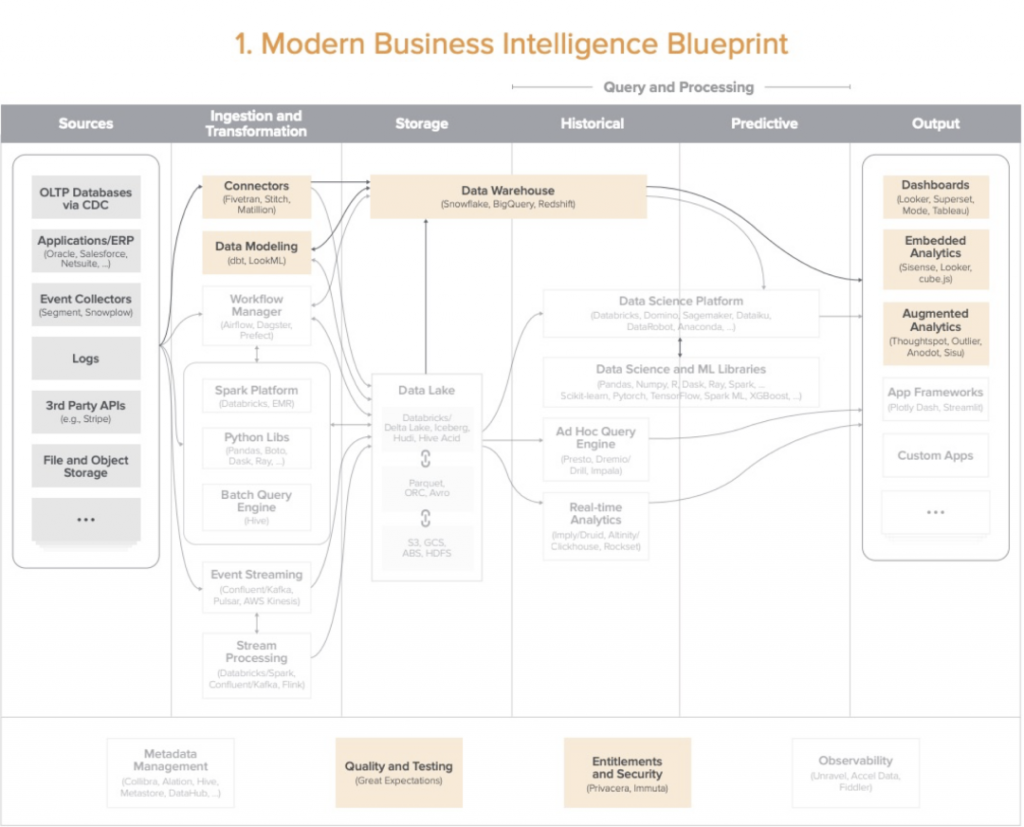
这是对小型数据团队和预算有限的企业的默认选项,企业逐渐从传统数仓迁移到这个架构,利用云的灵活度和可扩展性。
- 应用场景包含:报表,仪表盘,自助式分析,主要使用SQL来分析结构化数据。
- 优势: 前期投入低,启动快,市场上人才储备充分。
- 缺陷:对于数据场景复杂的团队不适用,比如需要数据科学,机器学习,或者实时场景
2.多模式数据处理架构
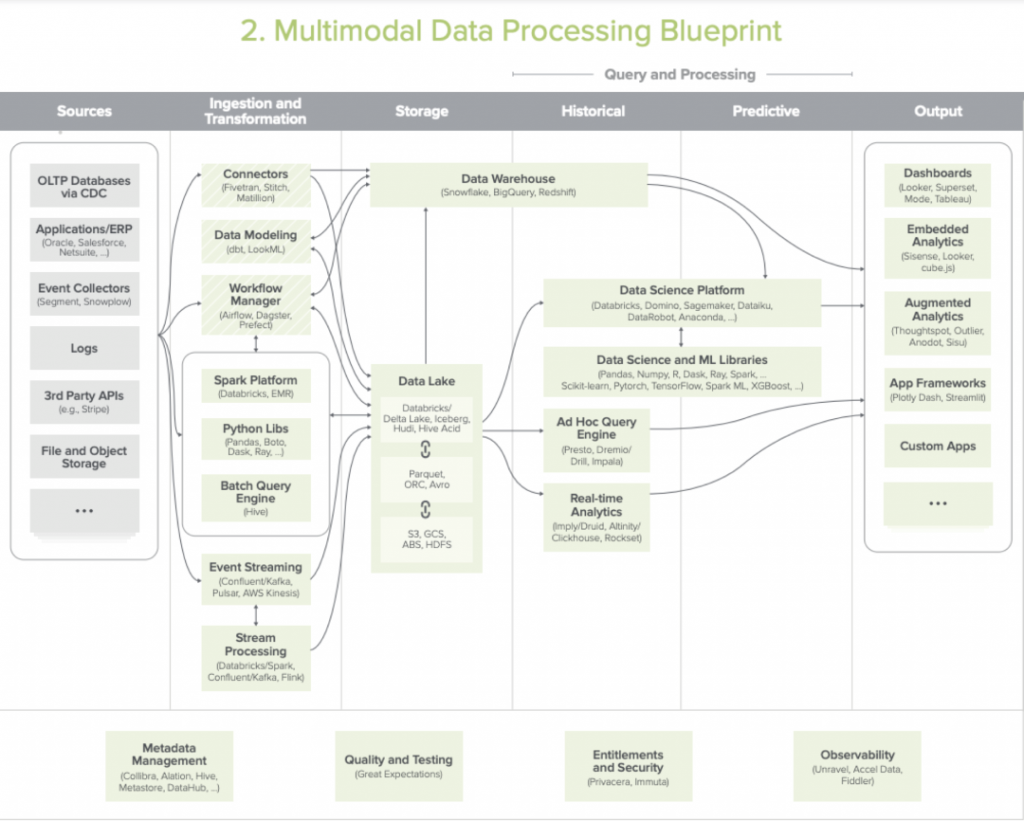
这个架构通常用于大型企业和科技公司,用来满足复杂的数据需求场景。
- 应用场景包括:BI及高级功能,包括AI/ML,低延时分析,大规模数据转换,多类型的数据处理(文字,图像和视频)使用各种语言(JAVA/SCALA,Python和SQL)
- 优势:能灵活的支持各种应用,工具和UDF和部署环境。在大规模数据集上的成本优势。
- 缺陷:不适合小型数据团队,维护这套架构需要较多的时间,费用和专家资源投入。
3. 人工智能和机器学习架构
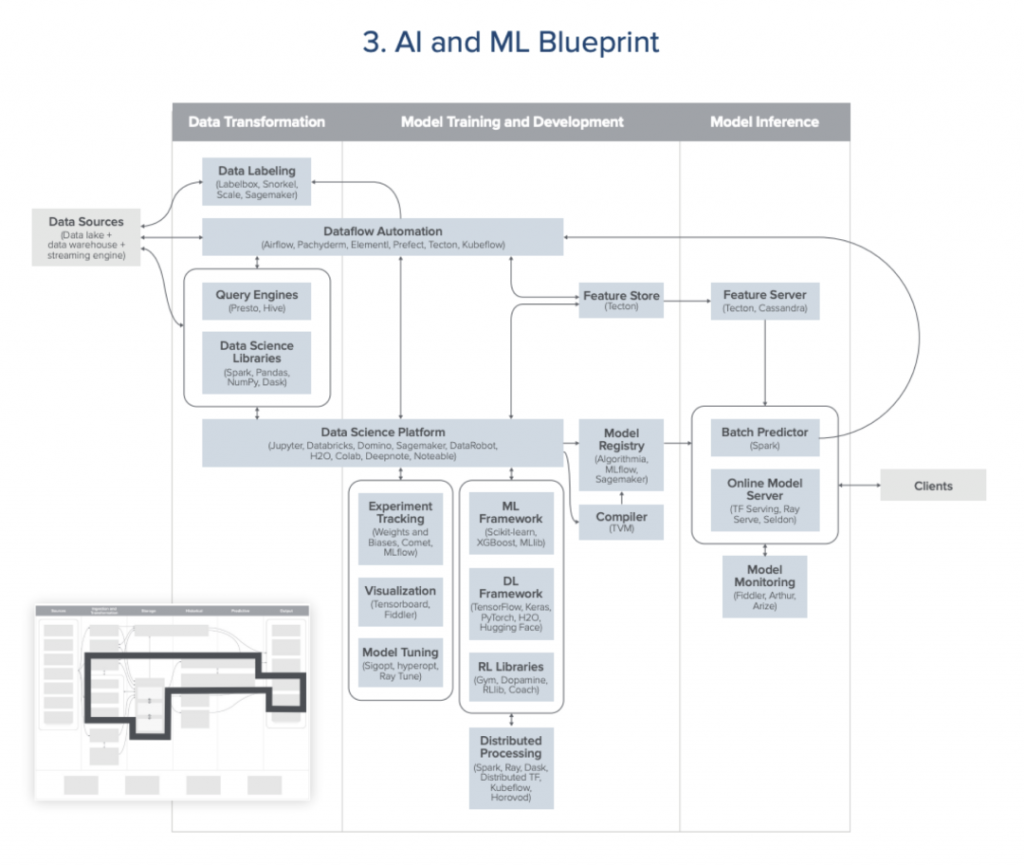
应用机器学习的公司已经在使用这套架构的一部分技术。深度使用机器学习的企业会部署整套架构,甚至自研新的工具。
场景:数据驱动的内外部应用程序,场景有实时的或批处理的。
优势:完全掌控整体的开发过程,将机器学习打造为企业核心且长期的能力。
缺陷:不适合尚在探索机器学习,只为小范围的内部应用场景。大规模应用机器学习仍是当前最大的数据挑战
六大架构变化趋势

- 本地向云端数据仓库迁移:Snowflake,Google Big Query
- Hadoop向下一代数据湖迁移:Databricks, Presto
- ETL向ELT迁移:Fivetran, dbt
- 工作流管理向工作流自动化迁移:Prefect,Dagstar,Airflow
- 分析师团队向自助式洞察迁移:Looker,Superset
- 终端访问控制向统一的数据治理迁移:Collibra,Privagera
三大新兴能力

- 低延时分析(流式分析):confluent(笔者注:kafka 商业公司)Imply (笔者注:Druid 商业公司)
- 成熟的数据科学工具箱:Pandas,R,Jupyter
- 机器学习和人工智能:Algorithmia,Tecton
关于 A16Z 此次调研
接受调研的业内人士来自 Databricks,Druid,Looker,Snowflake 等美国知名数据软件公司和 Linkedin 等大型企业。
接受调查的行业人士及其所在机构或企业
关于 A16Z
由Marc Andreessen and Ben Horowitz, Andreessen Horowitz 于2009创立,是美国知名的科技行业风投机构,主要对种子阶段和成长发展阶段的企业进行投资,是知名大数据初创企业 Databricks,Preset 的投资方。 感兴趣的小伙伴可以在这里阅读原文https://a16z.com/2020/10/15/the-emerging-architectures-for-modern-data-infrastructure/
参考阅读
- https://www.gartner.com/document/code/726997
- https://business.linkedin.com/content/dam/me/business/en-us/talent-solutions/emerging-jobs-report/Emerging_Jobs_Report_U.S._FINAL.pdf
这篇关于A16Z: 为什么美国企业在数据基建上的投入持续飙升?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




