本文主要是介绍spark Scala中dataframe的常用关键字:withColumn,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
withColumn关键字:
用于操作dataframe原表某一列的数据,将操作完的每一行数据形成一列,用来替换一个表原有的列或者在原表后面追加新的列!
语法如下:
def withColumn(colName: String, col: Column): DataFrame
withColumn传入两个参数:
先说第二个参数:
该参数传入的是操作dataframe表中指定”列”的数据。他会对dataframe表中的每一行数据进行操作,最后返回一个新的列。如果第一个参数传入的列名和第二个参数传入的列名参数相同的话,就会替换原来的列。如果第一个参数和原列名参数不同,则会追加新增加一列数据在表后面。具体例子如下:
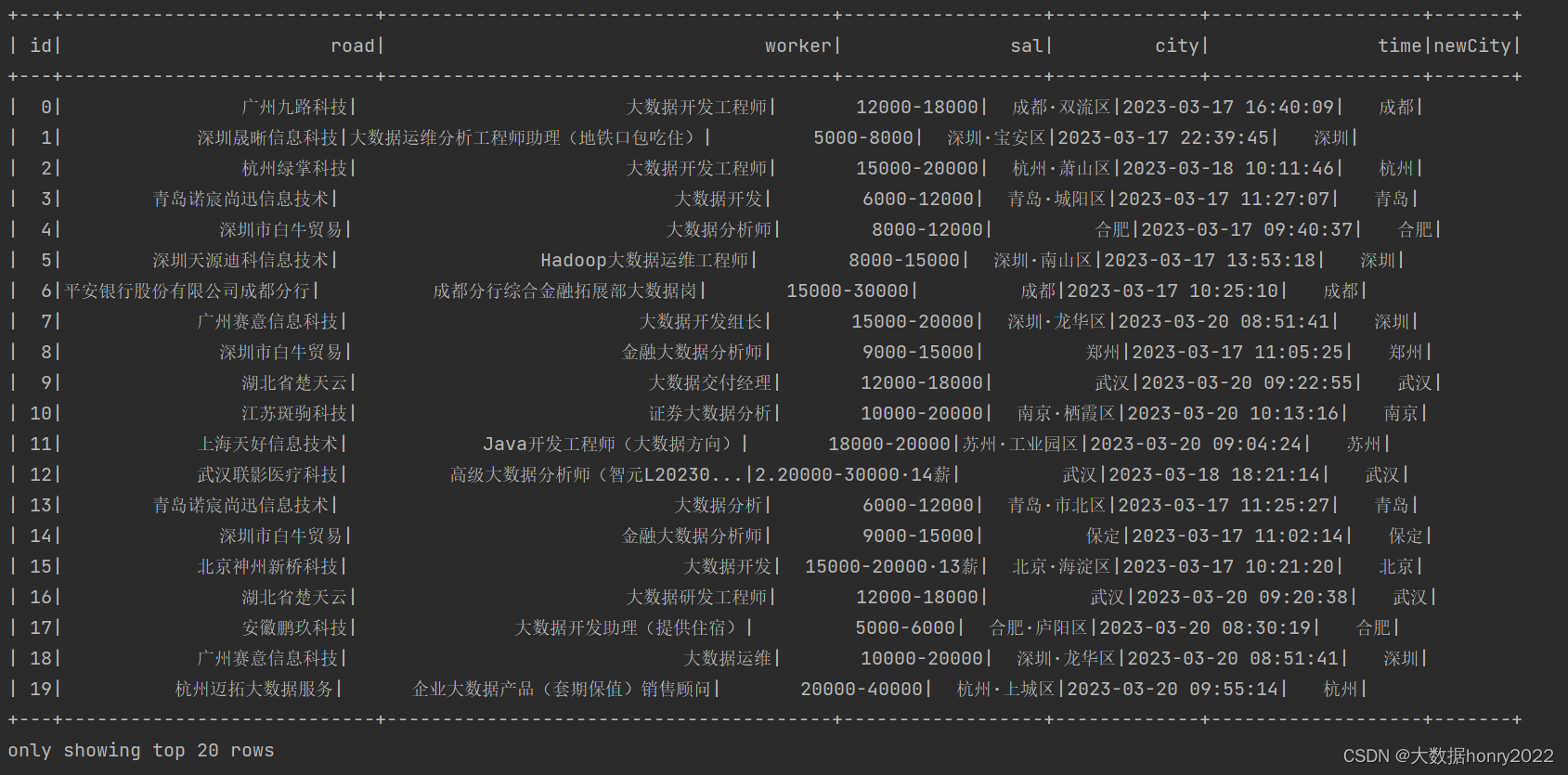
现用withColumn关键字将city字段类似于“成都·双流区” 操作转换成 “成都” ,思路是将city字段数据“·”后面的数据去除,然后替换掉原来列或者新增一列两种情况:
原数据:

情况一(替换原列):传入的第一个参数和原列名相同:
在withColumn的第二个参数传入正则匹配将“·”后面的数据替换成空。但是第一个参数city和原列名city相同,则替换原列的数据:
df.withColumn("city", regexp_replace(col("city"), "·.*", "")).show替换dataframe表原列city的数据:

情况二(追加新列):传入的第一个参数和原列名不同
在withColumn的第二个参数传入正则匹配将“·”后面的数据替换成空。但是第一个参数newCity和原列名city不相同,则在dataframe表后面追加新列newCity:
df.withColumn("newCity", regexp_replace(col("city"), "·.*", "")).showdataframe表末尾追加新列newCity:
总结:
该关键字第二个参数可以对表中的指定的字段进行操作,操作完之后会返回一列数据,这列数据是以替换的形式还是以追加的形式存在,要看第一 个参数列名是否与第二个参数列名是否相同,相同则是替换原表的列数据,不相同则在原表中追加新增列。
这篇关于spark Scala中dataframe的常用关键字:withColumn的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




